阿拉伯语情感分析:实用的 NLP 预处理和模型演练

在全球化数字通信时代,情感分析(识别文本背后情绪基调的任务)已成为企业、政府和研究人员的关键工具。虽然英语等语言的情感分析已经高度成熟,但将其应用于阿拉伯语则面临着一系列独特的语言和技术挑战。
阿拉伯语拥有超过 4 亿使用者,是世界上使用最广泛的语言之一。然而,其丰富的形态结构、双层语言现象(标准语与口语并存)以及复杂的书写系统需要专门的预处理和建模策略。
本指南提供了阿拉伯语情感分析的全面演练,详细介绍了挑战、预处理流程、经典的机器学习实现(TF-IDF + 逻辑回归)以及使用 Hugging Face Transformers 的现代深度学习方法。
1. 阿拉伯语 NLP 的语言挑战
在编写代码之前,开发人员必须了解为什么阿拉伯语不能使用标准的西方 NLP 流程进行处理:
- 双层语言现象 (Diglossia): 阿拉伯语分为现代标准阿拉伯语 (MSA)(用于正式写作、新闻和官方文档)和口语方言 (Darja/Ammiya)(用于社交媒体和日常交流)。方言(例如埃及、黎凡特、海湾方言)在词汇、语法和情感表达上存在显著差异。
- 丰富的形态学 (Rich Morphology): 阿拉伯语是一种模板化语言,单词是通过应用特定模式从三字母或四字母词根衍生而来的。单个单词可以包含表示代词、介词和时态的前缀、后缀和中缀(例如 وسيكتبونها - “他们将写下它”)。
- 拼写变化 (Orthographic Variations): 阿拉伯语字母的形状经常根据其在单词中的位置而变化,并且用户经常混用某些字母(例如 Alif 的变体
أ、إ、آ、ا,或 Yaa 变体ي与ى)。 - 变音符号 (Tashkeel): 短元音以变音符号的形式写在字母的上方或下方(例如 Fat-hah、Dammah、Kasrah)。虽然它们可以明确含义,但在数字文本中通常被省略,从而导致歧义;或者添加不一致,导致数据稀疏。
2. 阿拉伯语 NLP 预处理流程
为了处理阿拉伯语文本,我们必须构建一个专门的预处理流程,处理文本规范化、去变音符、分词、词干提取和模型推理:
graph TD
A[原始阿拉伯语文本] --> B[规范化与清洗]
B --> C[去除变音符号与标点]
C --> D[分词]
D --> E[词干提取 / 词形还原]
E --> F[特征向量化 / 词嵌入]
F --> G[情感分类器]
G --> H[输出结果:积极 / 消极 / 中性]
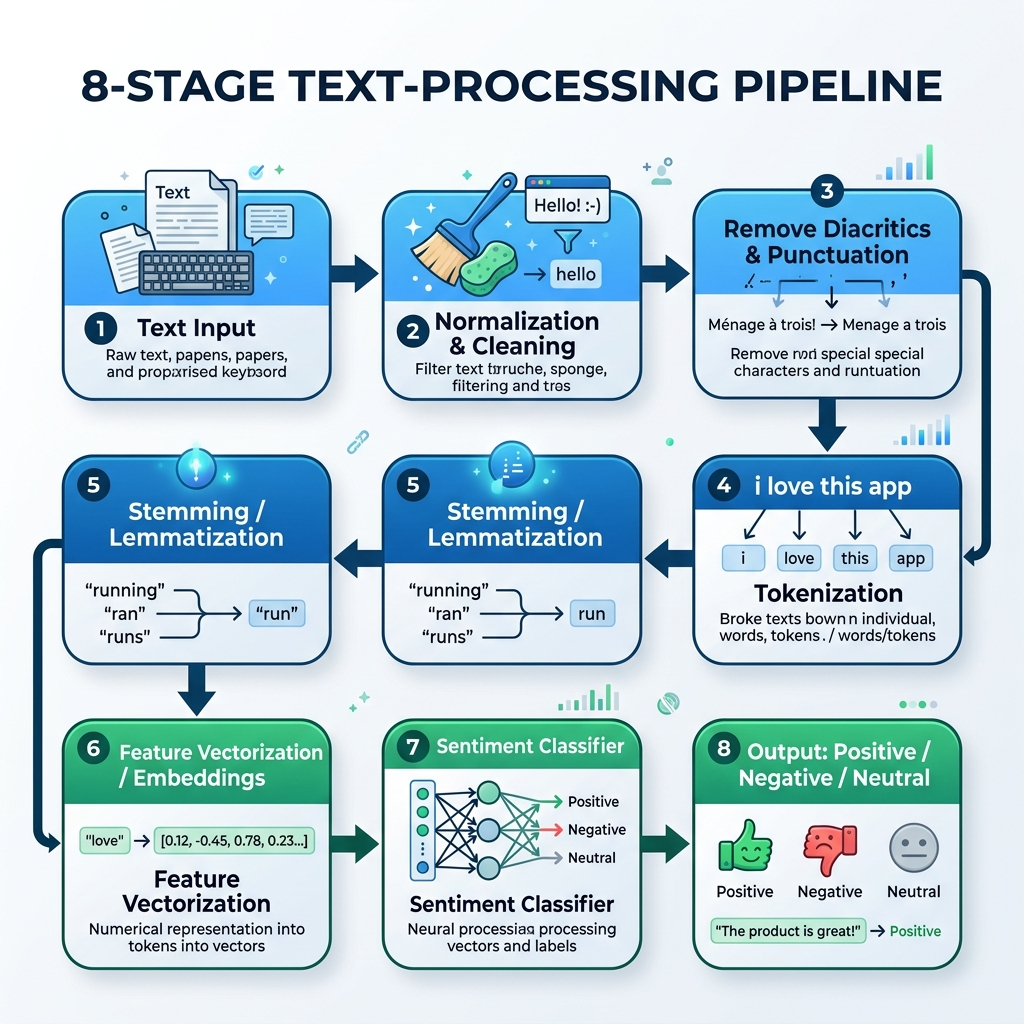
3. 步步详解:经典预处理与机器学习 (Python)
让我们使用 Python、NLTK 和 scikit-learn实现一个完整的流程。我们将编写自定义的规范化规则,并使用 NLTK 的 ISRIStemmer(专门为阿拉伯语设计的检索词干提取器)。
步骤 1:安装依赖项
首先,确保您已安装所需的库:
pip install nltk scikit-learn
步骤 2:编写预处理代码
以下是用于清洗、规范化和提取阿拉伯语文本词干的 Python 代码:
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# 如果尚未下载停用词,请先下载
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# 初始化阿拉伯语词干提取器
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. 去除变音符号 (Tashkeel)
text = re.sub(r'[ً-ْ]', '', text)
# 2. 将各种 Alif 规范化为普通的 Alif
text = re.sub(r'[أإآ]', 'ا', text)
# 3. 规范化 Yaa 和 Alif Maqsoora
text = re.sub(r'ى', 'ي', text)
# 4. 将 Ta Marbuta 规范化为 Haa
text = re.sub(r'ة', 'ه', text)
# 5. 去除非阿拉伯语字符和标点符号
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. 合并多个空格
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# 规范化文本
normalized = normalize_arabic(text)
# 分词并去除停用词,然后提取词干
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# 示例用法
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("原始文本:", raw_text)
print("预处理后:", preprocess_arabic_text(raw_text))
# 输出: ممتاز سرع نصح جمع عمل مع
步骤 3:训练简单分类器
现在,让我们使用 TF-IDF 将处理后的文本向量化,并训练一个逻辑回归模型:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# 示例训练数据
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# 标签:1 = 积极,0 = 消极
train_labels = [1, 0, 1, 0, 1]
# 预处理训练数据
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# 创建管道:TF-IDF 向量化器 + 逻辑回归分类器
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# 训练模型
model_pipeline.fit(preprocessed_train, train_labels)
# 使用新文本进行测试
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"测试文本: '{test_text}'")
print(f"预处理后: '{preprocessed_test}'")
print(f"预测情感: {'积极' if prediction == 1 else '消极'}")
4. 步步详解:现代基于 Transformer 的分类 (Hugging Face)
虽然词干提取和 TF-IDF 对于基础分类效果很好,但它们无法捕捉上下文、讽刺以及复杂的方言变化。为了获得最先进的效果,我们使用预训练的 Transformer 模型,如 AraBERT 或 CamelBERT。
以下是如何使用 Hugging Face 的 transformers 库,仅需几行代码即可对阿拉伯语文本进行情感分析:
步骤 1:安装依赖项
pip install transformers torch sentencepiece
步骤 2:加载模型管道
我们将使用托管在 Hugging Face Hub 上的高度优化的 CAMeL-Lab/bert-base-arabic-sentiment-msa 模型:
from transformers import pipeline
# 使用专业的阿拉伯语模型初始化情感分析管道
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# 测试句子(标准语和方言)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة على الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"文本: {sentence}")
print(f"情感预测: {label} (置信度 {confidence:.2f}%)
")
5. 模型对比:传统机器学习 vs. Transformer
| 特性 | 传统机器学习 (TF-IDF + SVM/LR) | Transformer (AraBERT/CamelBERT) |
|---|---|---|
| 上下文理解 | 低(将单词视为独立的特征) | 高(理解词序和上下文关系) |
| 方言处理能力 | 差(需要自定义方言词典) | 极佳(自然地处理复杂方言) |
| 计算资源需求 | 极低(在任何 CPU 上毫秒级运行) | 高(需要 GPU 进行快速推理) |
| 所需训练数据 | 高(需要大量标注数据集进行泛化) | 低(预训练模型,微调效果好) |
| 未登录词 (OOV) | 极易丢失新词 | 风险极小(使用子词分词) |
6. 总结
阿拉伯语情感分析是一个快速发展的领域。虽然传统的机器学习技术结合自定义预处理(如规范化和词干提取)对于简单任务来说既快速又经济,但现代 Transformer 已为准确率和方言处理树立了新的标杆。
通过将适当的语言清洗规则与合适的模型架构相结合,您可以构建强大的系统,倾听阿拉伯世界的真实声音。