LLM을 사용하여 자율 AI 워크플로 구축

LLM(대형 언어 모델)은 간단한 대화형 챗봇에서 복잡하고 다단계 작업을 수행할 수 있는 추론 엔진으로 빠르게 이동하여 기술과 상호 작용하는 방식을 변화시켰습니다. 단일한 신속한 대응 상호작용은 강력할 수 있지만 기업 환경에서 생성 AI의 실제 가치는 자율 AI 워크플로에 있습니다.
모든 단계를 조율하기 위해 인간 운영자에게 의존하는 대신 자율 워크플로는 LLM을 장기간에 걸쳐 작업을 계획, 실행, 평가 및 자체 수정하는 중앙 의사 결정자로 사용합니다.
이 심층 분석에서는 최신 디자인 패턴, 상태 머신 및 강력한 가드레일을 사용하여 안정적인 자율 AI 워크플로를 설계, 구축 및 배포하는 방법을 살펴봅니다.
1. 에이전트의 변화: 챗봇과 워크플로
LLM 응용 프로그램의 발전은 네 가지 수준의 자율성으로 분류될 수 있습니다.
| 레벨 | 패러다임 | 인간의 역할 | 핵심 메커니즘 |
|---|---|---|---|
| 레벨 1 | 대화채팅 | 높음(매 턴마다 프롬프트) | 무상태 단일 턴 완료 |
| 레벨 2 | 도구 호출/함수 호출 | 중간(맥락 제공) | 모델은 호출할 API를 선택합니다. 결과를 반환 |
| 레벨 3 | 지시된 워크플로우 | 낮음(목표 및 그래프 정의) | LLM 라우팅이 포함된 하드코딩된 상태 머신 |
| 레벨 4 | 완전 자율 에이전트 | 최소(목표/예산 정의) | LLM 기반 계획, 실행 및 반영 루프 |
레벨 4 에이전트는 매우 유연하지만 프로덕션 환경에서는 예측하기가 매우 어렵습니다. 따라서 대부분의 엔터프라이즈 아키텍처는 소프트웨어 상태 시스템의 결정론적 신뢰성과 LLM의 동적 추론을 결합한 레벨 3: 지시된 워크플로를 기반으로 구축됩니다.
2. 자율적 워크플로의 핵심 요소
자율적인 워크플로를 구축하려면 다음 네 가지 기본 구성 요소를 결합해야 합니다.
A. 추론 및 계획
워크플로우의 중심에는 계획 패러다임이 있습니다. 순진한 LLM 호출은 최종 답을 즉시 출력하려고 시도하는데, 이는 종종 추론 실패로 이어집니다. 자율 워크플로우는 특수 계획 루프를 사용합니다.
- ReAct(Reason + Act): 모델은 반복적으로 생각하고, 행동하고(도구 호출) 결과를 관찰하며 목표가 달성될 때까지 이 루프를 반복합니다.
- CoT(사고 사슬): 결론에 도달하기 전에 모델이 단계별 추론을 출력하도록 합니다.
- 생각의 나무(ToT): 여러 대체 경로를 생성 및 평가하고, 다양한 분기를 추적하고, 경로가 실패할 때 역추적합니다.
B. 단기 및 장기 기억
자율 시스템은 여러 실행 주기에 걸쳐 상태를 유지해야 합니다.
- 단기 메모리: 워크플로가 현재 수행 중인 작업을 추적하는 스레드 컨텍스트, 상태 변수 및 실행 로그입니다.
- 장기 메모리: 워크플로에서 기록 실행, 사용자 기본 설정 및 기업 문서를 불러올 수 있는 벡터 데이터베이스 및 의미 검색 시스템입니다.
C. 도구 및 웹 통합
실제 세계나 디지털 세계에서 활동하려면 LLM은 외부 서비스와 인터페이스해야 합니다. 모델에는 데이터베이스 드라이버, 파일 시스템, 웹 브라우저 및 타사 API에 대한 액세스가 필요합니다. 최신 워크플로에서는 LLM이 상황별 데이터 소스 및 실행 샌드박스를 검색하고 안전하게 연결하는 방법을 표준화하는 **모델 컨텍스트 프로토콜(MCP)**을 점점 더 많이 채택하고 있습니다.
3. 주요 아키텍처 디자인 패턴
복잡한 에이전트 시스템을 구축할 때 소프트웨어 엔지니어는 입증된 설계 패턴 세트를 사용하여 복잡성을 관리하고 예측 가능성을 유지합니다.
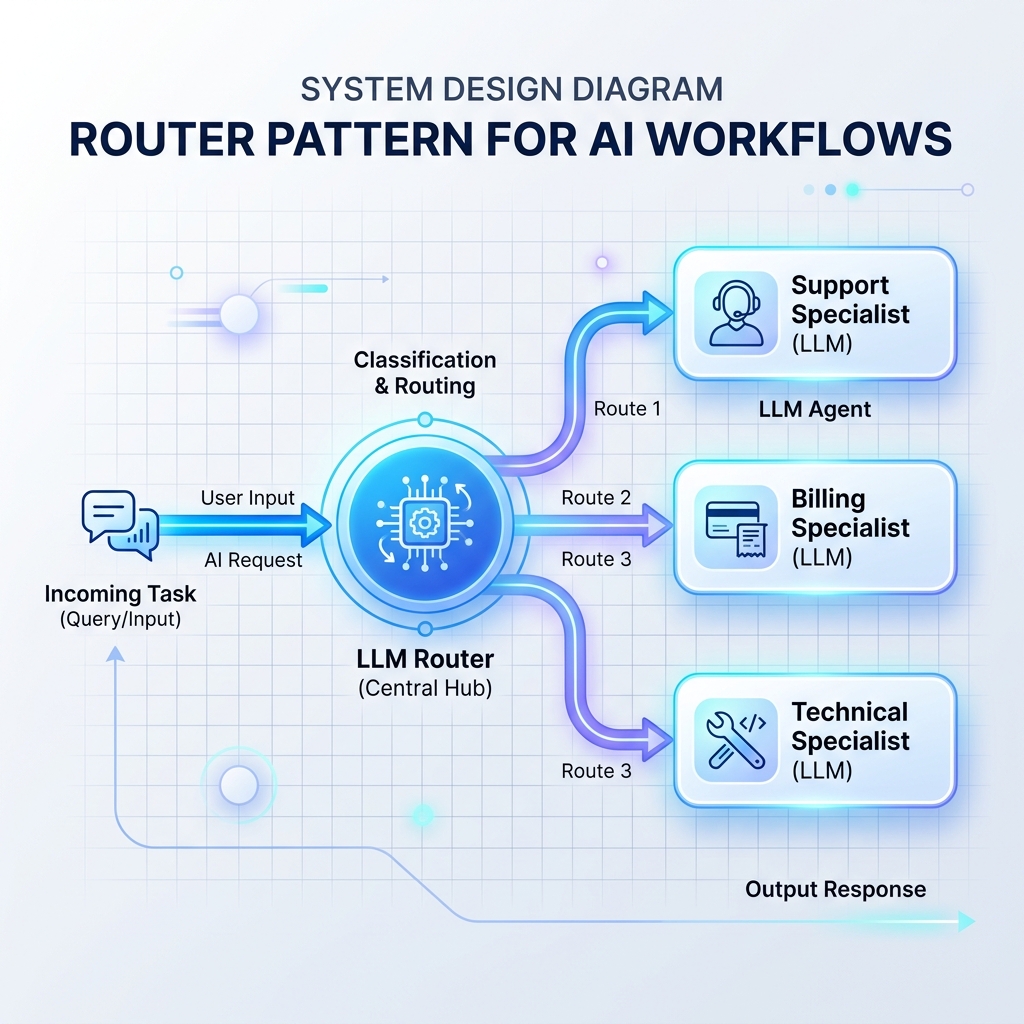
패턴 1: 라우터 패턴
라우터는 들어오는 입력을 읽고 다음에 이를 처리할 특수 LLM 프롬프트, 데이터베이스 또는 API 처리기를 결정합니다. 이렇게 하면 단일 모놀리식 LLM 프롬프트가 너무 많은 지침으로 인해 과부하되는 것을 방지할 수 있습니다.
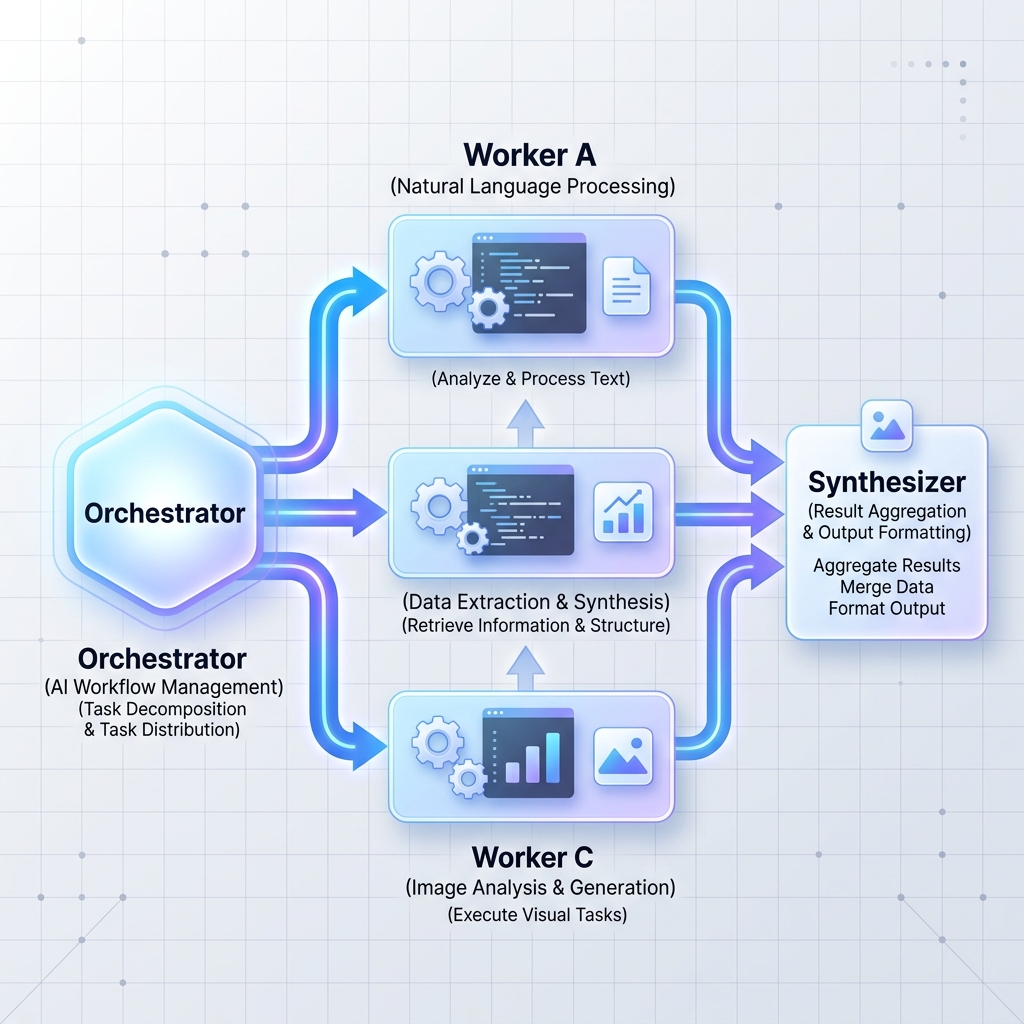
패턴 2: 오케스트레이터-작업자
중앙 오케스트레이터 LLM은 크고 복잡한 작업을 독립적인 하위 작업으로 나눕니다. 그런 다음 이러한 작업을 작업자 노드(특수 LLM 또는 표준 마이크로서비스일 수 있음)에 위임하고 결과를 종합합니다.
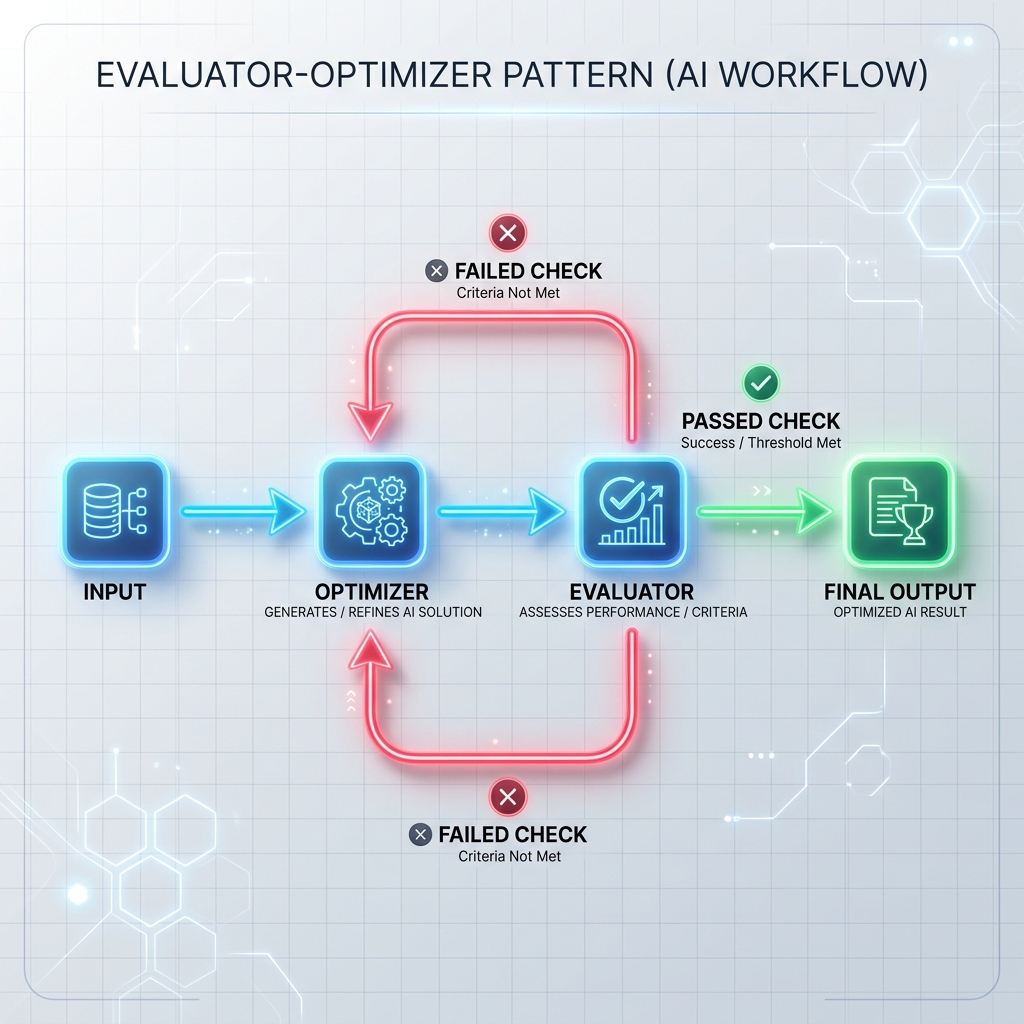
패턴 3: 평가자-최적화자 루프
최적화 프로그램은 초안 응답을 생성하거나 작업을 실행하고 평가자는 이를 공식 기준(예: 단위 테스트, 보안 스캐너 또는 별도의 평가 프롬프트)과 비교하여 확인합니다. 검사가 실패하면 피드백이 최적화 프로그램으로 다시 전달되어 응답을 재생성합니다.
4. Python에서 상태 기반 에이전트 구축
간단한 상태 머신을 사용하여 자율 에이전트의 구체적인 구현을 살펴보겠습니다. 환불 요청을 처리하는 에이전트를 정의하겠습니다. 상담원은 고객의 구매 내역을 확인하고, 정책에 따라 요청을 검증하고, 이메일 응답 초안을 작성하고, 환불 금액이 $100를 초과하는 경우 사람의 승인을 요청합니다.
import json
from typing import Dict, Any
# Mock databases and tools
PURCHASE_DB = {
"user_123": {"item": "Premium Subscription", "price": 149.00, "days_ago": 12},
"user_456": {"item": "Basic License", "price": 49.00, "days_ago": 45}
}
class AutonomousRefundAgent:
def __init__(self):
self.state: Dict[str, Any] = {
"step": "INIT",
"user_id": None,
"refund_amount": 0.0,
"policy_passed": False,
"requires_approval": False,
"approved": False,
"response_draft": "",
"log": []
}
def run(self, user_id: str, request_text: str):
self.state["user_id"] = user_id
self.state["log"].append(f"Started workflow for user {user_id} with request: '{request_text}'")
while self.state["step"] != "COMPLETE":
current_step = self.state["step"]
if current_step == "INIT":
self._fetch_user_data()
elif current_step == "VALIDATE_POLICY":
self._validate_policy()
elif current_step == "CHECK_APPROVAL":
self._check_approval_requirements()
elif current_step == "WAITING_FOR_HUMAN":
# Pause execution and yield control back to the orchestrator
self.state["log"].append("Execution paused: waiting for human operator approval.")
break
elif current_step == "EXECUTE_REFUND":
self._execute_refund()
elif current_step == "DRAFT_RESPONSE":
self._draft_response()
return self.state
def _fetch_user_data(self):
user_id = self.state["user_id"]
purchase = PURCHASE_DB.get(user_id)
if not purchase:
self.state["response_draft"] = "No purchase history found for this user."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Fetch failed: User not found in database.")
return
self.state["refund_amount"] = purchase["price"]
self.state["purchase_age_days"] = purchase["days_ago"]
self.state["step"] = "VALIDATE_POLICY"
self.state["log"].append(f"Fetched purchase data: {purchase}")
def _validate_policy(self):
# Business rule: Refunds only allowed within 30 days
age = self.state["purchase_age_days"]
if age <= 30:
self.state["policy_passed"] = True
self.state["step"] = "CHECK_APPROVAL"
self.state["log"].append("Policy validation passed (within 30-day window).")
else:
self.state["policy_passed"] = False
self.state["response_draft"] = "Sorry, our policy only allows refunds within 30 days of purchase."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Policy validation failed: Purchase older than 30 days.")
def _check_approval_requirements(self):
# Business rule: Refunds over $100 require human review
amount = self.state["refund_amount"]
if amount > 100.0:
self.state["requires_approval"] = True
self.state["step"] = "WAITING_FOR_HUMAN"
self.state["log"].append(f"Refund of ${amount} exceeds limit. Moving to human approval state.")
else:
self.state["requires_approval"] = False
self.state["step"] = "EXECUTE_REFUND"
self.state["log"].append(f"Refund of ${amount} is within limits. Proceeding to execution.")
def resume_with_human_decision(self, approved: bool):
if self.state["step"] != "WAITING_FOR_HUMAN":
raise ValueError("Agent is not currently waiting for approval.")
self.state["approved"] = approved
self.state["log"].append(f"Human manager decision received: Approved = {approved}")
if approved:
self.state["step"] = "EXECUTE_REFUND"
else:
self.state["response_draft"] = "Your refund request has been reviewed and declined by a customer service manager."
self.state["step"] = "DRAFT_RESPONSE"
# Resume the workflow loop
return self.run(self.state["user_id"], "")
def _execute_refund(self):
amount = self.state["refund_amount"]
# Trigger actual external API call/Stripe integration here
self.state["log"].append(f"Successfully processed stripe refund for ${amount}.")
self.state["response_draft"] = f"Your refund request for ${amount} has been successfully processed."
self.state["step"] = "DRAFT_RESPONSE"
def _draft_response(self):
# Prompt LLM to draft a polite, personalized message incorporating response_draft
self.state["final_message"] = f"Dear Customer,\n\n{self.state['response_draft']}\n\nBest regards,\nGhaznix Support Agent"
self.state["step"] = "COMPLETE"
self.state["log"].append("Customer email drafted successfully. Workflow complete.")
5. 생산 신뢰성 및 보안 가드레일
자율 시스템을 배포하려면 테스트 및 오류 처리에 대한 생각의 변화가 필요합니다. 모든 프로덕션 시스템에 구축해야 하는 중요한 가드레일은 다음과 같습니다.
A. 폭주 실행 루프 방지
오류나 극단적인 경우가 발생한 자율 에이전트는 동일한 도구를 반복적으로 쿼리하여 몇 분 만에 API 비용으로 수천 달러를 소비할 수 있습니다.
- 해결책: 최대 실행 제한을 구현합니다. 항상 워크플로 인스턴스당 허용되는 단계 수 또는 총 모델 토큰에 대한 엄격한 한도를 정의합니다(예: 최대 10회 반복).
B. 구조적 스키마 검증
LLM은 확률적이며 유효한 JSON이나 일치하는 스키마와 같은 구조화된 출력을 자연스럽게 보장하지 않습니다.
- 해결책: Pydantic, Instructor 또는 Outlines와 같은 검증 라이브러리를 사용하여 추론 수준에서 구조를 적용합니다. 모델이 유효하지 않은 스키마를 출력하는 경우 이를 조기에 거부하고 구문 분석 오류가 있는 모델에 자체 수정을 요청합니다(Evaluator-Optimizer 루프의 일부).
C. 샌드박스 코드 실행
에이전트가 코드(예: 데이터 분석 또는 데이터베이스 변환)를 작성하고 실행하는 경우 이를 애플리케이션 서버에서 직접 실행하는 것은 주요 보안 취약점입니다.
- 해결책: 안전한 임시 마이크로 VM 환경(예: Docker 컨테이너, gVisor 또는 WASM 런타임)을 사용하여 사용자 생성 또는 에이전트 생성 스크립트를 안전하게 실행하세요.
결론
LLM을 사용하여 자율 AI 워크플로를 구축하려면 유연한 AI 추론과 구조화된 엔지니어링 분야 간의 격차를 해소해야 합니다. 개방형 에이전트를 상태 머신 지정 워크플로로 교체하고, Orchestrator-Workers와 같은 패턴을 통해 작업을 구조화하고, 엄격한 실행 및 보안 가드레일로 모든 것을 래핑함으로써 개발자는 고도로 지능적이고 엔터프라이즈급 시스템을 구축할 수 있습니다.
소프트웨어 아키텍처의 미래는 코드를 프롬프트로 바꾸는 것이 아니라 에이전트와 결정론적 시스템을 조정하여 자율적으로 작동하고 동적으로 학습하며 결과를 안정적으로 제공하는 워크플로를 구축하는 것입니다.