아랍어 감성 분석: 실용적인 NLP 전처리 및 모델 구현 가이드

글로벌 디지털 커뮤니케이션 시대에 텍스트 뒤에 숨겨진 감정적 어조를 식별하는 작업인 감성 분석은 비즈니스, 정부 및 연구자에게 매우 중요해졌습니다. 영어와 같은 언어의 감성 분석은 고도로 성숙해진 반면, 아랍어에 이를 적용하는 것은 고유한 언어적 및 기술적 과제를 안겨줍니다.
아랍어는 전 세계적으로 4억 명 이상이 사용하는 언어 중 하나입니다. 그러나 아랍어의 풍부한 형태학적 구조, 양층언어 현상(표준어와 구어의 공존), 복잡한 문자 시스템은 특화된 전처리 및 모델링 전략을 요구합니다.
이 가이드는 아랍어 감성 분석의 종합적인 단계별 가이드를 제공하며, 직면한 과제, 전처리 파이프라인, 클래식 머신러닝 구현(TF-IDF + 로지스틱 회귀), Hugging Face Transformers를 사용하는 현대적인 딥러닝 접근 방식을 자세히 설명합니다.
1. 아랍어 NLP의 언어적 과제
코드를 작성하기 전에 개발자는 왜 아랍어를 표준 서구식 NLP 파이프라인으로 처리할 수 없는지 이해해야 합니다.
- 양층언어 현상(Diglossia): 아랍어는 공식적인 글쓰기, 뉴스, 공식 문서에 사용되는 **현대 표준 아랍어(MSA)**와 소셜 미디어 및 일상 대화에 사용되는 **구어체 방언(Darja/Ammiya)**으로 나뉩니다. 방언(예: 이집트, 레반트, 걸프 방언)은 어휘, 문법 및 감정 표현에서 크게 다릅니다.
- 풍부한 형태학(Rich Morphology): 아랍어는 단어가 패턴을 적용하여 3개 또는 4개의 자음 어근에서 파생되는 어근 기반 언어입니다. 단일 단어에는 대명사, 전치사, 시제를 나타내는 접두사, 접미사 및 접중사가 포함될 수 있습니다(예: وسيكتبونها - “그리고 그들은 그것을 쓸 것이다”).
- 철자 변형(Orthographic Variations): 아랍어 문자는 단어 내 위치에 따라 형태가 바뀌는 경우가 많으며, 사용자는 특정 문자를 혼용하여 사용하는 경우가 많습니다(예:
أ,إ,آ,ا와 같은 알리프(Alif) 변형 또는ى대비ي와 같은 야아(Yaa) 변형). - 모음 기호(Tashkeel): 짧은 모음은 문자 위나 아래에 기호(Fatha, Damma, Kasra 등)로 표시됩니다. 이는 의미를 명확하게 해주지만, 디지털 텍스트에서는 생략되는 경우가 많아 모호성을 유발하거나 불일치하게 추가되어 데이터 희소성을 초래합니다.
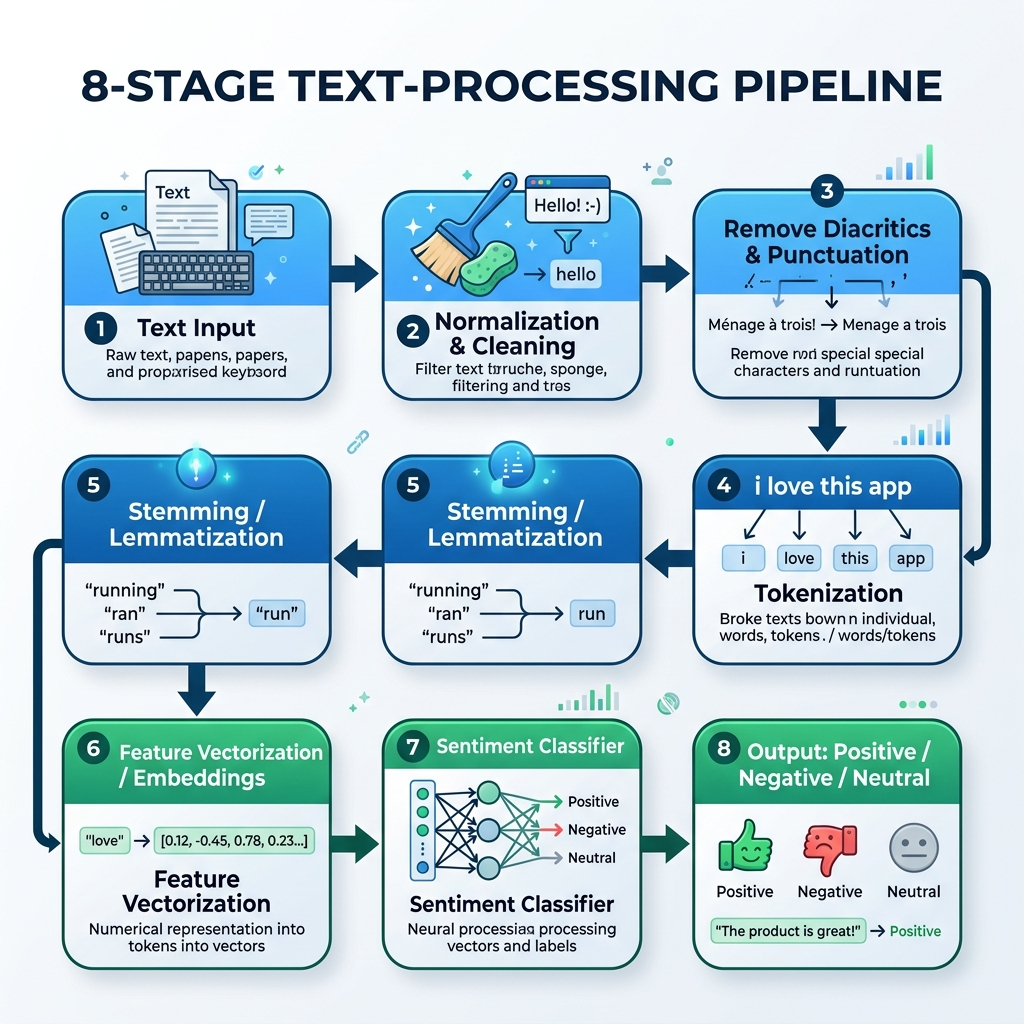
2. 아랍어 NLP 파이프라인
아랍어 텍스트를 처리하려면 텍스트 정규화, 모음 기호 제거, 토큰화, 어간 추출(Stemming), 모델 추론을 처리하는 전용 파이프라인을 구축해야 합니다.
graph TD
A[원시 아랍어 텍스트] --> B[정규화 및 클리닝]
B --> C[모음 기호 및 문장 부호 제거]
C --> D[토큰화]
D --> E[어간 추출 / 표제어 추출]
E --> F[특징 벡터화 / 임베딩]
F --> G[감성 분류기]
G --> H[출력: 긍정 / 부정 / 중립]
3. 단계별 가이드: 클래식 전처리 및 머신러닝 (파이썬)
파이썬, NLTK, scikit-learn을 사용하여 완전한 파이프라인을 구현해 보겠습니다. 사용자 정의 정규화 규칙을 작성하고 아랍어용으로 특별히 설계된 NLTK의 ISRIStemmer를 사용합니다.
1단계: 라이브러리 설치
먼저 필요한 라이브러리가 설치되어 있는지 확인하세요.
pip install nltk scikit-learn
2단계: 전처리 코드 작성
다음은 아랍어 텍스트를 정리, 정규화 및 어간 추출하는 파이썬 코드입니다.
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# 불용어를 아직 다운로드하지 않았다면 다운로드합니다.
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# 아랍어 어간 추출기 초기화
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. 모음 기호 제거 (Tashkeel)
text = re.sub(r'[ً-ْ]', '', text)
# 2. 알리프 모양을 기본 알리프로 정규화
text = re.sub(r'[أإآ]', 'ا', text)
# 3. 야아(Yaa) 및 알리프 마크수라 정규화
text = re.sub(r'ى', 'ي', text)
# 4. 타 마르부타를 하아로 정규화
text = re.sub(r'ة', 'ه', text)
# 5. 아랍어가 아닌 문자 및 문장 부호 제거
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. 여러 개의 공백을 하나로 병합
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# 텍스트 정규화
normalized = normalize_arabic(text)
# 토큰화 및 불용어 제거 후 어간 추출
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# 사용 예시
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("원본:", raw_text)
print("전처리 완료:", preprocess_arabic_text(raw_text))
# 출력: ممتاز سرع نصح جمع عمل مع
3단계: 간단한 분류기 학습
이제 TF-IDF를 사용하여 전처리된 텍스트를 벡터화하고 로지스틱 회귀 모델을 학습합니다.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# 샘플 학습 데이터
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# 레이블: 1 = 긍정, 0 = 부정
train_labels = [1, 0, 1, 0, 1]
# 학습 데이터 전처리
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# 파이프라인 생성: TF-IDF 벡터라이저 + 로지스틱 회귀 분류기
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# 모델 학습
model_pipeline.fit(preprocessed_train, train_labels)
# 새로운 텍스트로 테스트
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"테스트 텍스트: '{test_text}'")
print(f"전처리 완료: '{preprocessed_test}'")
print(f"예측된 감성: {'긍정' if prediction == 1 else '부정'}")
4. 단계별 가이드: 현대적인 트랜스포머 기반 분류 (Hugging Face)
어간 추출 및 TF-IDF는 기본 분류에는 잘 작동하지만, 문맥, 반어법 및 복잡한 방언 변형을 포착하지 못합니다. 최첨단 수준의 결과를 얻으려면 사전 학습된 트랜스포머 모델인 AraBERT 또는 CamelBERT를 사용합니다.
다음은 Hugging Face transformers 라이브러리를 사용하여 단 몇 줄의 코드로 아랍어 텍스트 감성 분석을 실행하는 방법입니다.
1단계: 라이브러리 설치
pip install transformers torch sentencepiece
2단계: 모델 파이프라인 로드
Hugging Face 허브에 호스팅된 고도로 최적화된 CAMeL-Lab/bert-base-arabic-sentiment-msa 모델을 사용합니다.
from transformers import pipeline
# 특화된 아랍어 모델로 감성 분석 파이프라인 초기화
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# 테스트 문장 (MSA 및 구어체 방언)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة على الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"텍스트: {sentence}")
print(f"감성 분석 결과: {label} (신뢰도 {confidence:.2f}%)
")
5. 모델 비교: 기존 머신러닝 vs 트랜스포머
| 기능 | 기존 머신러닝 (TF-IDF + SVM/LR) | 트랜스포머 (AraBERT/CamelBERT) |
|---|---|---|
| 문맥 이해도 | 낮음 (단어를 독립적인 기능으로 처리) | 높음 (단어 순서와 문맥을 이해) |
| 방언 처리 | 취약함 (맞춤형 방언 사전 필요) | 우수함 (복잡한 방언을 자연스럽게 처리) |
| 연산 자원 요구사항 | 매우 낮음 (모든 CPU에서 밀리초 단위로 실행 가능) | 높음 (빠른 추론을 위해 GPU 필요) |
| 필요한 학습 데이터 | 많음 (일반화를 위해 큰 레이블 데이터 필요) | 적음 (사전 학습되어 미세 조정으로 원활히 작동) |
| 어휘 외부 단어 (OOV) | 새로운 단어를 놓칠 위험이 높음 | 위험 최소화 (하위 단어 토큰화 사용) |
6. 결론
아랍어 감성 분석은 빠르게 발전하는 분야입니다. 사용자 정의 전처리(정규화 및 어간 추출)가 포함된 기존 머신러닝 기술은 단순한 작업에 대해 빠르고 비용 효율적인 반면, 현대의 트랜스포머는 정확도와 방언 처리 부문에서 새로운 기준을 제시했습니다.
적절한 언어적 클리닝 규칙과 올바른 모델 아키텍처를 결합하면 아랍 세계의 감정을 포착할 수 있는 강력한 시스템을 구축할 수 있습니다.