Arabic Sentiment Analysis: A Practical NLP Preprocessing and Model Walkthrough

In the era of globalized digital communication, sentiment analysis—the task of identifying the emotional tone behind a body of text—has become crucial for businesses, governments, and researchers. While sentiment analysis is highly mature for languages like English, applying it to Arabic presents a unique set of linguistic and technical challenges.
With over 400 million speakers, Arabic is one of the most widely spoken languages in the world. However, its rich morphological structure, diglossia (coexistence of standard and colloquial forms), and complex writing system require specialized preprocessing and modeling strategies.
This guide provides a comprehensive walkthrough of Arabic sentiment analysis, detailing the challenges, the preprocessing pipeline, a classic Machine Learning implementation (TF-IDF + Logistic Regression), and a modern Deep Learning approach using Hugging Face Transformers.
1. The Linguistic Challenges of Arabic NLP
Before writing code, a developer must understand why Arabic cannot be treated with standard Western NLP pipelines:
- Diglossia: Arabic is split between Modern Standard Arabic (MSA) (used in formal writing, news, and official documents) and Colloquial Dialects (Darja/Ammiya) (used on social media and daily speech). Dialects (e.g., Egyptian, Levantine, Gulf) differ significantly in vocabulary, grammar, and sentiment expressions.
- Rich Morphology: Arabic is a templatic language where words are derived from a three- or four-letter root by applying patterns. A single word can contain prefixes, suffixes, and infixes representing pronouns, prepositions, and tenses (e.g., وسيكتبونها - “and they will write it”).
- Orthographic Variations: Arabic letters often change shapes based on their position, and users frequently use letters interchangeably (e.g., Alif shapes like
أ,إ,آ,اor Yaa shapes likeيvs.ى). - Diacritics (Tashkeel): Short vowels are written as diacritics above or below letters (e.g., Fat-hah, Dammah, Kasrah). While they clarify meaning, they are often omitted in digital text, causing ambiguity, or added inconsistently, causing data sparsity.
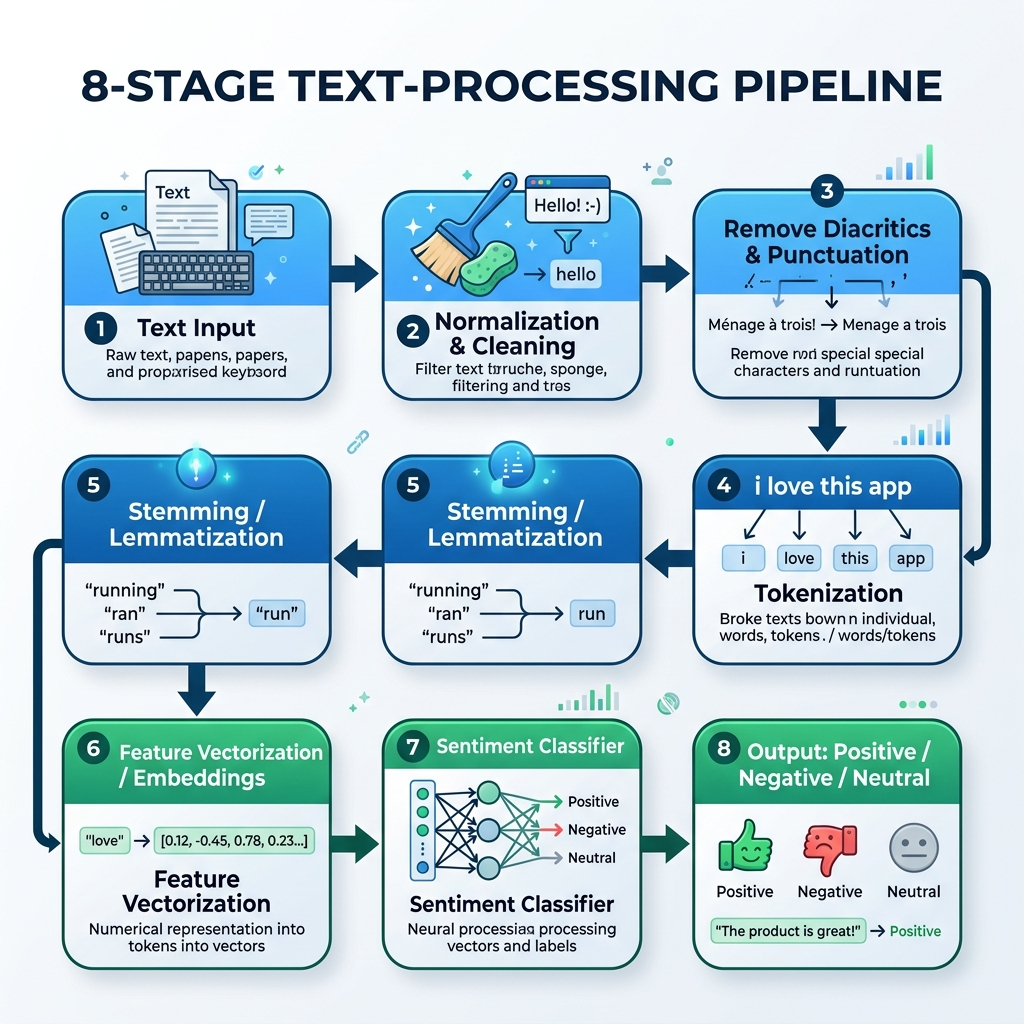
2. The Arabic NLP Pipeline
To process Arabic text, we must build a specialized pipeline that handles normalization, diacritics removal, tokenization, stemming, and model inference:
graph TD
A[Raw Arabic Text] --> B[Normalization & Cleaning]
B --> C[Remove Diacritics & Punctuation]
C --> D[Tokenization]
D --> E[Stemming / Lemmatization]
E --> F[Feature Vectorization / Embeddings]
F --> G[Sentiment Classifier]
G --> H[Output: Positive / Negative / Neutral]
3. Walkthrough: Classic Preprocessing and Machine Learning (Python)
Let’s implement a complete pipeline using Python, NLTK, and scikit-learn. We will write custom normalization rules and use NLTK’s ISRIStemmer (an information retrieval stemmer specifically designed for Arabic).
Step 1: Install Dependencies
First, make sure you have the required libraries installed:
pip install nltk scikit-learn
Step 2: Write the Preprocessing Code
Here is the python code to clean, normalize, and stem Arabic text:
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# Download stopwords if not already done
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# Initialize the Arabic Stemmer
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. Remove diacritics (Tashkeel)
text = re.sub(r'[ً-ْ]', '', text)
# 2. Normalize Alif shapes to bare Alif
text = re.sub(r'[أإآ]', 'ا', text)
# 3. Normalize Yaa and Alif Maqsoora
text = re.sub(r'ى', 'ي', text)
# 4. Normalize Ta Marbuta to Haa
text = re.sub(r'ة', 'ه', text)
# 5. Remove non-Arabic characters and punctuation
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. Collapse multiple whitespaces
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# Normalize text
normalized = normalize_arabic(text)
# Tokenize and remove stopwords, then stem
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# Example Usage
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("Original:", raw_text)
print("Processed:", preprocess_arabic_text(raw_text))
# Output: ممتاز سرع نصح جمع عمل مع
Step 3: Train a Simple Classifier
Now, let’s vectorize our processed text using TF-IDF and train a Logistic Regression model:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# Sample training data
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# Labels: 1 = Positive, 0 = Negative
train_labels = [1, 0, 1, 0, 1]
# Preprocess training data
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# Create pipeline: TF-IDF vectorizer + Logistic Regression classifier
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# Train the model
model_pipeline.fit(preprocessed_train, train_labels)
# Test with new text
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"Test Text: '{test_text}'")
print(f"Preprocessed: '{preprocessed_test}'")
print(f"Predicted Sentiment: {'Positive' if prediction == 1 else 'Negative'}")
4. Walkthrough: Modern Transformer-based Classification (Hugging Face)
While stemming and TF-IDF work well for basic classification, they fail to capture context, sarcasm, and complex dialectal variations. For state-of-the-art results, we use pre-trained Transformers like AraBERT or CamelBERT.
Here is how to use the Hugging Face transformers library to run sentiment analysis on Arabic text in just a few lines of code:
Step 1: Install Dependencies
pip install transformers torch sentencepiece
Step 2: Load the Model Pipeline
We will use the highly optimized model CAMeL-Lab/bert-base-arabic-sentiment-msa hosted on the Hugging Face hub:
from transformers import pipeline
# Initialize the sentiment analysis pipeline with a specialized Arabic model
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# Test sentences (MSA and Dialectal)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة على الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"Text: {sentence}")
print(f"Sentiment: {label} ({confidence:.2f}% confidence)
")
5. Model Comparison: Traditional ML vs. Transformers
| Feature | Traditional ML (TF-IDF + SVM/LR) | Transformers (AraBERT/CamelBERT) |
|---|---|---|
| Contextual Understanding | Low (treats words as independent features) | High (understands word order and context) |
| Dialect Handling | Poor (requires custom dialect dictionaries) | Excellent (handles complex dialects naturally) |
| Compute Requirements | Extremely low (runs on any CPU in milliseconds) | High (requires GPU for fast inference) |
| Training Data Needed | High (needs large labeled sets to generalize) | Low (pre-trained, works well with fine-tuning) |
| Out-of-Vocabulary (OOV) | High risk of missing new words | Minimal risk (uses subword tokenization) |
6. Conclusion
Arabic sentiment analysis is a rapidly evolving field. While traditional machine learning techniques with custom preprocessing (like normalization and stemming) are fast and cost-effective for simple tasks, modern Transformers have set a new benchmark for accuracy and dialect handling.
By combining proper linguistic cleaning rules with the right model architectures, you can build powerful systems capable of unlocking the emotional voice of the Arab world.