Arapça Duygu Analizi: Pratik Bir NLP Ön İşleme ve Model Rehberi

Küreselleşen dijital iletişim çağında, bir metnin arkasındaki duygusal tonu belirleme görevi olan duygu analizi; işletmeler, hükümetler ve araştırmacılar için kritik bir hale geldi. Duygu analizi İngilizce gibi diller için son derece olgunlaşmış olsa da, bunu Arapçaya uygulamak benzersiz dilsel ve teknik zorluklar sunar.
400 milyondan fazla konuşanı olan Arapça, dünyada en yaygın konuşulan dillerden biridir. Ancak zengin morfolojik yapısı, diglossia (standart ve konuşma dillerinin bir arada bulunması) ve karmaşık yazı sistemi; özel ön işleme ve modelleme stratejileri gerektirir.
Bu kılavuz, Arapça duygu analizine yönelik kapsamlı bir yol gösterici sunarak zorlukları, ön işleme hattını, klasik bir Makine Öğrenimi uygulamasını (TF-IDF + Lojistik Regresyon) ve Hugging Face Transformers kullanan modern bir Derin Öğrenme yaklaşımını detaylandırmaktadır.
1. Arapça NLP’nin Dilsel Zorlukları
Kod yazmadan önce, bir geliştirici Arapçanın neden standart Batı NLP hatlarıyla işlenemeyeceğini anlamalıdır:
- Diglossia (İki Dillilik): Arapça, Modern Standart Arapça (MSA) (resmi yazı, haberler ve resmi belgelerde kullanılır) ve Konuşma Lehçeleri (Darja/Ammiya) (sosyal medyada ve günlük konuşmalarda kullanılır) olarak ikiye ayrılır. Lehçeler (örneğin Mısır, Levant, Körfez) kelime dağarcığı, dil bilgisi ve duygu ifadelerinde önemli ölçüde farklılık gösterir.
- Zengin Morfoloji: Arapça, kelimelerin belirli kalıplar uygulanarak üç veya dört harfli bir kökten türetildiği kök tabanlı bir dildir. Tek bir kelime; zamirleri, edatları ve zamanları temsil eden önekler, sonekler ve iç ekler içerebilir (örneğin وسيكتبونها - “ve onu yazacaklar”).
- Yazım Farklılıkları: Arapça harfler genellikle kelimedeki konumlarına göre şekil değiştirir ve kullanıcılar sıklıkla bazı harfleri birbirinin yerine kullanır (örneğin
أ,إ,آ,اgibi Elif biçimleri veyaىyerineيgibi Yaa biçimleri). - Harekeler (Diacritics): Kısa ünlüler, harflerin üstüne veya altına hareke olarak yazılır (Fetha, Damma, Kasra gibi). Anlamı netleştirseler de, dijital metinlerde genellikle ihmal edilirler ve bu da belirsizliğe yol açar ya da tutarsız eklenerek veri seyrekliğine neden olurlar.
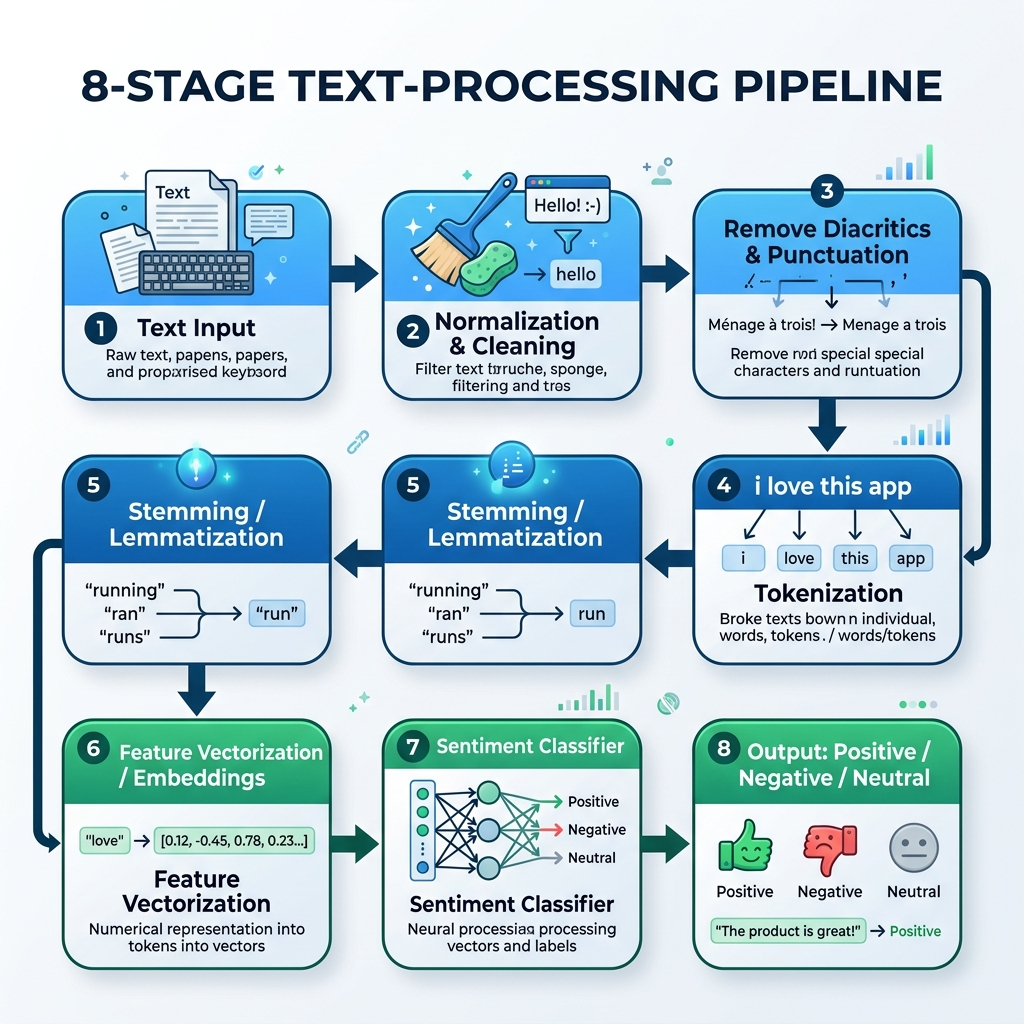
2. Arapça NLP İşlem Hattı
Arapça metni işlemek için normalleştirme, harekelerin kaldırılması, belirteçlere ayırma (tokenization), kök bulma (stemming) ve model çıkarımını yöneten özel bir hat oluşturmalıyız:
graph TD
A[Ham Arapça Metin] --> B[Normalleştirme ve Temizlik]
B --> C[Harekeleri ve Noktalamayı Kaldır]
C --> D[Tokenizasyon]
D --> E[Kök Bulma / Lemmatizasyon]
E --> F[Özellik Vektörleştirme / Gömme]
F --> G[Duygu Sınıflandırıcı]
G --> H[Çıktı: Pozitif / Negatif / Nötr]
3. Rehber: Klasik Ön İşleme ve Makine Öğrenimi (Python)
Python, NLTK ve scikit-learn kullanarak eksiksiz bir hat uygulayalım. Özel normalleştirme kuralları yazacağız ve NLTK’nin ISRIStemmer aracını (Arapça için özel olarak tasarlanmış bir bilgi erişim kök bulucu) kullanacağız.
Adım 1: Bağımlılıkları Yükleyin
İlk olarak, gerekli kitaplıkların kurulu olduğundan emin olun:
pip install nltk scikit-learn
Adım 2: Ön İşleme Kodunu Yazın
İşte Arapça metni temizlemek, normalleştirmek ve köklerine ayırmak için Python kodu:
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# Henüz yapmadıysanız etkisiz kelimeleri (stopwords) indirin
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# Arapça Kök Bulucuyu başlat
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. Harekeleri kaldır (Tashkeel)
text = re.sub(r'[ً-ْ]', '', text)
# 2. Elif biçimlerini yalın Elif'e normalleştir
text = re.sub(r'[أإآ]', 'ا', text)
# 3. Yaa ve Alif Maqsoora'yı normalleştir
text = re.sub(r'ى', 'ي', text)
# 4. Ta Marbuta'yı Haa'ya normalleştir
text = re.sub(r'ة', 'ه', text)
# 5. Arapça olmayan karakterleri ve noktalamayı kaldır
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. Birden fazla boşluğu temizle
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# Metni normalleştir
normalized = normalize_arabic(text)
# Kelimelere ayır, etkisiz kelimeleri kaldır ve kökünü bul
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# Örnek Kullanım
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("Orijinal:", raw_text)
print("İşlenmiş:", preprocess_arabic_text(raw_text))
# Çıktı: ممتاز سرع نصح جمع عمل مع
Adım 3: Basit Bir Sınıflandırıcı Eğitin
Şimdi, işlenmiş metnimizi TF-IDF kullanarak vektörleştirelim ve bir Lojistik Regresyon modeli eğitelim:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# Örnek eğitim verileri
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# Etiketler: 1 = Pozitif, 0 = Negatif
train_labels = [1, 0, 1, 0, 1]
# Eğitim verilerini ön işlemeden geçir
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# İşlem hattını oluştur: TF-IDF vektörleştirici + Lojistik Regresyon sınıflandırıcı
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# Modeli eğit
model_pipeline.fit(preprocessed_train, train_labels)
# Yeni metinle test et
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"Test Metni: '{test_text}'")
print(f"Ön İşlenmiş: '{preprocessed_test}'")
print(f"Tahmin Edilen Duygu: {'Pozitif' if prediction == 1 else 'Negatif'}")
4. Rehber: Modern Transformer Tabanlı Sınıflandırma (Hugging Face)
Kök bulma ve TF-IDF temel sınıflandırma için iyi çalışsa da bağlamı, alaycılığı ve karmaşık lehçe farklılıklarını yakalayamaz. Son teknoloji sonuçlar için AraBERT veya CamelBERT gibi önceden eğitilmiş Transformer modelleri kullanırız.
Arapça metin üzerinde sadece birkaç satır kodla duygu analizi yapmak için Hugging Face transformers kitaplığını şu şekilde kullanabilirsiniz:
Adım 1: Bağımlılıkları Yükleyin
pip install transformers torch sentencepiece
Adım 2: Model İşlem Hattını Yükleyin
Hugging Face hub’ında barındırılan, yüksek derecede optimize edilmiş CAMeL-Lab/bert-base-arabic-sentiment-msa modelini kullanacağız:
from transformers import pipeline
# Özel bir Arapça modelle duygu analizi işlem hattını başlatın
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# Test cümleleri (MSA ve Lehçe)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة على الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"Metin: {sentence}")
print(f"Duygu: {label} ({confidence:.2f}% güvenle)
")
5. Model Karşılaştırması: Geleneksel Makine Öğrenimi vs. Transformers
| Özellik | Geleneksel ML (TF-IDF + SVM/LR) | Transformers (AraBERT/CamelBERT) |
|---|---|---|
| Bağlamsal Anlama | Düşük (kelimeleri bağımsız özellikler olarak ele alır) | Yüksek (kelime sırasını ve bağlamı anlar) |
| Lehçe Yönetimi | Zayıf (özel lehçe sözlükleri gerektirir) | Mükemmel (karmaşık lehçeleri doğal olarak yönetir) |
| Hesaplama Gereksinimleri | Son derece düşük (milisaniyeler içinde herhangi bir CPU’da çalışır) | Yüksek (hızlı çıkarım için GPU gerektirir) |
| Eğitim Verisi İhtiyacı | Yüksek (genellemek için büyük etiketli kümelere ihtiyaç duyar) | Düşük (önceden eğitilmiştir, ince ayar ile iyi çalışır) |
| Kelime Haznesi Dışı (OOV) | Yeni kelimeleri kaçırma riski yüksek | Minimum risk (alt kelime belirteçleştirmesi kullanır) |
6. Sonuç
Arapça duygu analizi hızla gelişen bir alandır. Normalleştirme ve kök bulma gibi özel ön işlemeli geleneksel makine öğrenimi teknikleri basit görevler için hızlı ve maliyet etkin olsa da, modern Transformer modelleri doğruluk ve lehçe işleme konusunda yeni bir standart belirlemiştir.
Doğru dilsel temizleme kurallarını doğru model mimarileriyle birleştirerek, Arap dünyasının duygusal sesini ortaya çıkarabilecek güçlü sistemler oluşturabilirsiniz.
Ghaznix Blog’unda yapay zeka ve NLP hakkında daha fazla bilgi edinin →