अरबी सेंटीमेंट विश्लेषण: एक व्यावहारिक एनएलपी प्रीप्रोसेसिंग और मॉडल वॉकथ्रू

वैश्वीकृत डिजिटल संचार के युग में, सेंटीमेंट विश्लेषण—किसी पाठ के पीछे के भावनात्मक स्वर की पहचान करने का कार्य—व्यवसायों, सरकारों और शोधकर्ताओं के लिए महत्वपूर्ण हो गया है। जबकि अंग्रेजी जैसी भाषाओं के लिए सेंटीमेंट विश्लेषण अत्यधिक परिपक्व है, अरबी पर इसे लागू करना भाषाई और तकनीकी चुनौतियों का एक अनूठा सेट प्रस्तुत करता है।
40 करोड़ से अधिक बोलने वालों के साथ, अरबी दुनिया में सबसे व्यापक रूप से बोली जाने वाली भाषाओं में से एक है। हालाँकि, इसकी समृद्ध रूपात्मक संरचना (Morphology), डिग्लोसिया (मानक और बोलचाल के रूपों का सह-अस्तित्व), और जटिल लेखन प्रणाली के लिए विशेष प्रीप्रोसेसिंग और मॉडलिंग रणनीतियों की आवश्यकता होती है।
यह मार्गदर्शिका अरबी सेंटीमेंट विश्लेषण का एक व्यापक विवरण प्रदान करती है, जिसमें चुनौतियों, प्रीप्रोसेसिंग पाइपलाइन, एक क्लासिक मशीन लर्निंग कार्यान्वयन (TF-IDF + लॉजिस्टिक रिग्रेशन), और Hugging Face Transformers का उपयोग करके एक आधुनिक डीप लर्निंग दृष्टिकोण का विवरण दिया गया है।
1. अरबी एनएलपी की भाषाई चुनौतियाँ
कोड लिखने से पहले, एक डेवलपर को यह समझना चाहिए कि अरबी को मानक पश्चिमी एनएलपी पाइपलाइनों के साथ क्यों संसाधित नहीं किया जा सकता है:
- डिग्लोसिया (Diglossia): अरबी को आधुनिक मानक अरबी (MSA) (औपचारिक लेखन, समाचार और आधिकारिक दस्तावेजों में उपयोग की जाने वाली) और बोलचाल की बोलियाँ (Darja/Ammiya) (सोशल मीडिया और दैनिक भाषण में उपयोग की जाने वाली) के बीच विभाजित किया गया है। बोलियाँ (जैसे, मिस्र, लेवेंटिन, खाड़ी) शब्दावली, व्याकरण और भावनाओं की अभिव्यक्ति में काफी भिन्न होती हैं।
- समृद्ध रूपविज्ञान (Rich Morphology): अरबी एक रूट-आधारित भाषा है जहाँ शब्दों को पैटर्न लागू करके तीन या चार अक्षरों के रूट से लिया जाता है। एक एकल शब्द में उपसर्ग (prefixes), प्रत्यय (suffixes) और इनफिक्स (infixes) शामिल हो सकते हैं जो सर्वनामों, पूर्वसर्गों और काल का प्रतिनिधित्व करते हैं (उदाहरण के लिए, وسيكتبونها - “और वे इसे लिखेंगे”)।
- वर्तनी संबंधी विविधताएं: अरबी अक्षर अक्सर शब्द में अपनी स्थिति के आधार पर आकार बदलते हैं, और उपयोगकर्ता अक्सर कुछ अक्षरों को एक-दूसरे के स्थान पर उपयोग करते हैं (उदाहरण के लिए, अलिफ़ के आकार जैसे
أ,إ,آ,اया या के आकार जैसेيबनामى)। - स्वर चिह्न (Tashkeel): लघु स्वरों को अक्षरों के ऊपर या नीचे स्वर चिह्नों (जैसे फतह, दम्मा, कसरा) के रूप में लिखा जाता है। हालाँकि वे अर्थ को स्पष्ट करते हैं, लेकिन डिजिटल पाठ में उन्हें अक्सर छोड़ दिया जाता है, जिससे अस्पष्टता पैदा होती है।
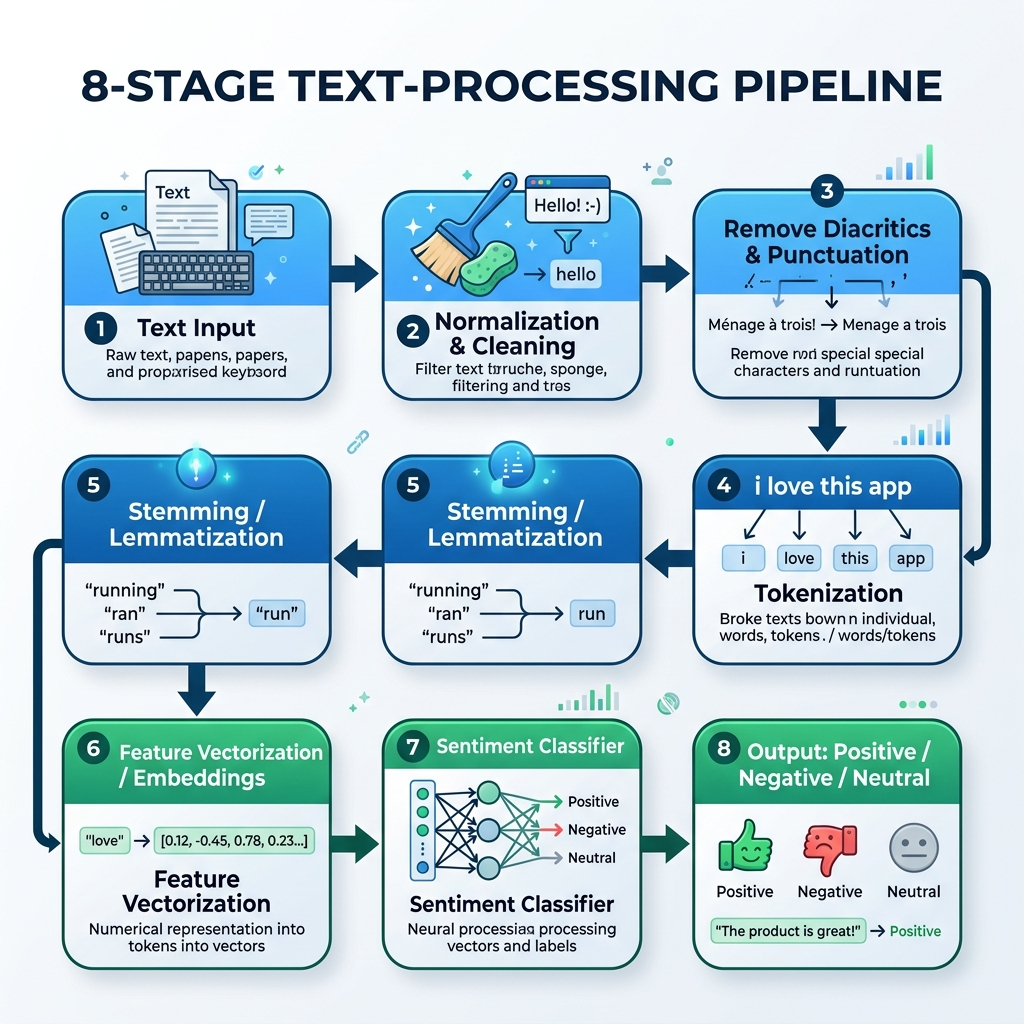
2. अरबी एनएलपी पाइपलाइन
अरबी पाठ को संसाधित करने के लिए, हमें एक विशेष पाइपलाइन का निर्माण करना होगा जो सामान्यीकरण, स्वर चिह्नों को हटाने, टोकनीकरण, स्टेमिंग (मूल शब्द निकालना) और मॉडल अनुमान को संभालती है:
graph TD
A[कच्चा अरबी पाठ] --> B[सामान्यीकरण और सफाई]
B --> C[स्वर चिह्न और विराम चिह्न हटाना]
C --> D[टोकनीकरण]
D --> E[स्टेमिंग / लेमटाइजेशन]
E --> F[फ़ीचर वेक्टराइजेशन / एम्बेडिंग]
F --> G[सेंटीमेंट क्लासिफायर]
G --> H[आउटपुट: सकारात्मक / नकारात्मक / तटस्थ]
3. वॉकथ्रू: क्लासिक प्रीप्रोसेसिंग और मशीन लर्निंग (पायथन)
आइए पायथन, NLTK, और scikit-learn का उपयोग करके एक संपूर्ण पाइपलाइन लागू करें। हम कस्टम सामान्यीकरण नियम लिखेंगे और NLTK के ISRIStemmer (विशेष रूप से अरबी के लिए डिज़ाइन किया गया एक स्टेमर) का उपयोग करेंगे।
चरण 1: निर्भरताएँ स्थापित करें
सबसे पहले, सुनिश्चित करें कि आपके पास आवश्यक पुस्तकालय स्थापित हैं:
pip install nltk scikit-learn
चरण 2: प्रीप्रोसेसिंग कोड लिखें
अरबी पाठ को साफ करने, सामान्य करने और स्टेम करने का पायथन कोड यहाँ दिया गया है:
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# यदि पहले से नहीं किया है तो स्टॉपवर्ड डाउनलोड करें
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# अरबी स्टेमर को इनिशियलाइज़ करें
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. स्वर चिह्नों को हटाएँ (Tashkeel)
text = re.sub(r'[ً-ْ]', '', text)
# 2. अलिफ़ के आकारों को एक साधारण अलिफ़ में सामान्य करें
text = re.sub(r'[أإآ]', 'ا', text)
# 3. या और अलिफ़ मकसूरा को सामान्य करें
text = re.sub(r'ى', 'ي', text)
# 4. ता मरबूता को हा में सामान्य करें
text = re.sub(r'ة', 'ه', text)
# 5. गैर-अरबी वर्णों और विराम चिह्नों को हटाएँ
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. अतिरिक्त रिक्त स्थानों को हटाएँ
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# पाठ को सामान्य करें
normalized = normalize_arabic(text)
# टोकनाइज़ करें, स्टॉपवर्ड्स हटाएँ और स्टेमिंग करें
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# उपयोग का उदाहरण
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("मूल पाठ:", raw_text)
print("संसाधित पाठ:", preprocess_arabic_text(raw_text))
# आउटपुट: ممتاز سرع نصح جمع عمل مع
चरण 3: एक सरल क्लासिफायरियर को प्रशिक्षित करें
अब, TF-IDF का उपयोग करके हमारे संसाधित पाठ को वेक्टराइज़ करें और एक लॉजिस्टिक रिग्रेशन मॉडल को प्रशिक्षित करें:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# नमूना प्रशिक्षण डेटा
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# लेबल: 1 = सकारात्मक, 0 = नकारात्मक
train_labels = [1, 0, 1, 0, 1]
# प्रशिक्षण डेटा को प्रीप्रोसेस करें
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# पाइपलाइन बनाएँ: TF-IDF वेक्टराइज़र + लॉजिस्टिक रिग्रेशन क्लासिफायरियर
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# मॉडल को प्रशिक्षित करें
model_pipeline.fit(preprocessed_train, train_labels)
# नए पाठ के साथ परीक्षण करें
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"परीक्षण पाठ: '{test_text}'")
print(f"प्रीप्रोसेस्ड: '{preprocessed_test}'")
print(f"अनुमानित भावना: {'सकारात्मक' if prediction == 1 else 'नकारात्मक'}")
4. वॉकथ्रू: आधुनिक ट्रांसफार्मर-आधारित वर्गीकरण (Hugging Face)
जबकि स्टेमिंग और TF-IDF बुनियादी वर्गीकरण के लिए अच्छा काम करते हैं, वे संदर्भ, व्यंग्य और जटिल बोलचाल के अंतर को पकड़ने में विफल रहते हैं। अत्याधुनिक परिणामों के लिए, हम पहले से प्रशिक्षित ट्रांसफार्मर जैसे AraBERT या CamelBERT का उपयोग करते हैं।
यहाँ बताया गया है कि आप अरबी पाठ पर केवल कुछ पंक्तियों के कोड में सेंटीमेंट विश्लेषण चलाने के लिए Hugging Face की transformers लाइब्रेरी का उपयोग कैसे कर सकते हैं:
चरण 1: निर्भरताएँ स्थापित करें
pip install transformers torch sentencepiece
चरण 2: मॉडल पाइपलाइन लोड करें
हम हगिंग फेस हब पर होस्ट किए गए अत्यधिक अनुकूलित मॉडल CAMeL-Lab/bert-base-arabic-sentiment-msa का उपयोग करेंगे:
from transformers import pipeline
# एक विशिष्ट अरबी मॉडल के साथ सेंटीमेंट विश्लेषण पाइपलाइन को इनिशियलाइज़ करें
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# परीक्षण वाक्य (MSA और बोलचाल की भाषा)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة على الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"पाठ: {sentence}")
print(f"भावना: {label} ({confidence:.2f}%% सटीकता)
")
5. मॉडल तुलना: पारंपरिक मशीन लर्निंग बनाम ट्रांसफार्मर
| विशेषता | पारंपरिक एमएल (TF-IDF + SVM/LR) | ट्रांसफार्मर (AraBERT/CamelBERT) |
|---|---|---|
| प्रासंगिक समझ | कम (शब्दों को स्वतंत्र विशेषताओं के रूप में मानता है) | उच्च (शब्दों के क्रम और संदर्भ को समझता है) |
| बोली हैंडलिंग | खराब (कस्टम बोली शब्दकोशों की आवश्यकता होती है) | उत्कृष्ट (जटिल बोलियों को स्वाभाविक रूप से संभालता है) |
| कंप्यूटिंग आवश्यकताएँ | बहुत कम (मिलीसेकंड में किसी भी सीपीयू पर चलता है) | उच्च (तेज अनुमान के लिए जीपीयू की आवश्यकता होती) |
| प्रशिक्षण डेटा की आवश्यकता | उच्च (सामान्यीकरण के लिए बड़े लेबल वाले सेट की आवश्यकता) | कम (पूर्व-प्रशिक्षित, फ़ाइन-ट्यूनिंग के साथ अच्छा काम करता है) |
| शब्दावली से बाहर (OOV) | नए शब्दों के छूट जाने का उच्च जोखिम | न्यूनतम जोखिम (उप-शब्द टोकनीकरण का उपयोग करता है) |
6. निष्कर्ष
अरबी सेंटीमेंट विश्लेषण एक तेजी से विकसित होने वाला क्षेत्र है। जबकि कस्टम प्रीप्रोसेसिंग (जैसे सामान्यीकरण और स्टेमिंग) के साथ पारंपरिक मशीन लर्निंग तकनीकें सरल कार्यों के लिए तेज़ और लागत प्रभावी हैं, आधुनिक ट्रांसफार्मर ने सटीकता और बोली प्रबंधन के लिए एक नया मानक स्थापित किया है।
सही मॉडल आर्किटेक्चर के साथ उचित भाषाई सफाई नियमों को जोड़कर, आप शक्तिशाली सिस्टम बना सकते हैं जो अरब दुनिया के भावनात्मक स्वर को समझने में सक्षम हैं।
Ghaznix ब्लॉग पर AI और NLP के बारे में अधिक जानकारी प्राप्त करें →