Analisi del Sentiment in Arabo: Una Guida Pratica alla Pre-elaborazione NLP e ai Modelli

Nell’era della comunicazione digitale globalizzata, l’analisi del sentiment (il compito di identificare il tono emotivo dietro un testo) è diventata cruciale per aziende, governi e ricercatori. Sebbene l’analisi del sentiment sia altamente matura per lingue come l’inglese, l’applicazione all’arabo presenta una serie unica di sfide linguistiche e tecniche.
Con oltre 400 milioni di parlanti, l’arabo è una delle lingue più parlate al mondo. Tuttavia, la sua ricca struttura morfologica, la diglossia (coesistenza di forme standard e colloquiali) e il complesso sistema di scrittura richiedono strategie di pre-elaborazione e modellazione specializzate.
Questa guida fornisce un percorso completo dell’analisi del sentiment in arabo, descrivendone le sfide, la pipeline di pre-elaborazione, un’implementazione classica di Machine Learning (TF-IDF + Regressione Logistica) e un approccio moderno di Deep Learning utilizzando i Transformer di Hugging Face.
1. Le sfide linguistiche dell’NLP in Arabo
Prima di scrivere il codice, uno sviluppatore deve capire perché l’arabo non può essere trattato con le pipeline NLP occidentali standard:
- Diglossia: L’arabo è diviso tra Arabo Standard Moderno (MSA) (usato nella scrittura formale, nelle notizie e nei documenti ufficiali) e Dialetti Colloquiali (Darja/Ammiya) (usati nei social media e nel discorso quotidiano). I dialetti (ad esempio, egiziano, levantino, del Golfo) differiscono significativamente nel vocabolario, nella grammatica e nelle espressioni del sentiment.
- Morfologia Ricca: L’arabo è una lingua radicata in cui le parole derivano da una radice di tre o quattro lettere applicando schemi. Una singola parola può contenere prefissi, suffissi e infissi che rappresentano pronomi, preposizioni e tempi verbali (ad esempio, وسيكتبونها - “e lo scriveranno”).
- Variazioni Ortografiche: Le lettere arabe spesso cambiano forma in base alla loro posizione e gli utenti utilizzano frequentemente lettere in modo intercambiabile (ad esempio, forme di Alif come
أ,إ,آ,اo forme di Yaa comeيrispetto aى). - Diacritici (Tashkeel): Le vocali brevi sono scritte come diacritici sopra o sotto le lettere (ad esempio, Fatha, Damma, Kasra). Sebbene chiariscano il significato, sono spesso omessi nei testi digitali, causando ambiguità, o aggiunti in modo incoerente, causando scarsità di dati.
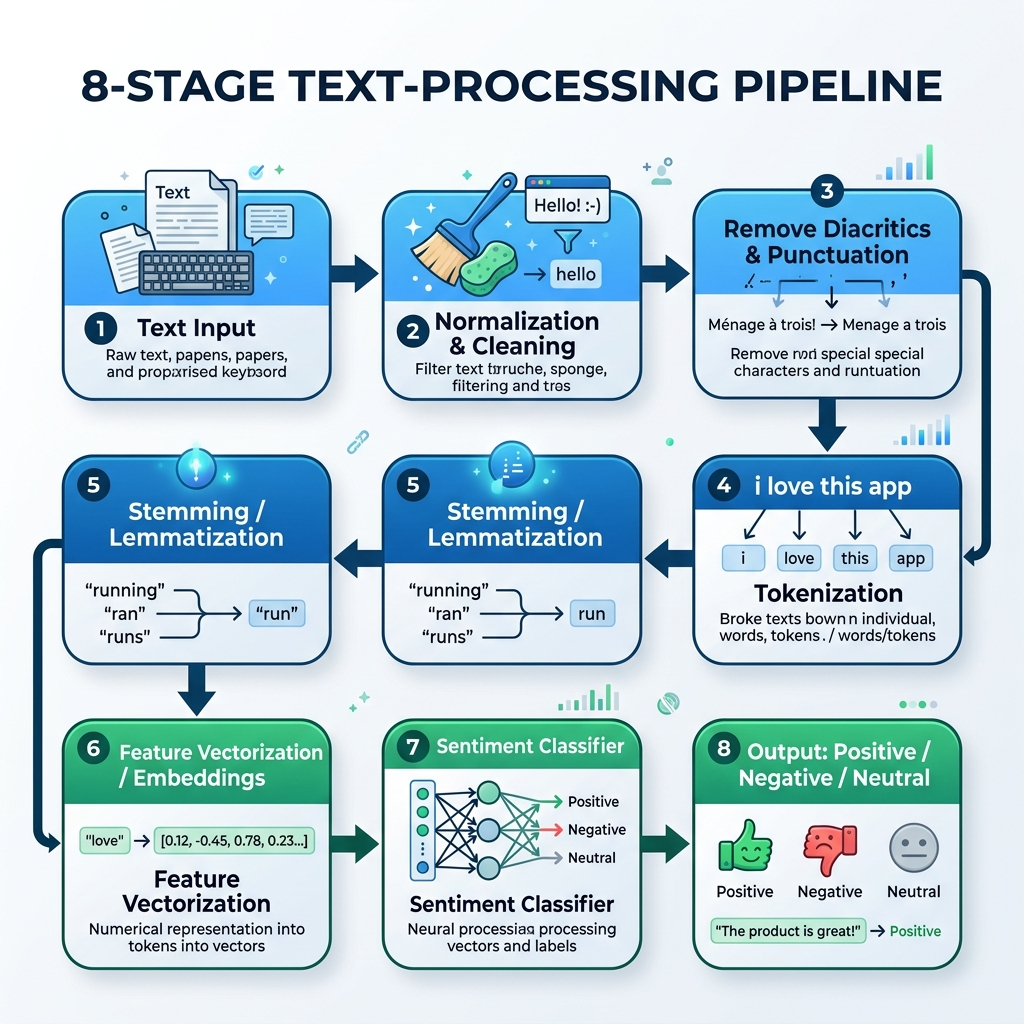
2. La Pipeline NLP per l’Arabo
Per elaborare il testo arabo, dobbiamo creare una pipeline specializzata che gestisca la normalizzazione, la rimozione dei diacritici, la tokenizzazione, lo stemming e l’inferenza del modello:
graph TD
A[Testo Arabo Grezzo] --> B[Normalizzazione & Pulizia]
B --> C[Rimuovi Diacritici & Punteggiatura]
C --> D[Tokenizzazione]
D --> E[Stemming / Lemmatizzazione]
E --> F[Vettorizzazione delle Caratteristiche / Embedding]
F --> G[Classificatore del Sentiment]
G --> H[Output: Positivo / Negativo / Neutro]
3. Walkthrough: Pre-elaborazione Classica e Machine Learning (Python)
Implementiamo una pipeline completa usando Python, NLTK e scikit-learn. Scriveremo regole di normalizzazione personalizzate e useremo ISRIStemmer di NLTK (uno stemmer per il recupero delle informazioni progettato specificamente per l’arabo).
Passo 1: Installare le Dipendenze
Per prima cosa, assicurati di avere installato le librerie richieste:
pip install nltk scikit-learn
Passo 2: Scrivere il Codice di Pre-elaborazione
Ecco il codice Python per pulire, normalizzare ed eseguire lo stemming del testo arabo:
import re
import nltk
from nltk.stem.isri import ISRIStemmer
# Scarica le stopword se non l'hai gia fatto
nltk.download('stopwords', quiet=True)
from nltk.corpus import stopwords
# Inizializza lo Stemmer Arabo
stemmer = ISRIStemmer()
arabic_stopwords = set(stopwords.words('arabic'))
def normalize_arabic(text):
# 1. Rimuovi i diacritici (Tashkeel)
text = re.sub(r'[ً-ْ]', '', text)
# 2. Normalizza le forme di Alif in un'unica Alif semplice
text = re.sub(r'[أإآ]', 'ا', text)
# 3. Normalizza Yaa e Alif Maqsoora
text = re.sub(r'ى', 'ي', text)
# 4. Normalizza Ta Marbuta in Haa
text = re.sub(r'ة', 'ه', text)
# 5. Rimuovi caratteri non arabi e punteggiatura
text = re.sub(r'[^ء-ي\s]', ' ', text)
# 6. Elimina gli spazi multipli
text = re.sub(r'\s+', ' ', text).strip()
return text
def preprocess_arabic_text(text):
# Normalizza il testo
normalized = normalize_arabic(text)
# Tokenizza, rimuovi le stopword ed esegui lo stemming
words = normalized.split()
processed_words = [stemmer.stem(word) for word in words if word not in arabic_stopwords]
return " ".join(processed_words)
# Esempio di utilizzo
raw_text = "الخدمةُ كانت ممتازةً وسريعةً جداً! أنصح الجميع بالتعامل معهم."
print("Originale:", raw_text)
print("Elaborato:", preprocess_arabic_text(raw_text))
# Output: ممتاز سرع نصح جمع عمل مع
Passo 3: Addestrare un Semplice Classificatore
Ora, vettorizziamo il nostro testo elaborato usando TF-IDF e addestriamo un modello di Regressione Logistica:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
# Dati di addestramento di esempio
train_sentences = [
"المنتج رائع جدا وأنصح بشرائه",
"التوصيل كان بطيئا والخدمة سيئة للغاية",
"أعجبني التطبيق وسهل الاستخدام",
"تجربة سيئة جدا ولا أنصح به أبدا",
"خدمة العملاء كانت متعاونة وممتازة"
]
# Etichette: 1 = Positivo, 0 = Negativo
train_labels = [1, 0, 1, 0, 1]
# Pre-elabora i dati di addestramento
preprocessed_train = [preprocess_arabic_text(s) for s in train_sentences]
# Crea la pipeline: vettorizzatore TF-IDF + classificatore Regressione Logistica
model_pipeline = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LogisticRegression())
])
# Addestra il modello
model_pipeline.fit(preprocessed_train, train_labels)
# Testa con un nuovo testo
test_text = "التطبيق سيئ للغاية ولا يعمل بشكل صحيح"
preprocessed_test = preprocess_arabic_text(test_text)
prediction = model_pipeline.predict([preprocessed_test])[0]
print(f"Testo di prova: '{test_text}'")
print(f"Pre-elaborato: '{preprocessed_test}'")
print(f"Sentiment previsto: {'Positivo' if prediction == 1 else 'Negativo'}")
4. Walkthrough: Classificazione Moderna basata su Transformer (Hugging Face)
Sebbene lo stemming e TF-IDF funzionino bene per la classificazione di base, non riescono a catturare il contesto, il sarcasmo e le complesse variazioni dialettali. Per risultati all’avanguardia, utilizziamo Transformer pre-addestrati come AraBERT o CamelBERT.
Ecco come utilizzare la libreria transformers di Hugging Face per eseguire l’analisi del sentiment su testo arabo in poche righe di codice:
Passo 1: Installare le Dipendenze
pip install transformers torch sentencepiece
Passo 2: Caricare la Pipeline del Modello
Useremo il modello altamente ottimizzato CAMeL-Lab/bert-base-arabic-sentiment-msa ospitato sull’hub Hugging Face:
from transformers import pipeline
# Inizializza la pipeline di analisi del sentiment con un modello arabo specializzato
arabic_sentiment_analyzer = pipeline(
"sentiment-analysis",
model="CAMeL-Lab/bert-base-arabic-sentiment-msa"
)
# Frasi di prova (MSA e dialettali)
sentences = [
"أنا سعيد جداً باستخدام هذا المنتج الرائع",
"الفيلم كان مملاً والقصة غير مترابطة sulla الإطلاق"
]
results = arabic_sentiment_analyzer(sentences)
for sentence, result in zip(sentences, results):
label = result['label']
confidence = result['score'] * 100
print(f"Testo: {sentence}")
print(f"Sentiment: {label} ({confidence:.2f}% confidenza)
")
5. Confronto dei Modelli: Machine Learning Tradizionale vs. Transformer
| Caratteristica | ML Tradizionale (TF-IDF + SVM/LR) | Transformer (AraBERT/CamelBERT) |
|---|---|---|
| Comprensione del Contesto | Bassa (tratta le parole come caratteristiche indipendenti) | Alta (comprende l’ordine delle parole e il contesto) |
| Gestione dei Dialetti | Scarsa (richiede dizionari dialettali personalizzati) | Eccellente (gestisce i dialetti complessi in modo naturale) |
| Requisiti di Calcolo | Estremamente bassi (funziona su qualsiasi CPU in millisecondi) | Alti (richiede una GPU per un’inferenza rapida) |
| Dati di Addestramento Necessari | Alti (richiede grandi set etichettati per generalizzare) | Bassi (pre-addestrato, funziona bene con il fine-tuning) |
| Fuori Vocabolario (OOV) | Alto rischio di perdere parole nuove | Rischio minimo (utilizza la tokenizzazione sub-word) |
6. Conclusione
L’analisi del sentiment in arabo è un campo in rapida evoluzione. Mentre le tecniche tradizionali di machine learning con pre-elaborazione personalizzata (come normalizzazione e stemming) sono veloci ed economiche per compiti semplici, i Transformer moderni hanno stabilito un nuovo standard per l’accuratezza e la gestione dei dialetti.
Combinando corrette regole di pulizia linguistica con le giuste architetture di modello, puoi creare sistemi potenti in grado di sbloccare la voce emotiva del mondo arabo.
Esplora altre approfondimenti su IA e NLP sul Blog di Ghaznix →