Análisis de Sentimiento en Árabe: Una Guía Práctica de Preprocesamiento NLP y Modelado

En la era de la comunicación digital globalizada, el análisis de sentimiento (la tarea de identificar el tono emocional detrás de un texto) se ha vuelto crucial para empresas, gobiernos e investigadores. Aunque el análisis de sentimiento está muy maduro para idiomas como el inglés, aplicarlo al árabe presenta un conjunto único de desafíos lingüísticos y técnicos.
Con más de 400 millones de hablantes, el árabe es uno de los idiomas más hablados del mundo. Sin embargo, su rica estructura morfológica, la diglosia (coexistencia de formas estándar y coloquiales) y su complejo sistema de escritura requieren estrategias especializadas de preprocesamiento y modelado.
Esta guía proporciona un recorrido completo del análisis de sentimiento en árabe, detallando los desafíos, el flujo de preprocesamiento, una implementación clásica de aprendizaje automático (TF-IDF + Regresión Logística) y un enfoque moderno de aprendizaje profundo utilizando Transformers de Hugging Face.
1. Los Desafíos Lingüísticos del NLP en Árabe
Antes de escribir código, un desarrollador debe comprender por qué el árabe no se puede tratar con los flujos de trabajo de NLP occidentales estándar:
- Diglosia: El árabe se divide entre el Árabe Estándar Moderno (MSA) (utilizado en redacción formal, noticias y documentos oficiales) y los Dialectos Coloquiales (Darja/Ammiya) (utilizados en redes sociales y el habla diaria). Los dialectos (por ejemplo, egipcio, levantino, del Golfo) difieren significativamente en vocabulario, gramática y expresiones de sentimiento.
- Morfología Rica: El árabe es un idioma de raíces donde las palabras se derivan de una raíz de tres o cuatro letras mediante la aplicación de patrones. Una sola palabra puede contener prefijos, sufijos e infijos que representan pronombres, preposiciones y tiempos verbales (por ejemplo, وسيكتبونها - “y ellos lo escribirán”).
- Variaciones Ortográficas: Las letras árabes a menudo cambian de forma según su posición, y los usuarios con frecuencia usan letras de manera intercambiable (por ejemplo, formas de Alif como
أ,إ,آ,اo formas de Yaa comoيfrente aى). - Diacríticos (Tashkeel): Las vocales cortas se escriben como diacríticos arriba o abajo de las letras (por ejemplo, Fatha, Damma, Kasra). Aunque aclaran el significado, a menudo se omiten en el texto digital, lo que genera ambigüedad, o se agregan de manera inconsistente, lo que provoca dispersión de datos.
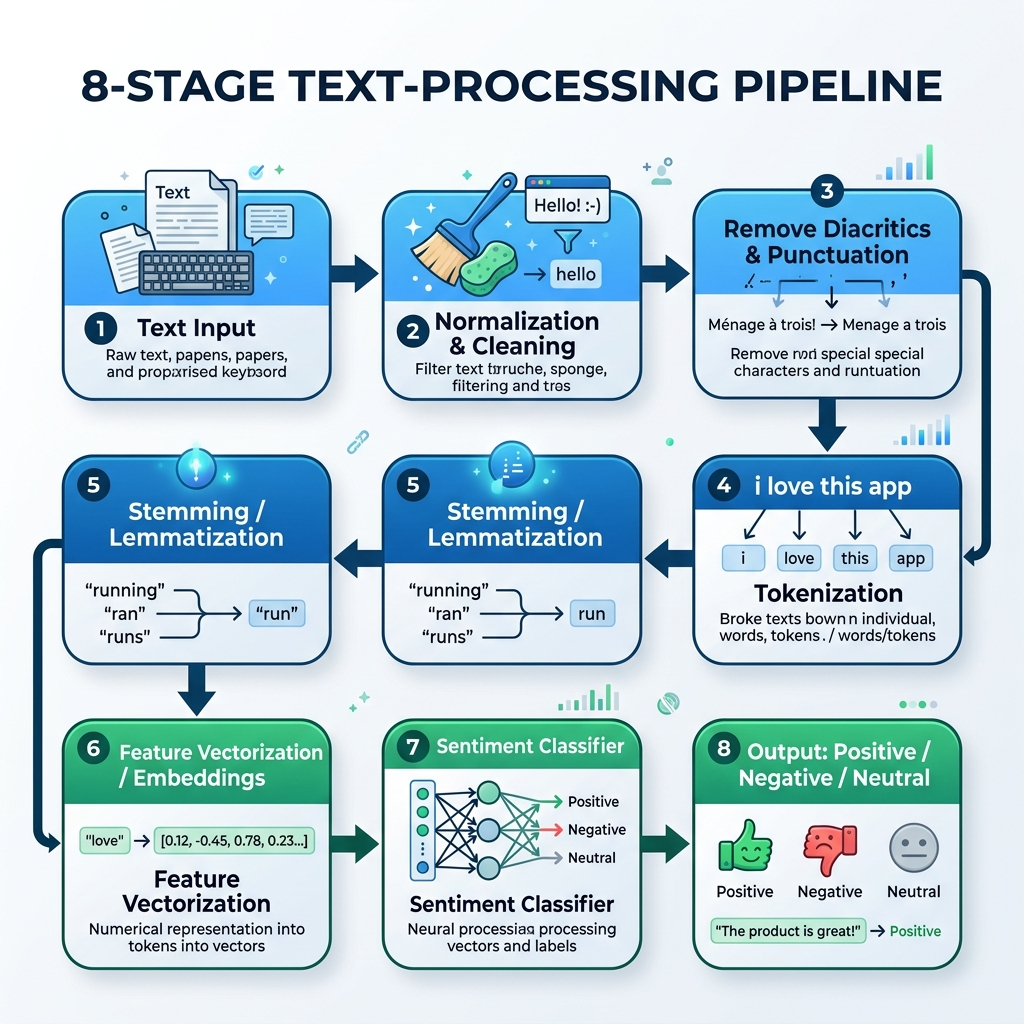
2. El Flujo de Trabajo de NLP en Árabe
Para procesar texto en árabe, debemos construir un flujo especializado que maneje la normalización, la eliminación de diacríticos, la tokenización, el stemming (extracción de raíces) e la inferencia del modelo:
graph TD
A[Texto Arabe Neto] --> B[Normalizacion y Limpieza]
B --> C[Eliminar Diacriticos y Puntuacion]
C --> D[Tokenizacion]
D --> E[Stemming / Lematizacion]
E --> F[Vectorizacion de Caracteristicas / Embeddings]
F --> G[Clasificador de Sentimiento]
G --> H[Resultado: Positivo / Negativo / Neutral]
3. Walkthrough: Preprocesamiento Clásico y Aprendizaje Automático (Python)
Implementemos un flujo completo usando Python, NLTK y scikit-learn. Escribiremos reglas de normalización personalizadas y usaremos el ISRIStemmer de NLTK (un extractor de raíces diseñado específicamente para el árabe).
Paso 1: Instalar Dependencias
Primero, asegúrese de tener instaladas las librerías requeridas:
pip install nltk scikit-learn
Paso 2: Escribir el Código de Preprocesamiento
Aquí está el código Python para limpiar, normalizar y extraer raíces de texto en árabe:
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# Descarga las palabras de parada si no lo has hecho ya
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# Inicializa el Stemmer Arabe
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. Elimina diacríticos (Tashkeel)
text = re.sub(r'[ً-ْ]', '', text)
# 2. Normaliza formas de Alif a un Alif simple
text = re.sub(r'[أإآ]', 'ا', text)
# 3. Normaliza Yaa y Alif Maqsoora
text = re.sub(r'ى', 'ي', text)
# 4. Normaliza Ta Marbuta a Haa
text = re.sub(r'ة', 'ه', text)
# 5. Elimina caracteres no árabes y puntuación
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. Contrae espacios múltiples
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# Normaliza el texto
normalized = normalize_arabic(text)
# Tokeniza, elimina palabras de parada y extrae raíces
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# Ejemplo de uso
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("Original:", raw_text)
print("Procesado:", preprocess_arabic_text(raw_text))
# Output: ممتاز سرع نصح جمع عمل مع
Paso 3: Entrenar un Clasificador Simple
Now, vectoricemos nuestro texto procesado usando TF-IDF y entrenemos un modelo de Regresión Logística:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# Datos de entrenamiento de muestra
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# Etiquetas: 1 = Positivo, 0 = Negativo
train_labels = [1, 0, 1, 0, 1]
# Preprocesa datos de entrenamiento
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# Crea el pipeline: vectorizador TF-IDF + clasificador de Regresión Logística
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# Entrena el modelo
model_pipeline.fit(preprocessed_train, train_labels)
# Prueba con un texto nuevo
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"Texto de prueba: '{test_text}'")
print(f"Preprocesado: '{preprocessed_test}'")
print(f"Sentimiento predicho: {'Positivo' if prediction == 1 else 'Negativo'}")
4. Walkthrough: Clasificación Moderna basada en Transformers (Hugging Face)
Aunque el stemming y TF-IDF funcionan bien para la clasificación básica, no logran capturar el contexto, el sarcasmo ni las variaciones dialectales complejas. Para obtener resultados de vanguardia, utilizamos Transformers preentrenados como AraBERT o CamelBERT.
A continuación, se muestra cómo usar la librería transformers de Hugging Face para realizar análisis de sentimiento en texto árabe en solo unas pocas líneas de código:
Paso 1: Instalar Dependencias
pip install transformers torch sentencepiece
Paso 2: Cargar el Pipeline del Modelo
Utilizaremos el modelo altamente optimizado CAMeL-Lab/bert-base-arabic-sentiment-msa alojado en el hub de Hugging Face:
from transformers import pipeline
# Inicializa el pipeline de analisis de sentimiento con un modelo arabe especializado
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# Frases de prueba (MSA y dialectal)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة على الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"Texto: {sentence}")
print(f"Sentimiento: {label} ({confidence:.2f}% de confianza)
")
5. Comparación de Modelos: Aprendizaje Automático Tradicional vs. Transformers
| Característica | ML Tradicional (TF-IDF + SVM/LR) | Transformers (AraBERT/CamelBERT) |
|---|---|---|
| Comprensión del Contexto | Baja (trata las palabras como características independientes) | Alta (comprende el orden de las palabras y el contexto) |
| Manejo de Dialectos | Deficiente (requiere diccionarios dialectales personalizados) | Excelente (maneja dialectos complejos de forma natural) |
| Requisitos de Cómputo | Extremadamente bajos (se ejecuta en cualquier CPU en milisegundos) | Altos (requiere GPU para una inferencia rápida) |
| Datos de Entrenamiento Necesarios | Altos (necesita grandes conjuntos etiquetados para generalizar) | Bajos (preentrenado, funciona bien con ajuste fino) |
| Fuera de Vocabulario (OOV) | Alto riesgo de perder palabras nuevas | Riesgo mínimo (utiliza tokenización de subpalabras) |
6. Conclusión
El análisis de sentimiento en árabe es un campo en rápida evolución. Mientras que las técnicas tradicionales de aprendizaje automático con preprocesamiento personalizado (como la normalización y la extracción de raíces) son rápidas y rentables para tareas sencillas, los Transformers modernos han establecido un nuevo estándar para la precisión y el manejo de dialectos.
Al combinar reglas de limpieza lingüística adecuadas con las arquitecturas de modelo correctas, puede construir sistemas potentes capaces de desbloquear la voz emocional del mundo árabe.
Explore más perspectivas sobre IA y NLP en el Blog de Ghaznix →