Arabische Sentiment-Analyse: Ein praktischer NLP-Vorverarbeitungs- und Modell-Walkthrough

Im Zeitalter der globalisierten digitalen Kommunikation ist die Sentiment-Analyse – die Aufgabe, den emotionalen Ton hinter einem Textkörper zu identifizieren – für Unternehmen, Regierungen und Forscher von entscheidender Bedeutung geworden. Während die Sentiment-Analyse für Sprachen wie Englisch hochentwickelt ist, stellt die Anwendung auf das Arabische eine einzigartige Reihe von linguistischen und technischen Herausforderungen dar.
Mit über 400 Millionen Spregern ist Arabisch eine der am weitesten verbreiteten Sprachen der Welt. Seine reiche morphologische Struktur, Diglossie (Koexistenz von Standard- und Umgangsformen) und sein komplexes Schriftsystem erfordern jedoch spezialisierte Vorverarbeitungs- und Modellierungsstrategien.
Dieser Leitfaden bietet eine umfassende Anleitung zur arabischen Sentiment-Analyse und beschreibt die Herausforderungen, die Vorverarbeitungspipeline, eine klassische Implementierung des maschinellen Lernens (TF-IDF + logistische Regression) und einen modernen Deep-Learning-Ansatz unter Verwendung von Hugging Face Transformers.
1. Die linguistischen Herausforderungen der arabischen NLP
Bevor Code geschrieben wird, muss ein Entwickler verstehen, warum Arabisch nicht mit standardmäßigen westlichen NLP-Pipelines verarbeitet werden kann:
- Diglossie: Arabisch ist unterteilt in Modernes Standardarabisch (MSA) (verwendet in formellen Texten, Nachrichten und offiziellen Dokumenten) und Umgangssprachliche Dialekte (Darja/Ammiya) (verwendet in sozialen Medien und der Alltagssprache). Dialekte (z. B. ägyptisch, levantinisch, Golf-Arabisch) unterscheiden sich erheblich in Wortschatz, Grammatik und Gefühlsausdrücken.
- Reiche Morphologie: Arabisch ist eine wurzelbasierte Sprache, bei der Wörter von einer drei- oder vierbuchstabigen Wurzel abgeleitet werden, indem Muster angewendet werden. Ein einzelnes Wort kann Präfixe, Suffixe und Infixe enthalten, die Pronomen, Präpositionen und Zeitformen darstellen (z. B. وسيكتبونها - „und sie werden es schreiben“).
- Orthografische Variationen: Arabische Buchstaben ändern oft ihre Form je nach ihrer Position, und Benutzer verwenden Buchstaben häufig austauschbar (z. B. Alif-Formen wie
أ,إ,آ,اoder Yaa-Formen wieيim Vergleich zuى). - Diakritika (Tashkeel): Kurze Vokale werden als Diakritika über oder unter Buchstaben geschrieben (z. B. Fatha, Damma, Kasra). Obwohl sie die Bedeutung verdeutlichen, werden sie in digitalem Text oft weggelassen, was zu Ambiguität führt, oder uneinheitlich hinzugefügt, was zu spärlichen Daten führt.
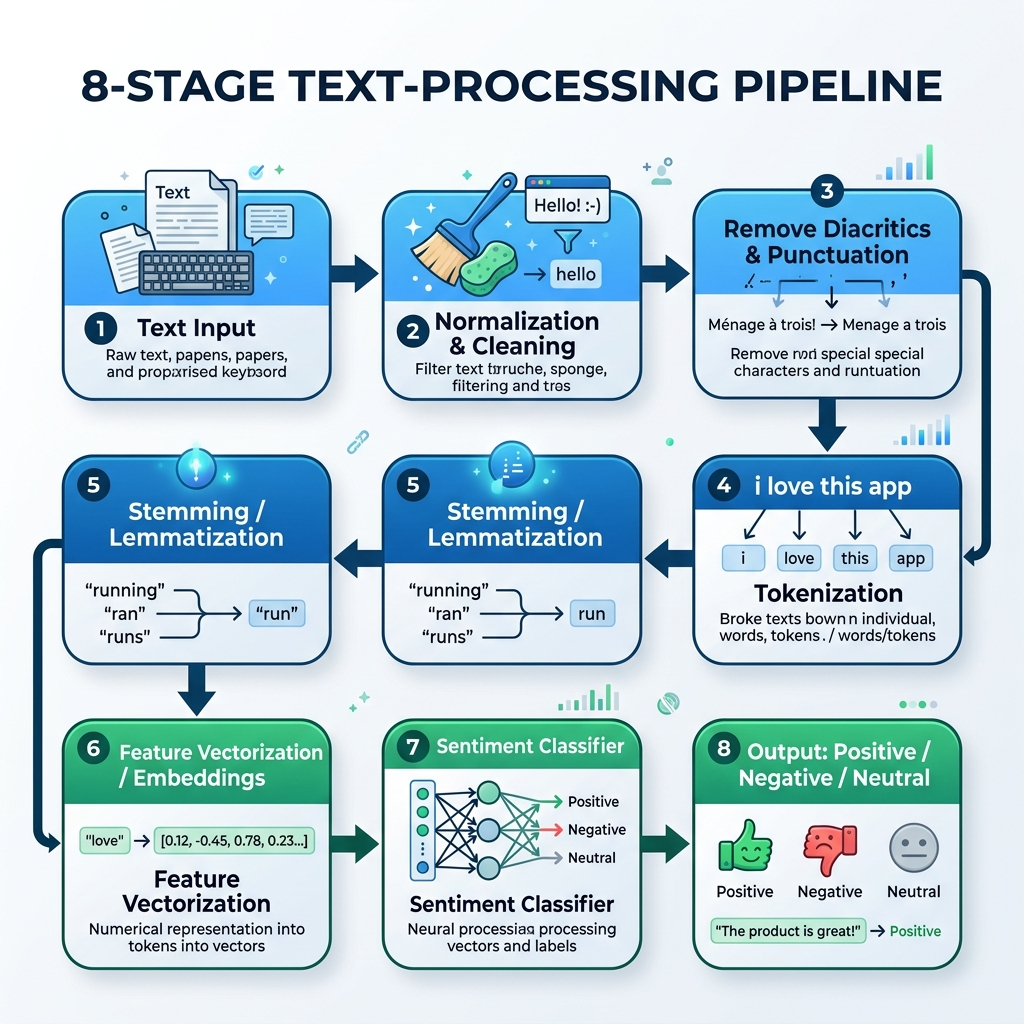
2. Die arabische NLP-Pipeline
Um arabischen Text zu verarbeiten, müssen wir eine spezialisierte Pipeline aufbauen, die Normalisierung, Entfernung von Diakritika, Tokenisierung, Stemming und Modellinferenz handhabt:
graph TD
A[Roher arabischer Text] --> B[Normalisierung & Bereinigung]
B --> C[Diakritika & Interpunktion entfernen]
C --> D[Tokenisierung]
D --> E[Stemming / Lemmatisierung]
E --> F[Vektorisierung / Einbettungen]
F --> G[Sentiment-Klassifikator]
G --> H[Ausgabe: Positiv / Negativ / Neutral]
3. Walkthrough: Klassische Vorverarbeitung und maschinelles Lernen (Python)
Lassen Sie uns eine vollständige Pipeline mit Python, NLTK und scikit-learn implementieren. Wir werden benutzerdefinierte Normalisierungsregeln schreiben und den ISRIStemmer von NLTK verwenden (ein speziell für Arabisch entwickelter Stemmer für Information Retrieval).
Schritt 1: Abhängigkeiten installieren
Stellen Sie zunächst sicher, dass die erforderlichen Bibliotheken installiert sind:
pip install nltk scikit-learn
Schritt 2: Vorverarbeitungscode schreiben
Hier ist der Python-Code zum Bereinigen, Normalisieren und Stemmen von arabischem Text:
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# Stoppwörter herunterladen, falls noch nicht geschehen
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# Den arabischen Stemmer initialisieren
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. Diakritika entfernen (Tashkeel)
text = re.sub(r'[ً-ْ]', '', text)
# 2. Alif-Formen zu einfachem Alif normalisieren
text = re.sub(r'[أإآ]', 'ا', text)
# 3. Yaa und Alif Maqsoora normalisieren
text = re.sub(r'ى', 'ي', text)
# 4. Ta Marbuta zu Haa normalisieren
text = re.sub(r'ة', 'ه', text)
# 5. Nicht-arabische Zeichen und Interpunktion entfernen
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. Mehrfache Leerzeichen reduzieren
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# Text normalisieren
normalized = normalize_arabic(text)
# Tokenisieren, Stoppwörter entfernen und Stemming durchführen
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# Beispiel für die Verwendung
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("Original:", raw_text)
print("Verarbeitet:", preprocess_arabic_text(raw_text))
# Ausgabe: ممتاز سرع نصح جمع عمل مع
Schritt 3: Einen einfachen Klassifikator trainieren
Lassen Sie uns nun unseren verarbeiteten Text mithilfe von TF-IDF vektorisieren und ein logistisches Regressionsmodell trainieren:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# Beispiel-Trainingsdaten
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# Labels: 1 = Positiv, 0 = Negativ
train_labels = [1, 0, 1, 0, 1]
# Trainingsdaten vorverarbeiten
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# Pipeline erstellen: TF-IDF-Vektorisierer + Logistischer Regressionsklassifikator
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# Das Modell trainieren
model_pipeline.fit(preprocessed_train, train_labels)
# Mit neuem Text testen
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"Testtext: '{test_text}'")
print(f"Vorverarbeitet: '{preprocessed_test}'")
print(f"Vorhergesagtes Sentiment: {'Positiv' if prediction == 1 else 'Negativ'}")
4. Walkthrough: Moderne Transformer-basierte Klassifizierung (Hugging Face)
Während Stemming und TF-IDF für eine einfache Klassifizierung gut funktionieren, können sie Kontext, Sarkasmus und komplexe dialektale Variationen nicht erfassen. Für modernste Ergebnisse verwenden wir vortrainierte Transformer wie AraBERT oder CamelBERT.
Hier erfahren Sie, wie Sie die Hugging Face-Bibliothek transformers verwenden, um eine Sentiment-Analyse für arabischen Text in nur wenigen Codezeilen auszuführen:
Schritt 1: Abhängigkeiten installieren
pip install transformers torch sentencepiece
Schritt 2: Die Modell-Pipeline laden
Wir verwenden das hochoptimierte Modell CAMeL-Lab/bert-base-arabic-sentiment-msa, das auf dem Hugging Face Hub gehostet wird:
from transformers import pipeline
# Sentiment-Analyse-Pipeline mit einem speziellen arabischen Modell initialisieren
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# Testsaetze (MSA und Dialekt)
sentences = [
"أنا سعيد جداً باستخدام هذاالمنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة على الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"Text: {sentence}")
print(f"Sentiment: {label} ({confidence:.2f}% Konfidenz)
")
5. Modellvergleich: Traditionelles ML vs. Transformer
| Merkmal | Traditionelles ML (TF-IDF + SVM/LR) | Transformer (AraBERT/CamelBERT) |
|---|---|---|
| Kontextuelles Verständnis | Niedrig (behandelt Wörter als unabhängige Merkmale) | Hoch (versteht Wortreihenfolge und Kontext) |
| Dialekthandhabung | Schlecht (erfordert benutzerdefinierte Dialekt-Wörterbücher) | Exzellent (behandelt komplexe Dialekte naturgemäß) |
| Rechenanforderungen | Extrem niedrig (läuft auf jeder CPU in Millisekunden) | Hoch (erfordert GPU für schnelle Inferenz) |
| Benötigte Trainingsdaten | Hoch (benötigt große beschriftete Datensätze zur Generalisierung) | Niedrig (vortrainiert, funktioniert gut mit Feinabstimmung) |
| Out-of-Vocabulary (OOV) | Hohes Risiko, neue Wörter zu verpassen | Minimales Risiko (verwendet Subwort-Tokenisierung) |
6. Fazit
Die arabische Sentiment-Analyse ist ein sich schnell entwickelndes Feld. Während traditionelle Techniken des maschinellen Lernens mit benutzerdefinierter Vorverarbeitung (wie Normalisierung und Stemming) für einfache Aufgaben schnell und kostengünstig sind, haben moderne Transformer neue Maßstäbe für Genauigkeit und Dialekthandhabung gesetzt.
Durch die Kombination geeigneter linguistischer Bereinigungsregeln mit den richtigen Modellarchitekturen können Sie leistungsstarke Systeme aufbauen, die die emotionale Stimme der arabischen Welt erschließen.
Entdecken Sie weitere Erkenntnisse zu KI und NLP im Ghaznix-Blog →