Análise de Sentimentos em Árabe: Um Guia Prático de Pré-processamento de PLN e Modelagem

Na era da comunicação digital globalizada, a análise de sentimentos — a tarefa de identificar o tom emocional por trás de um texto — tornou-se crucial para empresas, governos e pesquisadores. Embora a análise de sentimentos seja altamente madura para idiomas como o inglês, aplicá-la ao árabe apresenta um conjunto único de desafios linguísticos e técnicos.
Com mais de 400 milhões de falantes, o árabe é um dos idiomas mais falados no mundo. No entanto, sua rica estrutura morfológica, a diglossia (coexistência de formas padrão e coloquiais) e seu complexo sistema de escrita exigem estratégias especializadas de pré-processamento e modelagem.
Este guia fornece um passo a passo completo da análise de sentimentos em árabe, detalhando os desafios, o pipeline de pré-processamento, uma implementação clássica de Aprendizado de Máquina (TF-IDF + Regressão Logística) e uma abordagem moderna de Aprendizado Profundo usando Transformers do Hugging Face.
1. Os Desafios Linguísticos do PLN em Árabe
Antes de escrever o código, um desenvolvedor deve entender por que o árabe não pode ser tratado com os pipelines de PLN ocidentais padrão:
- Diglossia: O árabe é dividido entre o Árabe Padrão Moderno (APM) (usado em redações formais, notícias e documentos oficiais) e os Dialetos Coloquiais (Darja/Ammiya) (usados em redes sociais e no dia a dia). Os dialetos (por exemplo, egípcio, levantino, do Golfo) diferem significativamente no vocabulário, na gramática e nas expressões de sentimentos.
- Morfologia Rica: O árabe é uma língua baseada em raízes, onde as palavras são derivadas de uma raiz de três ou quatro letras pela aplicação de padrões. Uma única palavra pode conter prefixos, sufixos e infixos que representam pronomes, preposições e tempos verbais (por exemplo, وسيكتبونها - “e eles a escreverão”).
- Variações Ortográficas: As letras árabes costumam mudar de forma com base em sua posição, e os usuários frequentemente usam letras de forma intercambiável (por exemplo, formas de Alif como
أ,إ,آ,اou formas de Yaa comoيem comparação comى). - Diacríticos (Tashkeel): Vogais curtas são escritas como diacríticos acima ou abaixo das letras (por exemplo, Fatha, Damma, Kasra). Embora esclareçam o significado, costumam ser omitidos no texto digital, causando ambiguidade, ou adicionados de forma inconsistente, gerando escassez de dados.
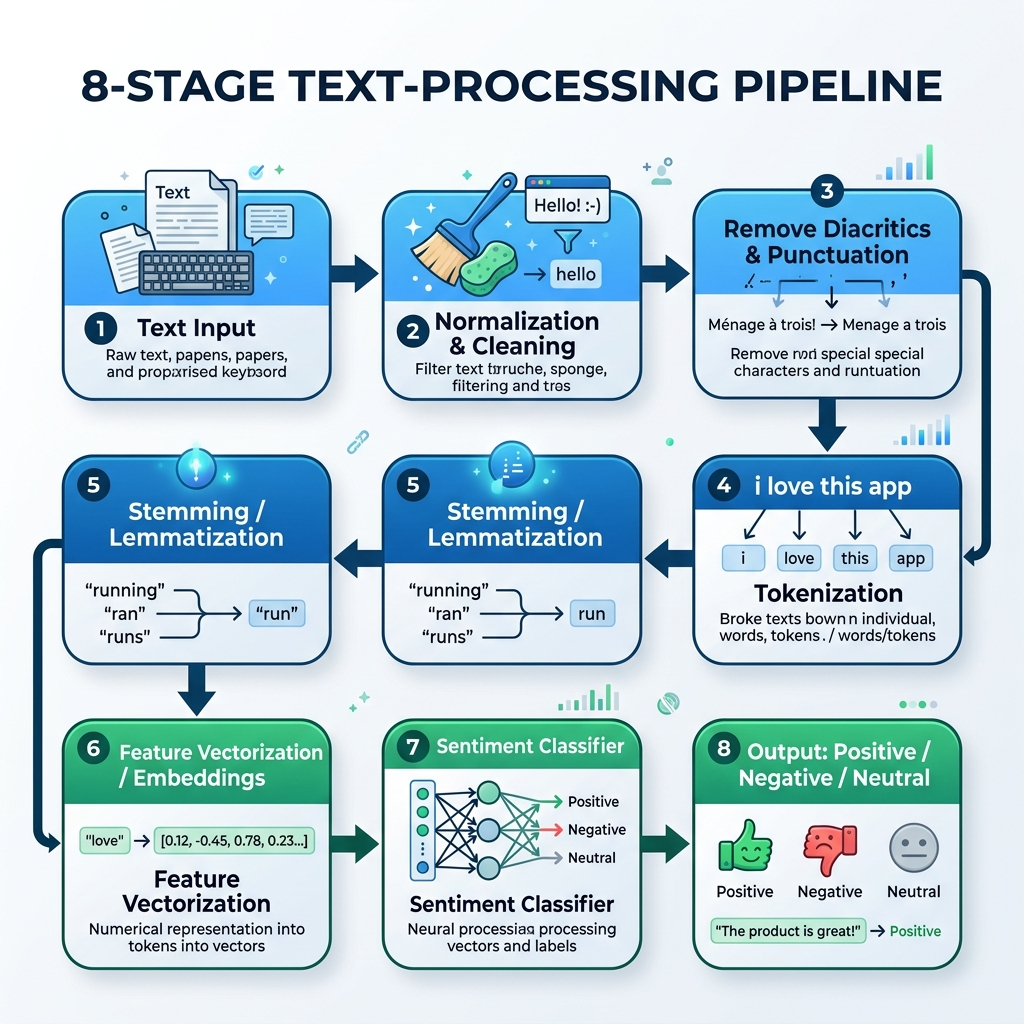
2. O Pipeline de PLN em Árabe
Para processar o texto em árabe, devemos construir um pipeline especializado que lide com a normalização, remoção de diacríticos, tokenização, stemming (extração de radicais) e inferência do modelo:
graph TD
A[Texto Arabe Bruto] --> B[Normalizacao e Limpeza]
B --> C[Remover Diacriticos e Pontuacao]
C --> D[Tokenizacao]
D --> E[Stemming / Lematizacao]
E --> F[Vetorizacao de Recursos / Embeddings]
F --> G[Classificador de Sentimento]
G --> H[Resultado: Positivo / Negativo / Neutral]
3. Walkthrough: Pré-processamento Clássico e Aprendizado de Máquina (Python)
Vamos implementar um pipeline completo usando Python, NLTK e scikit-learn. Escreveremos regras de normalização personalizadas e usaremos o ISRIStemmer do NLTK (um extrator de radicais para recuperação de informações projetado especificamente para o árabe).
Passo 1: Instalar Dependências
Primeiro, verifique se você tem as bibliotecas necessárias instaladas:
pip install nltk scikit-learn
Passo 2: Escrever o Código de Pré-processamento
Aqui está o código Python para limpar, normalizar e extrair radicais de textos em árabe:
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# Baixe as stopwords se ainda nao o fez
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# Inicializa o Stemmer Arabe
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. Remove diacríticos (Tashkeel)
text = re.sub(r'[ً-ْ]', '', text)
# 2. Normaliza formas de Alif para um Alif simples
text = re.sub(r'[أإآ]', 'ا', text)
# 3. Normaliza Yaa e Alif Maqsoora
text = re.sub(r'ى', 'ي', text)
# 4. Normaliza Ta Marbuta para Haa
text = re.sub(r'ة', 'ه', text)
# 5. Remove caracteres não árabes e pontuação
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. Elimina espaços múltiplos
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# Normaliza o texto
normalized = normalize_arabic(text)
# Tokeniza, remove stopwords e extrai radicais
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# Exemplo de Uso
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("Original:", raw_text)
print("Processado:", preprocess_arabic_text(raw_text))
# Output: ممتاز سرع نصح جمع عمل مع
Passo 3: Treinar um Classificador Simples
Agora, vamos vetorizar nosso texto processado usando TF-IDF e treinar um modelo de Regressão Logística:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# Dados de treinamento de amostra
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# Rótulos: 1 = Positivo, 0 = Negativo
train_labels = [1, 0, 1, 0, 1]
# Pré-processa dados de treinamento
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# Cria o pipeline: vetorizador TF-IDF + classificador de Regressão Logística
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# Treina o modelo
model_pipeline.fit(preprocessed_train, train_labels)
# Testa com um novo texto
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"Texto de teste: '{test_text}'")
print(f"Pré-processado: '{preprocessed_test}'")
print(f"Sentimento previsto: {'Positivo' if prediction == 1 else 'Negativo'}")
4. Walkthrough: Classificação Moderna Baseada em Transformers (Hugging Face)
Embora a extração de radicais e o TF-IDF funcionem bem para a classificação básica, eles não conseguem capturar o contexto, o sarcasmo e as variações dialetais complexas. Para resultados de ponta, usamos Transformers pré-treinados como AraBERT ou CamelBERT.
Veja como usar a biblioteca transformers do Hugging Face para executar análise de sentimentos em texto árabe em apenas algumas linhas de código:
Passo 1: Instalar Dependências
pip install transformers torch sentencepiece
Passo 2: Carregar o Pipeline do Modelo
Usaremos o modelo altamente otimizado CAMeL-Lab/bert-base-arabic-sentiment-msa hospedado no hub do Hugging Face:
from transformers import pipeline
# Inicializa o pipeline de analise de sentimento com um modelo arabe especializado
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# Frases de teste (APM e dialeto)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة على الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"Texto: {sentence}")
print(f"Sentimento: {label} ({confidence:.2f}% de confiança)
")
5. Comparação de Modelos: Aprendizado de Máquina Tradicional vs. Transformers
| Recurso | ML Tradicional (TF-IDF + SVM/LR) | Transformers (AraBERT/CamelBERT) |
|---|---|---|
| Compreensão Contextual | Baixa (trata palavras como recursos independentes) | Alta (compreende a ordem das palavras e o contexto) |
| Tratamento de Dialetos | Ruim (requer dicionários de dialetos personalizados) | Excelente (trata dialetos complexos naturalmente) |
| Requisitos de Computação | Extremamente baixos (executado em qualquer CPU em milissegundos) | Altos (requer GPU para inferência rápida) |
| Dados de Treinamento Necessários | Altos (precisa de grandes conjuntos rotulados para generalizar) | Baixos (pré-treinado, funciona bem com ajuste fino) |
| Fora do Vocabulário (OOV) | Alto risco de perder palavras novas | Risco mínimo (usa tokenização de subpalavras) |
6. Conclusão
Análise de sentimentos em árabe é uma área em rápida evolução. Embora as técnicas tradicionais de aprendizado de máquina com pré-processamento personalizado (como normalização e stemming) sejam rápidas e econômicas para tarefas simples, os Transformers modernos estabeleceram um novo padrão de precisão e tratamento de dialetos.
Ao combinar regras adequadas de limpeza linguística com as arquiteturas de modelo corretas, você pode construir sistemas poderosos capazes de desvendar a voz emocional do mundo árabe.