与法学硕士构建自主人工智能工作流程

大型语言模型 (LLM) 改变了我们与技术交互的方式,从简单的会话聊天机器人迅速转变为能够驱动复杂、多步骤操作的推理引擎。虽然单个提示响应交互可能很强大,但生成式人工智能在企业环境中的真正价值在于自主人工智能工作流程。
自主工作流程不是依靠人类操作员来协调每一步,而是使用法学硕士作为中央决策者,长期规划、执行、评估和自我纠正任务。
本次深入探讨了如何使用现代设计模式、状态机和强大的护栏来架构、构建和部署可靠的自主人工智能工作流程。
1. 代理转变:聊天机器人与工作流程
LLM申请的演变可以分为四个不同的自主级别:
| 水平 | 范式 | 人类角色 | 核心机制 |
|---|---|---|---|
| 1 级 | 对话式聊天 | 高(每回合提示) | 无状态单轮完成 |
| 2 级 | 工具调用/函数调用 | 中等(提供上下文) | 模型选择API调用;返回结果 |
| 3级 | 定向工作流程 | 低(定义目标和图表) | 带有 LLM 路由的硬编码状态机 |
| 4级 | 完全自主的代理 | 最小(定义目标/预算) | LLM驱动的规划、执行和反思循环 |
虽然 4 级代理非常灵活,但众所周知,它们在生产环境中很难预测。因此,大多数企业架构都建立在第三级:定向工作流之上,将软件状态机的确定性可靠性与法学硕士的动态推理相结合。
2. 自主工作流程的核心支柱
要构建自主工作流程,您需要结合四个基本组件:
A. 推理与规划
工作流程的核心是规划范例。幼稚的 LLM 调用会尝试立即输出最终答案,这通常会导致推理失败。自主工作流程使用专门的规划循环:
- ReAct (Reason + Act):模型迭代地思考、行动(调用工具)、观察结果,重复这个循环,直到达到目标。
- 思想链 (CoT):强制模型在得出结论之前*输出其逐步推理。
- 思想树 (ToT):生成和评估多个替代路径,跟踪不同的分支,并在路径失败时回溯。
B. 短期和长期记忆
自治系统必须在多个执行周期中维护状态:
- 短期内存:跟踪工作流当前正在执行的操作的线程上下文、状态变量和执行日志。
- 长期记忆:矢量数据库和语义检索系统,允许工作流程调用历史运行、用户首选项和企业文档。
C. 工具和 Web 集成
为了在物理或数字世界中采取行动,法学硕士必须与外部服务交互。该模型需要访问数据库驱动程序、文件系统、Web 浏览器和第三方 API。现代工作流程越来越多地采用模型上下文协议 (MCP),标准化法学硕士如何发现并安全连接到上下文数据源和执行沙箱。
3. 关键架构设计模式
在构建复杂的代理系统时,软件工程师依靠一组经过验证的设计模式来管理复杂性并保持可预测性:
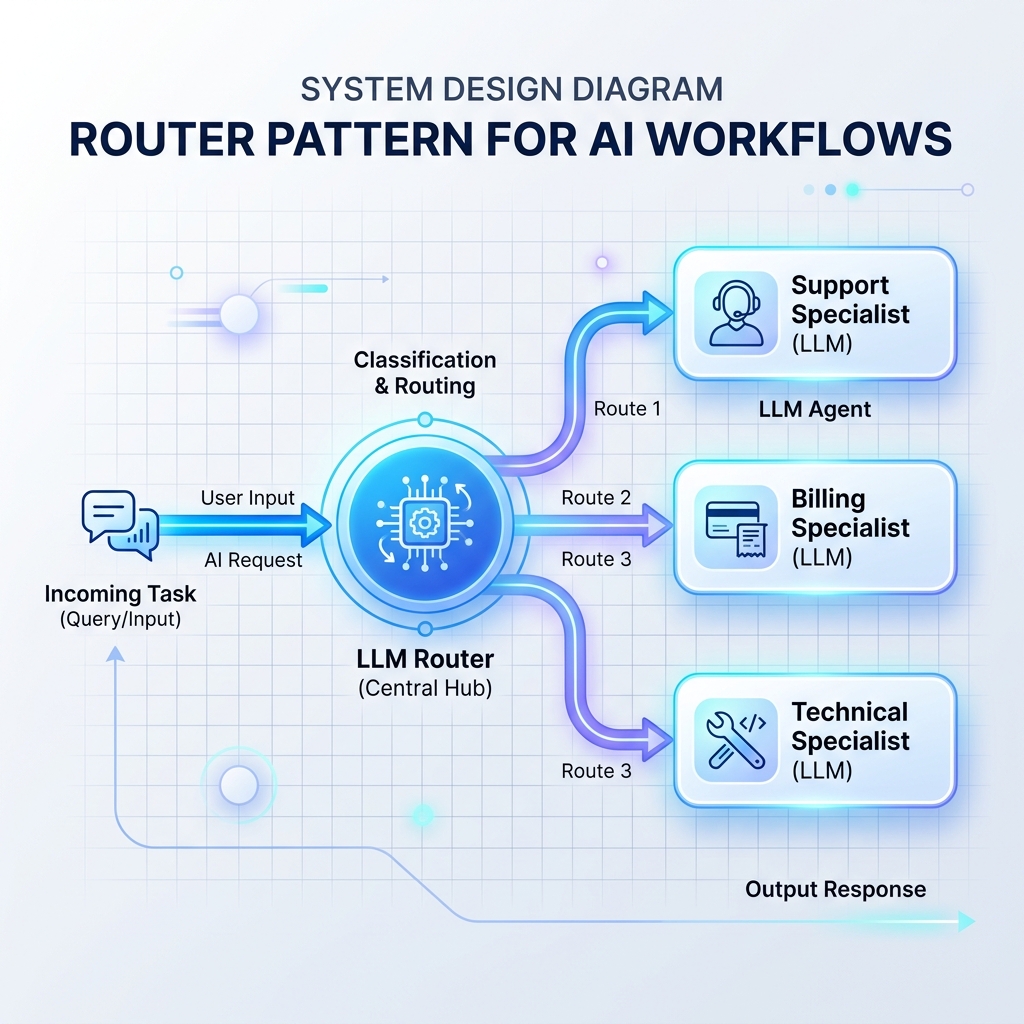
模式 1:路由器模式
路由器读取传入的输入,并决定接下来应由哪个专门的 LLM 提示符、数据库或 API 处理程序来处理它。这可以防止单个整体 LLM 提示因过多指令而过载。
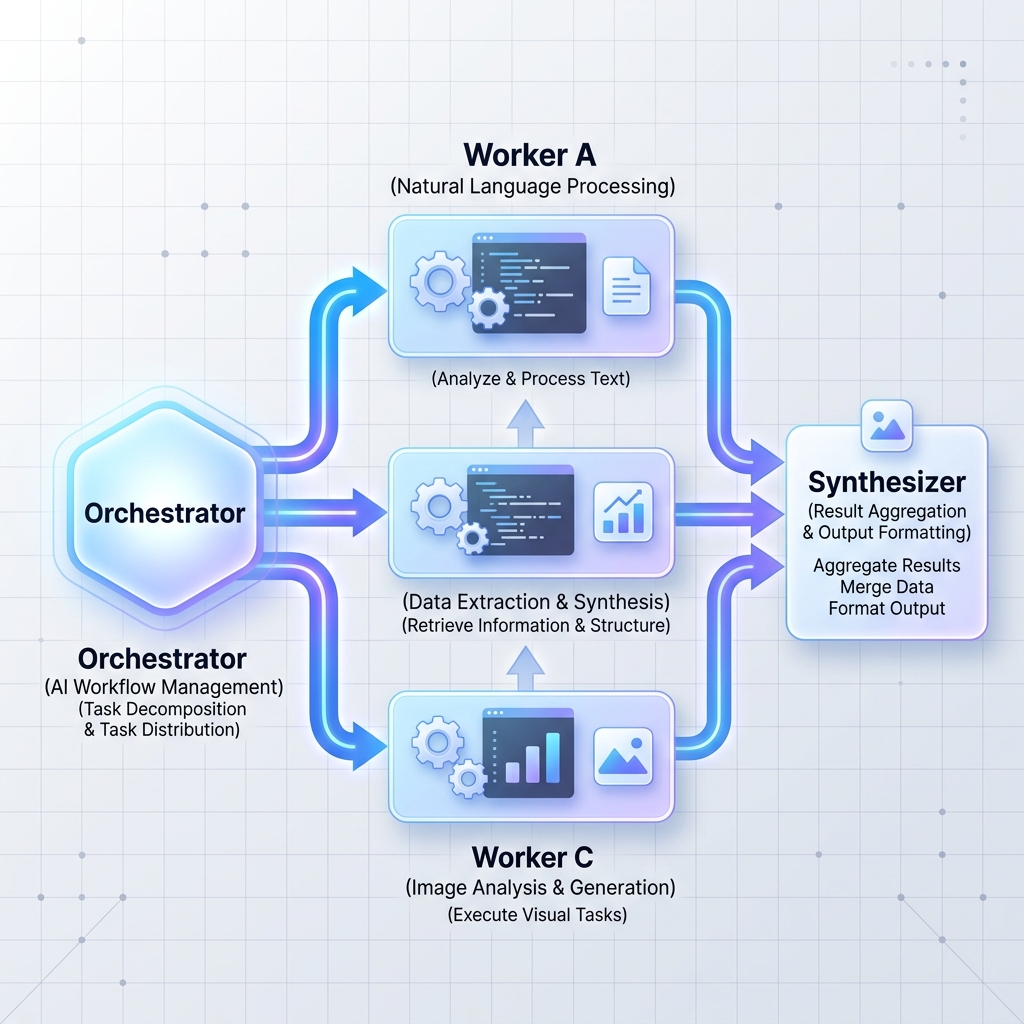
模式 2:协调者-工作者
中央协调器法学硕士将大型复杂的任务分解为独立的子任务。然后,它将这些任务委托给工作节点(可以是专门的 LLM 或标准微服务)并综合结果。
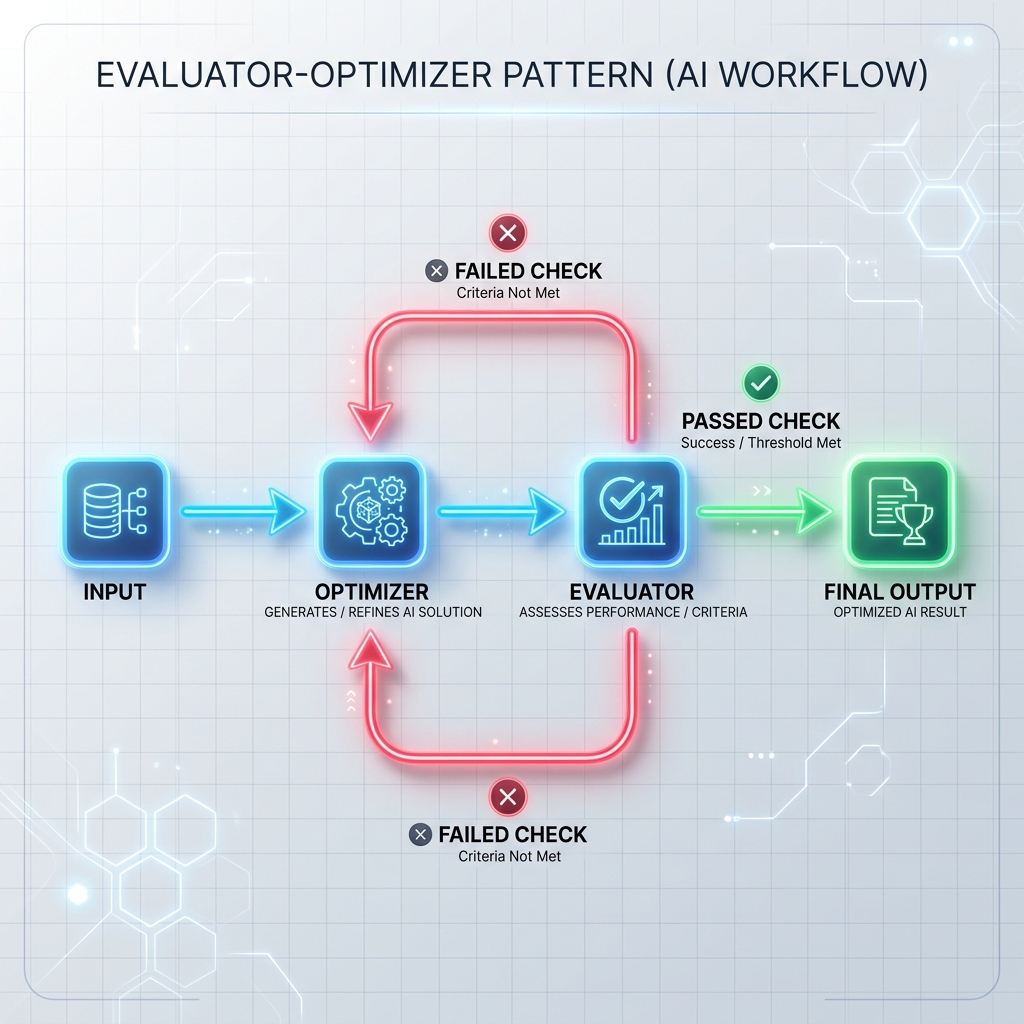
模式 3:评估器-优化器循环
优化器生成草稿响应或执行任务,评估器根据正式标准(如单元测试、安全扫描器或单独的评估提示)对其进行检查。如果检查失败,反馈将传递回优化器以重新生成响应。
4. 用 Python 构建基于状态的代理
让我们看一下使用简单状态机的自主代理的具体实现。我们将定义一个处理退款请求的代理。代理会检查客户的购买历史记录,根据政策验证请求,起草电子邮件回复,并在退款超过 100 美元时请求人工批准。
import json
from typing import Dict, Any
# Mock databases and tools
PURCHASE_DB = {
"user_123": {"item": "Premium Subscription", "price": 149.00, "days_ago": 12},
"user_456": {"item": "Basic License", "price": 49.00, "days_ago": 45}
}
class AutonomousRefundAgent:
def __init__(self):
self.state: Dict[str, Any] = {
"step": "INIT",
"user_id": None,
"refund_amount": 0.0,
"policy_passed": False,
"requires_approval": False,
"approved": False,
"response_draft": "",
"log": []
}
def run(self, user_id: str, request_text: str):
self.state["user_id"] = user_id
self.state["log"].append(f"Started workflow for user {user_id} with request: '{request_text}'")
while self.state["step"] != "COMPLETE":
current_step = self.state["step"]
if current_step == "INIT":
self._fetch_user_data()
elif current_step == "VALIDATE_POLICY":
self._validate_policy()
elif current_step == "CHECK_APPROVAL":
self._check_approval_requirements()
elif current_step == "WAITING_FOR_HUMAN":
# Pause execution and yield control back to the orchestrator
self.state["log"].append("Execution paused: waiting for human operator approval.")
break
elif current_step == "EXECUTE_REFUND":
self._execute_refund()
elif current_step == "DRAFT_RESPONSE":
self._draft_response()
return self.state
def _fetch_user_data(self):
user_id = self.state["user_id"]
purchase = PURCHASE_DB.get(user_id)
if not purchase:
self.state["response_draft"] = "No purchase history found for this user."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Fetch failed: User not found in database.")
return
self.state["refund_amount"] = purchase["price"]
self.state["purchase_age_days"] = purchase["days_ago"]
self.state["step"] = "VALIDATE_POLICY"
self.state["log"].append(f"Fetched purchase data: {purchase}")
def _validate_policy(self):
# Business rule: Refunds only allowed within 30 days
age = self.state["purchase_age_days"]
if age <= 30:
self.state["policy_passed"] = True
self.state["step"] = "CHECK_APPROVAL"
self.state["log"].append("Policy validation passed (within 30-day window).")
else:
self.state["policy_passed"] = False
self.state["response_draft"] = "Sorry, our policy only allows refunds within 30 days of purchase."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Policy validation failed: Purchase older than 30 days.")
def _check_approval_requirements(self):
# Business rule: Refunds over $100 require human review
amount = self.state["refund_amount"]
if amount > 100.0:
self.state["requires_approval"] = True
self.state["step"] = "WAITING_FOR_HUMAN"
self.state["log"].append(f"Refund of ${amount} exceeds limit. Moving to human approval state.")
else:
self.state["requires_approval"] = False
self.state["step"] = "EXECUTE_REFUND"
self.state["log"].append(f"Refund of ${amount} is within limits. Proceeding to execution.")
def resume_with_human_decision(self, approved: bool):
if self.state["step"] != "WAITING_FOR_HUMAN":
raise ValueError("Agent is not currently waiting for approval.")
self.state["approved"] = approved
self.state["log"].append(f"Human manager decision received: Approved = {approved}")
if approved:
self.state["step"] = "EXECUTE_REFUND"
else:
self.state["response_draft"] = "Your refund request has been reviewed and declined by a customer service manager."
self.state["step"] = "DRAFT_RESPONSE"
# Resume the workflow loop
return self.run(self.state["user_id"], "")
def _execute_refund(self):
amount = self.state["refund_amount"]
# Trigger actual external API call/Stripe integration here
self.state["log"].append(f"Successfully processed stripe refund for ${amount}.")
self.state["response_draft"] = f"Your refund request for ${amount} has been successfully processed."
self.state["step"] = "DRAFT_RESPONSE"
def _draft_response(self):
# Prompt LLM to draft a polite, personalized message incorporating response_draft
self.state["final_message"] = f"Dear Customer,\n\n{self.state['response_draft']}\n\nBest regards,\nGhaznix Support Agent"
self.state["step"] = "COMPLETE"
self.state["log"].append("Customer email drafted successfully. Workflow complete.")
5. 生产可靠性和安全护栏
部署自主系统需要改变我们对测试和错误处理的看法。以下是您必须在任何生产系统中构建的关键护栏:
A. 防止失控执行循环
遇到错误或边缘情况的自治代理可能会重复查询同一工具,从而在几分钟内花费数千美元的 API 成本。
- 解决方案:实施最大执行限制。始终定义每个工作流实例允许的步骤数或总模型令牌的硬性上限(例如,最多 10 次迭代)。
B. 结构模式验证
LLM 是概率性的,自然不能保证结构化输出,例如有效的 JSON 或匹配模式。
- 解决方案:使用 Pydantic、Instructor 或 Outlines 等验证库来强制推理级别的结构。如果模型输出无效模式,请尽早拒绝它,并提示模型使用解析错误来修复自身(评估器-优化器循环的一部分)。
C. 代码的沙盒执行
如果您的代理编写并运行代码(例如数据分析或数据库转换),则直接在应用程序服务器上运行它是一个主要的安全漏洞。
- 解决方案:使用安全的临时微虚拟机环境(例如 Docker 容器、gVisor 或 WASM 运行时)来安全地运行用户生成或代理生成的脚本。
## 结论
与法学硕士构建自主人工智能工作流程需要弥合灵活的人工智能推理和结构化工程学科之间的差距。通过用状态机引导的工作流程替换开放式代理,通过 Orchestrator-Workers 等模式构建任务,并将所有内容包装在严格的执行和安全护栏中,开发人员可以构建高度智能且适合企业使用的系统。
软件架构的未来并不是用提示替换代码,而是协调代理和确定性系统来构建自主运行、动态学习和可靠交付结果的工作流程。