LLM を使用した自律型 AI ワークフローの構築

大規模言語モデル (LLM) は、私たちがテクノロジーと対話する方法を変革し、単純な会話型チャットボットから、複雑な複数ステップのアクションを実行できる推論エンジンへと急速に移行しました。単一のプロンプト応答インタラクションは強力ですが、企業環境における生成 AI の真の価値は 自律 AI ワークフローにあります。
人間のオペレーターに依存してすべてのステップを調整するのではなく、自律型ワークフローは、長期間にわたってタスクを計画、実行、評価、自己修正する中心的な意思決定者として LLM を使用します。
この詳細な説明では、最新の設計パターン、ステート マシン、堅牢なガードレールを使用して、信頼性の高い自律型 AI ワークフローを設計、構築、展開する方法を探ります。
1. エージェントの変化: チャットボットとワークフロー
LLM アプリケーションの進化は、自律性の 4 つの異なるレベルに分類できます。
| レベル | パラダイム | 人間の役割 | コアメカニズム |
|---|---|---|---|
| レベル 1 | 会話型チャット | 高 (毎ターンプロンプトが表示されます) | ステートレスな 1 ターンの完了 |
| レベル 2 | ツール呼び出し / 関数呼び出し | 中 (コンテキストを提供) | モデルは呼び出す API を選択します。結果を返します |
| レベル 3 | 指示されたワークフロー | 低 (目標とグラフを定義) | LLM ルーティングを備えたハードコーディングされたステート マシン |
| レベル 4 | 完全自律型エージェント | 最小限 (目的/予算を定義) | LLM 主導の計画、実行、およびリフレクション ループ |
レベル 4 エージェントは柔軟性に優れていますが、運用環境での予測が難しいことで知られています。したがって、ほとんどのエンタープライズ アーキテクチャは、ソフトウェア ステート マシンの決定論的な信頼性と LLM の動的な推論を組み合わせた レベル 3: 指示されたワークフロー に基づいて構築されています。
2. 自律型ワークフローの中核となる柱
自律型ワークフローを構築するには、次の 4 つの基本コンポーネントを組み合わせる必要があります。
A. 推論と計画
ワークフローの中心となるのは計画パラダイムです。単純な LLM 呼び出しは、最終的な答えをすぐに出力しようとするため、推論の失敗につながることがよくあります。自律型ワークフローは、特殊な計画ループを使用します。
- ReAct (Reason + Act): モデルは反復的に思考、行動 (ツールの呼び出し)、結果の観察を行い、目標が達成されるまでこのループを繰り返します。
- 思考連鎖 (CoT): 結論に達する前に、モデルに段階的な推論を強制的に出力させます。
- 思考の木 (ToT): 複数の代替パスを生成および評価し、さまざまな分岐を追跡し、パスが失敗した場合にバックトラックします。
B. 短期記憶と長期記憶
自律システムは、複数の実行サイクルにわたって状態を維持する必要があります。
- 短期メモリ: ワークフローが現在実行していることを追跡するスレッド コンテキスト、状態変数、および実行ログ。
- 長期記憶: ワークフローで実行履歴、ユーザー設定、企業ドキュメントを呼び出すことを可能にするベクトル データベースとセマンティック検索システム。
C. ツールと Web の統合
物理世界またはデジタル世界に作用するには、LLM は外部サービスとインターフェイスする必要があります。モデルは、データベース ドライバー、ファイル システム、Web ブラウザー、およびサードパーティ API にアクセスする必要があります。最新のワークフローでは モデル コンテキスト プロトコル (MCP) の採用が増えており、LLM がコンテキスト データ ソースと実行サンドボックスを検出して安全に接続する方法が標準化されています。
3. 主要なアーキテクチャ設計パターン
複雑なエージェント システムを構築する場合、ソフトウェア エンジニアは一連の実証済みの設計パターンに依存して、複雑さを管理し、予測可能性を維持します。
パターン 1: ルーター パターン
ルーターは受信入力を読み取り、次にどの特殊な LLM プロンプト、データベース、または API ハンドラーがそれを処理するかを決定します。これにより、単一のモノリシック LLM プロンプトが多すぎる命令で過負荷になるのを防ぎます。
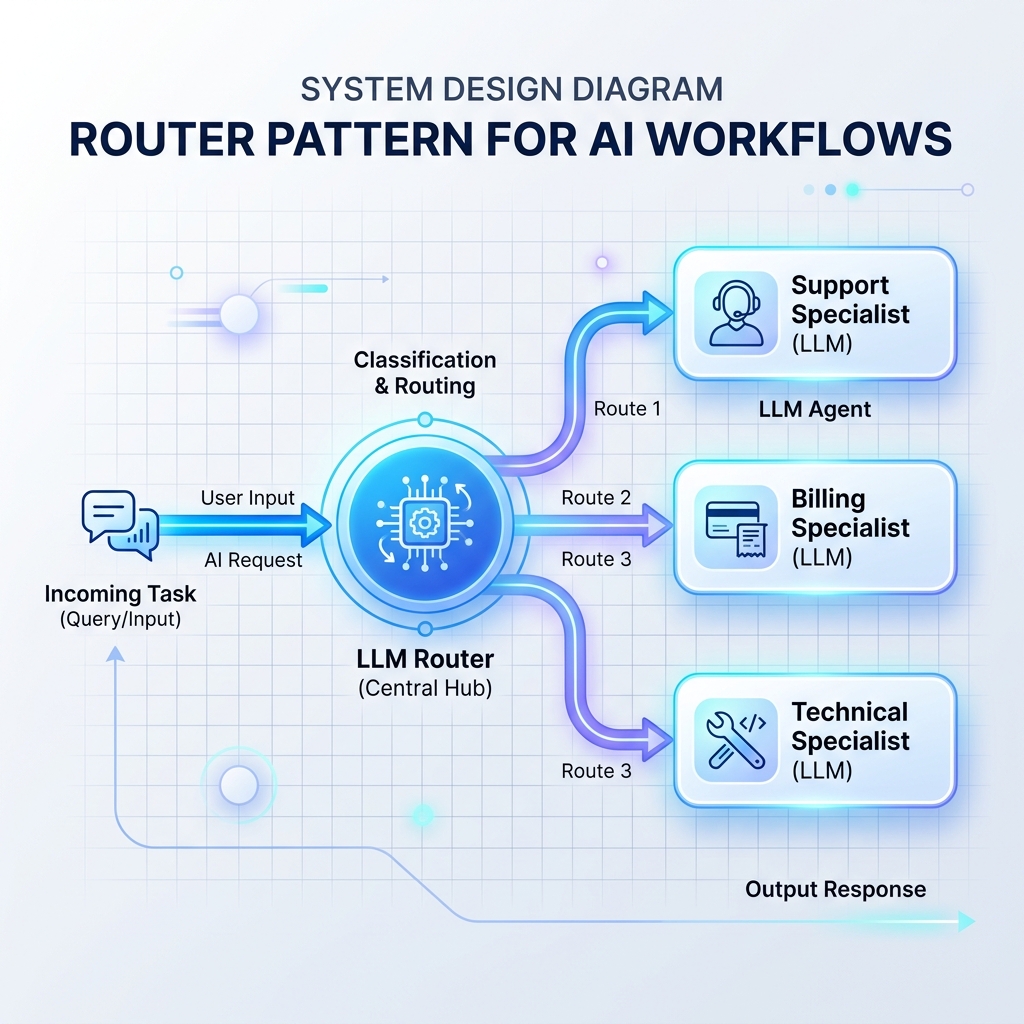
パターン 2: オーケストレーターとワーカー
中央オーケストレーター LLM は、大規模で複雑なタスクを独立したサブタスクに分割します。次に、これらのタスクをワーカー ノード (特殊な LLM または標準のマイクロサービス) に委任し、結果を合成します。
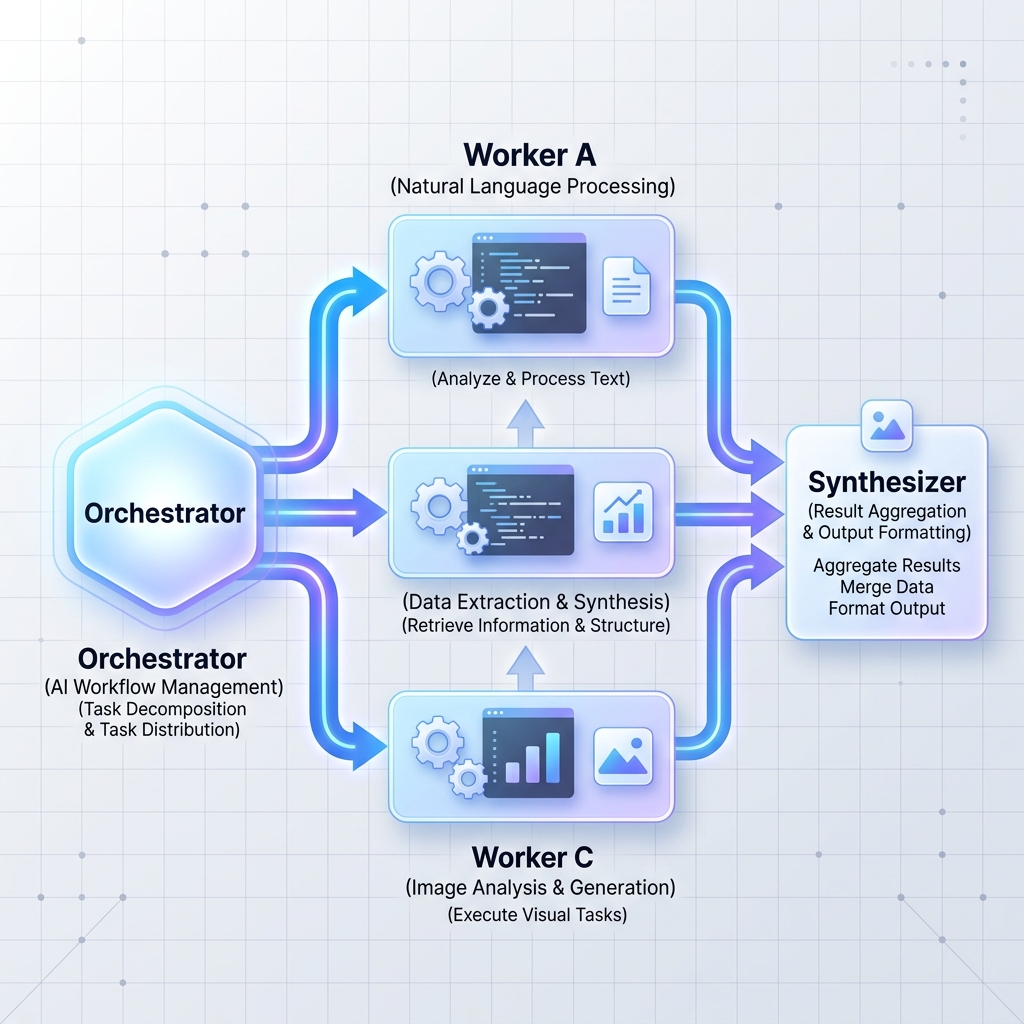
パターン 3: 評価者と最適化者のループ
オプティマイザーはドラフト応答を生成するかタスクを実行し、評価者はそれを正式な基準 (単体テスト、セキュリティ スキャナー、または個別の評価プロンプトなど) に照らしてチェックします。チェックが失敗した場合、フィードバックはオプティマイザに戻されて応答が再生成されます。
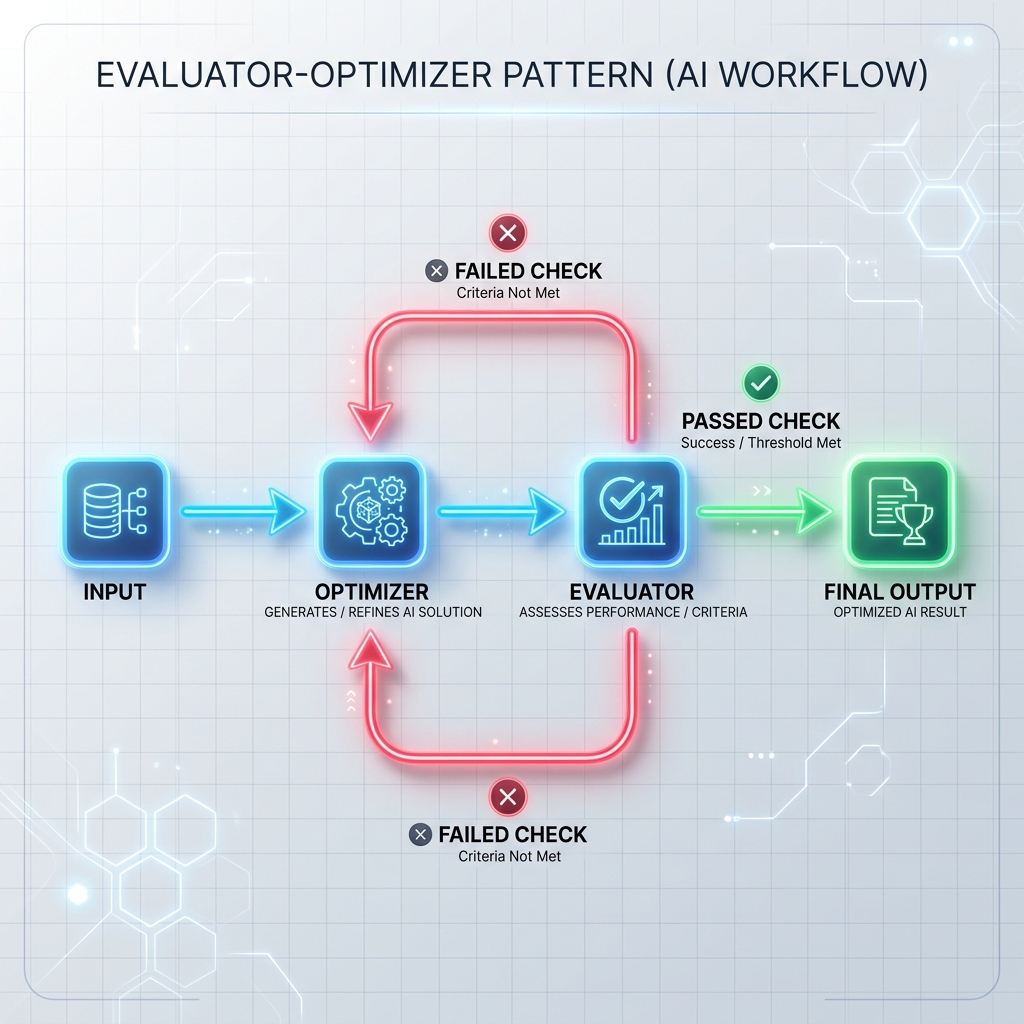
4. Python での状態ベースのエージェントの構築
単純なステートマシンを使用した自律エージェントの具体的な実装を見てみましょう。返金リクエストを処理するエージェントを定義します。エージェントは顧客の購入履歴を確認し、ポリシーに照らしてリクエストを検証し、電子メールでの回答の下書きを作成し、返金が 100 ドルを超える場合は人間の承認を求めます。
import json
from typing import Dict, Any
# Mock databases and tools
PURCHASE_DB = {
"user_123": {"item": "Premium Subscription", "price": 149.00, "days_ago": 12},
"user_456": {"item": "Basic License", "price": 49.00, "days_ago": 45}
}
class AutonomousRefundAgent:
def __init__(self):
self.state: Dict[str, Any] = {
"step": "INIT",
"user_id": None,
"refund_amount": 0.0,
"policy_passed": False,
"requires_approval": False,
"approved": False,
"response_draft": "",
"log": []
}
def run(self, user_id: str, request_text: str):
self.state["user_id"] = user_id
self.state["log"].append(f"Started workflow for user {user_id} with request: '{request_text}'")
while self.state["step"] != "COMPLETE":
current_step = self.state["step"]
if current_step == "INIT":
self._fetch_user_data()
elif current_step == "VALIDATE_POLICY":
self._validate_policy()
elif current_step == "CHECK_APPROVAL":
self._check_approval_requirements()
elif current_step == "WAITING_FOR_HUMAN":
# Pause execution and yield control back to the orchestrator
self.state["log"].append("Execution paused: waiting for human operator approval.")
break
elif current_step == "EXECUTE_REFUND":
self._execute_refund()
elif current_step == "DRAFT_RESPONSE":
self._draft_response()
return self.state
def _fetch_user_data(self):
user_id = self.state["user_id"]
purchase = PURCHASE_DB.get(user_id)
if not purchase:
self.state["response_draft"] = "No purchase history found for this user."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Fetch failed: User not found in database.")
return
self.state["refund_amount"] = purchase["price"]
self.state["purchase_age_days"] = purchase["days_ago"]
self.state["step"] = "VALIDATE_POLICY"
self.state["log"].append(f"Fetched purchase data: {purchase}")
def _validate_policy(self):
# Business rule: Refunds only allowed within 30 days
age = self.state["purchase_age_days"]
if age <= 30:
self.state["policy_passed"] = True
self.state["step"] = "CHECK_APPROVAL"
self.state["log"].append("Policy validation passed (within 30-day window).")
else:
self.state["policy_passed"] = False
self.state["response_draft"] = "Sorry, our policy only allows refunds within 30 days of purchase."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Policy validation failed: Purchase older than 30 days.")
def _check_approval_requirements(self):
# Business rule: Refunds over $100 require human review
amount = self.state["refund_amount"]
if amount > 100.0:
self.state["requires_approval"] = True
self.state["step"] = "WAITING_FOR_HUMAN"
self.state["log"].append(f"Refund of ${amount} exceeds limit. Moving to human approval state.")
else:
self.state["requires_approval"] = False
self.state["step"] = "EXECUTE_REFUND"
self.state["log"].append(f"Refund of ${amount} is within limits. Proceeding to execution.")
def resume_with_human_decision(self, approved: bool):
if self.state["step"] != "WAITING_FOR_HUMAN":
raise ValueError("Agent is not currently waiting for approval.")
self.state["approved"] = approved
self.state["log"].append(f"Human manager decision received: Approved = {approved}")
if approved:
self.state["step"] = "EXECUTE_REFUND"
else:
self.state["response_draft"] = "Your refund request has been reviewed and declined by a customer service manager."
self.state["step"] = "DRAFT_RESPONSE"
# Resume the workflow loop
return self.run(self.state["user_id"], "")
def _execute_refund(self):
amount = self.state["refund_amount"]
# Trigger actual external API call/Stripe integration here
self.state["log"].append(f"Successfully processed stripe refund for ${amount}.")
self.state["response_draft"] = f"Your refund request for ${amount} has been successfully processed."
self.state["step"] = "DRAFT_RESPONSE"
def _draft_response(self):
# Prompt LLM to draft a polite, personalized message incorporating response_draft
self.state["final_message"] = f"Dear Customer,\n\n{self.state['response_draft']}\n\nBest regards,\nGhaznix Support Agent"
self.state["step"] = "COMPLETE"
self.state["log"].append("Customer email drafted successfully. Workflow complete.")
5. 本番環境の信頼性とセキュリティ ガードレール
自律システムを導入するには、テストとエラー処理についての考え方を変える必要があります。実稼働システムに組み込む必要がある重要なガードレールは次のとおりです。
A. 暴走実行ループの防止
エラーやエッジケースが発生した自律エージェントは、同じツールに繰り返しクエリを実行し、数分で数千ドルの API コストを費やす可能性があります。
- 解決策: 最大実行制限を実装します。ワークフロー インスタンスごとに許可されるステップ数または合計モデル トークンのハード シーリング (最大 10 回の反復など) を常に定義します。
B. 構造スキーマの検証
LLM は確率的なものであり、有効な JSON や一致するスキーマなどの構造化された出力を当然保証するものではありません。
- 解決策: Pydantic、Instructor、Outlines などの検証ライブラリを使用して、推論レベルで構造を強制します。モデルが無効なスキーマを出力した場合は、それを早期に拒否し、解析エラーを発生させてモデル自体を修正するように促します (評価者とオプティマイザーのループの一部)。
C. コードのサンドボックス実行
エージェントがコード (データ分析やデータベース変換など) を作成して実行する場合、それをアプリケーション サーバー上で直接実行すると、重大なセキュリティ上の脆弱性になります。
- 解決策: 安全な一時的なマイクロ VM 環境 (Docker コンテナー、gVisor、WASM ランタイムなど) を使用して、ユーザー生成またはエージェント生成のスクリプトを安全に実行します。
## 結論
LLM を使用して自律的な AI ワークフローを構築するには、柔軟な AI 推論と構造化されたエンジニアリング分野の間のギャップを埋める必要があります。オープンエンドのエージェントをステートマシン主導のワークフローに置き換え、Orchestrator-Workers のようなパターンでタスクを構造化し、すべてを厳密な実行とセキュリティのガードレールで包み込むことにより、開発者は高度にインテリジェントでエンタープライズ対応のシステムを構築できます。
ソフトウェア アーキテクチャの未来は、コードをプロンプトに置き換えることではなく、エージェントと決定論的なシステムを調整して、自律的に動作し、動的に学習し、結果を確実に提供するワークフローを構築することです。