Aufbau autonomer KI-Workflows mit LLMs

Large Language Models (LLMs) haben die Art und Weise, wie wir mit Technologie interagieren, verändert und sich schnell von einfachen Konversations-Chatbots zu Reasoning Engines entwickelt, die komplexe, mehrstufige Aktionen steuern können. Während eine einzelne Prompt-Response-Interaktion leistungsstark sein kann, liegt der wahre Wert generativer KI in Unternehmensumgebungen in autonomen KI-Workflows.
Anstatt sich auf menschliche Bediener zu verlassen, die jeden Schritt orchestrieren, nutzen autonome Arbeitsabläufe LLMs als zentrale Entscheidungsträger, die Aufgaben über lange Zeiträume planen, ausführen, bewerten und selbst korrigieren.
In diesem ausführlichen Tauchgang wird untersucht, wie man mithilfe moderner Entwurfsmuster, Zustandsautomaten und robuster Leitplanken zuverlässige autonome KI-Workflows entwerfen, erstellen und bereitstellen kann.
1. Der Agentenwandel: Chatbots vs. Workflows
Die Entwicklung von LLM-Anwendungen kann in vier verschiedene Autonomieebenen eingeteilt werden:
| Ebene | Paradigma | Menschliche Rolle | Kernmechanismus |
|---|---|---|---|
| Stufe 1 | Konversationschat | Hoch (Prompt bei jeder Drehung) | Zustandslose Single-Turn-Abschlüsse |
| Stufe 2 | Werkzeugaufruf / Funktionsaufruf | Mittel (Stellt Kontext bereit) | Das Modell wählt die aufzurufende API aus. gibt Ergebnis |
| Stufe 3 | Gezielte Arbeitsabläufe | Niedrig (Definiert Ziele und Diagramm) | Hartcodierte Zustandsmaschine mit LLM-Routing |
| Stufe 4 | Vollständig autonome Agenten | Minimal (Definiert Ziel/Budget) | LLM-gesteuerte Planungs-, Ausführungs- und Reflexionsschleifen |
Obwohl Agenten der Stufe 4 äußerst flexibel sind, sind sie in Produktionsumgebungen bekanntermaßen schwer vorherzusagen. Daher basieren die meisten Unternehmensarchitekturen auf Level 3: Directed Workflows und kombinieren die deterministische Zuverlässigkeit von Software-Zustandsmaschinen mit der dynamischen Argumentation von LLMs.
2. Kernsäulen autonomer Arbeitsabläufe
Um einen autonomen Workflow aufzubauen, müssen Sie vier grundlegende Komponenten kombinieren:
A. Argumentation und Planung
Im Mittelpunkt des Arbeitsablaufs steht das Planungsparadigma. Ein naiver LLM-Aufruf versucht, die endgültige Antwort sofort auszugeben, was häufig zu Argumentationsfehlern führt. Autonome Arbeitsabläufe nutzen spezielle Planungsschleifen:
- ReAct (Reason + Act): Das Modell denkt iterativ, handelt (ruft ein Werkzeug auf) und beobachtet das Ergebnis, wobei diese Schleife wiederholt wird, bis das Ziel erreicht ist.
- Gedankenkette (CoT): Das Modell wird gezwungen, seine schrittweisen Überlegungen auszugeben, bevor zu einer Schlussfolgerung gelangt.
- Tree of Thoughts (ToT): Generieren und Bewerten mehrerer alternativer Pfade, Verfolgen verschiedener Zweige und Zurückverfolgen, wenn ein Pfad fehlschlägt.
B. Kurzzeit- und Langzeitgedächtnis
Ein autonomes System muss seinen Zustand über mehrere Ausführungszyklen hinweg aufrechterhalten:
- Kurzzeitgedächtnis: Der Thread-Kontext, Statusvariablen und Ausführungsprotokolle, die verfolgen, was der Workflow gerade tut.
- Langzeitspeicher: Vektordatenbanken und semantische Abrufsysteme, die es dem Workflow ermöglichen, historische Ausführungen, Benutzereinstellungen und Unternehmensdokumentation abzurufen.
C. Tools und Webintegration
Um auf die physische oder digitale Welt einzuwirken, müssen LLMs mit externen Diensten interagieren. Das Modell benötigt Zugriff auf Datenbanktreiber, Dateisysteme, Webbrowser und APIs von Drittanbietern. Moderne Arbeitsabläufe übernehmen zunehmend das Model Context Protocol (MCP) und standardisieren damit, wie LLMs kontextbezogene Datenquellen und Ausführungssandboxen erkennen und sicher eine Verbindung zu ihnen herstellen.
3. Wichtige architektonische Designmuster
Beim Aufbau komplexer Agentensysteme verlassen sich Softwareentwickler auf eine Reihe bewährter Entwurfsmuster, um die Komplexität zu bewältigen und die Vorhersagbarkeit aufrechtzuerhalten:
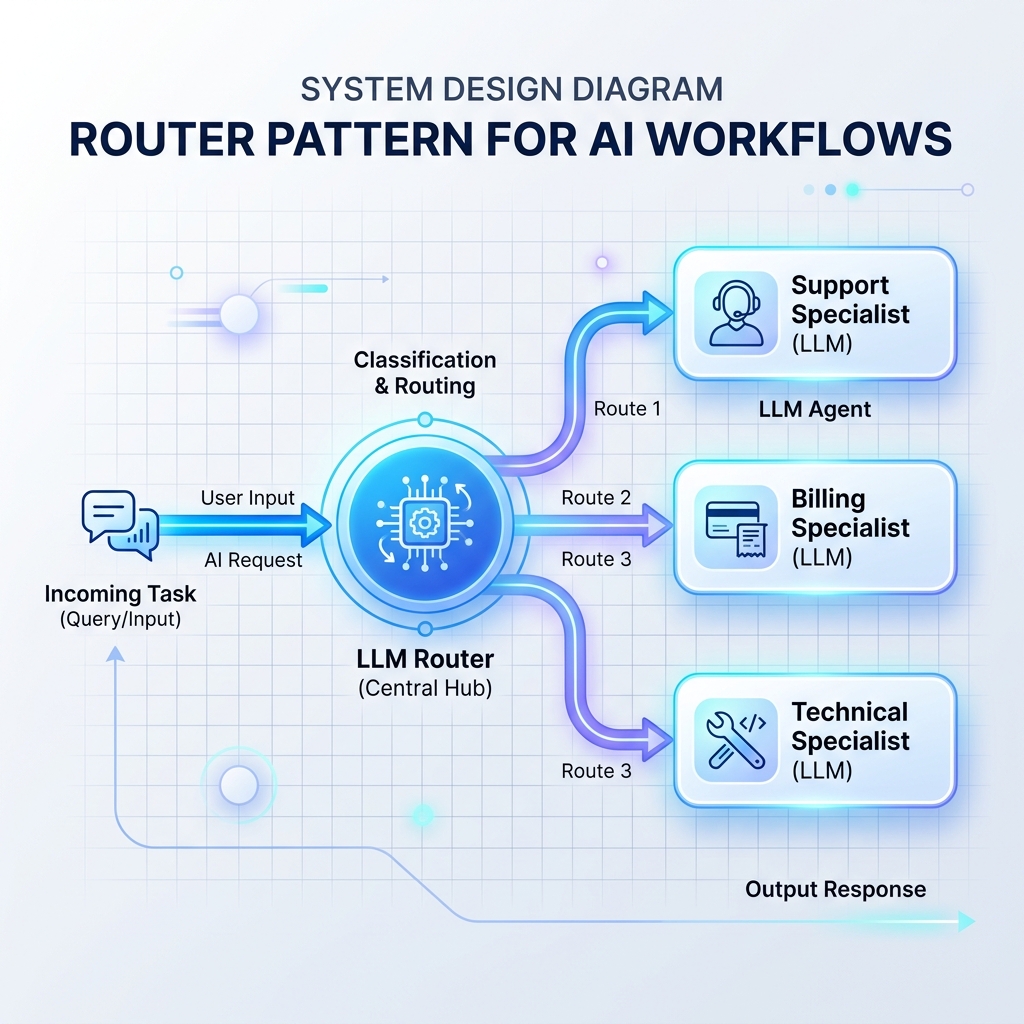
Muster 1: Das Router-Muster
Ein Router liest eingehende Eingaben und entscheidet, welcher spezielle LLM-Prompt, welche Datenbank oder welcher API-Handler sie als Nächstes verarbeiten soll. Dadurch wird verhindert, dass eine einzelne, monolithische LLM-Eingabeaufforderung mit zu vielen Anweisungen überlastet wird.
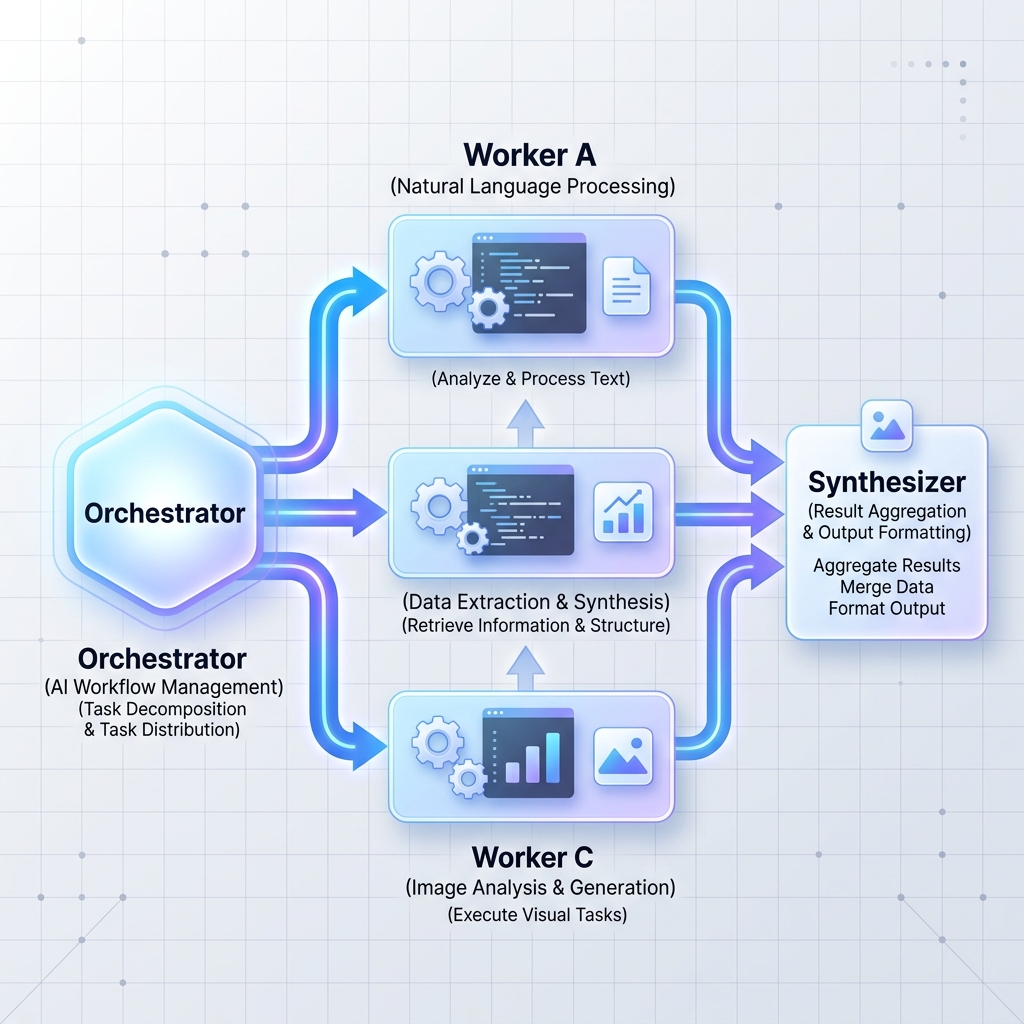
Muster 2: Orchestrator-Worker
Ein zentraler Orchestrator-LLM unterteilt eine große, komplexe Aufgabe in unabhängige Unteraufgaben. Anschließend delegiert es diese Aufgaben an Worker-Knoten (bei denen es sich um spezialisierte LLMs oder Standard-Microservices handeln kann) und synthetisiert die Ergebnisse.
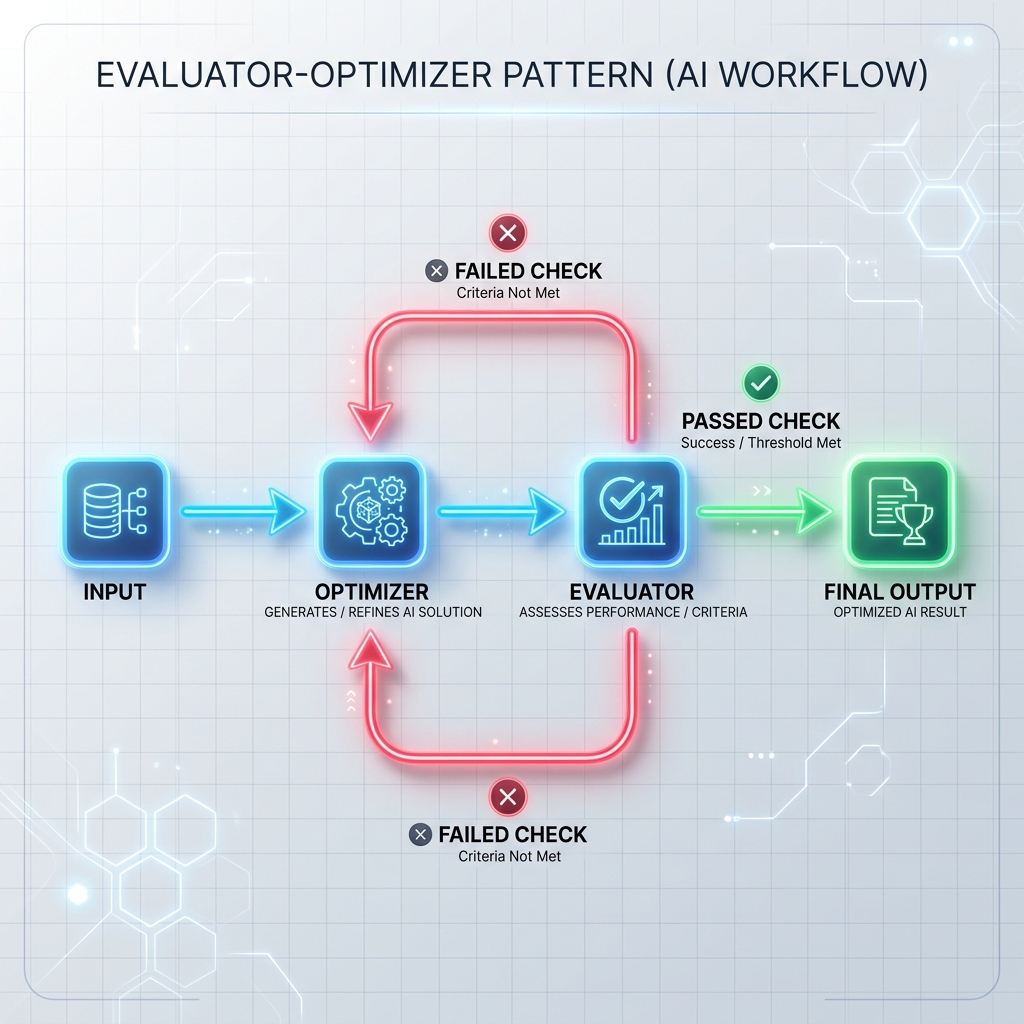
Muster 3: Evaluator-Optimizer-Schleife
Der Optimierer generiert einen Antwortentwurf oder führt eine Aufgabe aus, und der Evaluator prüft ihn anhand formaler Kriterien (z. B. Komponententests, Sicherheitsscanner oder eine separate Evaluierungsaufforderung). Wenn die Prüfung fehlschlägt, wird das Feedback an den Optimierer zurückgegeben, um die Antwort neu zu generieren.
4. Erstellen eines zustandsbasierten Agenten in Python
Schauen wir uns eine konkrete Implementierung eines autonomen Agenten unter Verwendung einer einfachen Zustandsmaschine an. Wir definieren einen Agenten, der Rückerstattungsanträge bearbeitet. Der Agent überprüft die Kaufhistorie des Kunden, validiert die Anfrage anhand der Richtlinien, erstellt eine E-Mail-Antwort und fordert die menschliche Genehmigung an, wenn die Rückerstattung 100 US-Dollar übersteigt.
import json
from typing import Dict, Any
# Mock databases and tools
PURCHASE_DB = {
"user_123": {"item": "Premium Subscription", "price": 149.00, "days_ago": 12},
"user_456": {"item": "Basic License", "price": 49.00, "days_ago": 45}
}
class AutonomousRefundAgent:
def __init__(self):
self.state: Dict[str, Any] = {
"step": "INIT",
"user_id": None,
"refund_amount": 0.0,
"policy_passed": False,
"requires_approval": False,
"approved": False,
"response_draft": "",
"log": []
}
def run(self, user_id: str, request_text: str):
self.state["user_id"] = user_id
self.state["log"].append(f"Started workflow for user {user_id} with request: '{request_text}'")
while self.state["step"] != "COMPLETE":
current_step = self.state["step"]
if current_step == "INIT":
self._fetch_user_data()
elif current_step == "VALIDATE_POLICY":
self._validate_policy()
elif current_step == "CHECK_APPROVAL":
self._check_approval_requirements()
elif current_step == "WAITING_FOR_HUMAN":
# Pause execution and yield control back to the orchestrator
self.state["log"].append("Execution paused: waiting for human operator approval.")
break
elif current_step == "EXECUTE_REFUND":
self._execute_refund()
elif current_step == "DRAFT_RESPONSE":
self._draft_response()
return self.state
def _fetch_user_data(self):
user_id = self.state["user_id"]
purchase = PURCHASE_DB.get(user_id)
if not purchase:
self.state["response_draft"] = "No purchase history found for this user."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Fetch failed: User not found in database.")
return
self.state["refund_amount"] = purchase["price"]
self.state["purchase_age_days"] = purchase["days_ago"]
self.state["step"] = "VALIDATE_POLICY"
self.state["log"].append(f"Fetched purchase data: {purchase}")
def _validate_policy(self):
# Business rule: Refunds only allowed within 30 days
age = self.state["purchase_age_days"]
if age <= 30:
self.state["policy_passed"] = True
self.state["step"] = "CHECK_APPROVAL"
self.state["log"].append("Policy validation passed (within 30-day window).")
else:
self.state["policy_passed"] = False
self.state["response_draft"] = "Sorry, our policy only allows refunds within 30 days of purchase."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Policy validation failed: Purchase older than 30 days.")
def _check_approval_requirements(self):
# Business rule: Refunds over $100 require human review
amount = self.state["refund_amount"]
if amount > 100.0:
self.state["requires_approval"] = True
self.state["step"] = "WAITING_FOR_HUMAN"
self.state["log"].append(f"Refund of ${amount} exceeds limit. Moving to human approval state.")
else:
self.state["requires_approval"] = False
self.state["step"] = "EXECUTE_REFUND"
self.state["log"].append(f"Refund of ${amount} is within limits. Proceeding to execution.")
def resume_with_human_decision(self, approved: bool):
if self.state["step"] != "WAITING_FOR_HUMAN":
raise ValueError("Agent is not currently waiting for approval.")
self.state["approved"] = approved
self.state["log"].append(f"Human manager decision received: Approved = {approved}")
if approved:
self.state["step"] = "EXECUTE_REFUND"
else:
self.state["response_draft"] = "Your refund request has been reviewed and declined by a customer service manager."
self.state["step"] = "DRAFT_RESPONSE"
# Resume the workflow loop
return self.run(self.state["user_id"], "")
def _execute_refund(self):
amount = self.state["refund_amount"]
# Trigger actual external API call/Stripe integration here
self.state["log"].append(f"Successfully processed stripe refund for ${amount}.")
self.state["response_draft"] = f"Your refund request for ${amount} has been successfully processed."
self.state["step"] = "DRAFT_RESPONSE"
def _draft_response(self):
# Prompt LLM to draft a polite, personalized message incorporating response_draft
self.state["final_message"] = f"Dear Customer,\n\n{self.state['response_draft']}\n\nBest regards,\nGhaznix Support Agent"
self.state["step"] = "COMPLETE"
self.state["log"].append("Customer email drafted successfully. Workflow complete.")
5. Produktionszuverlässigkeit und Sicherheitsleitplanken
Der Einsatz autonomer Systeme erfordert eine Änderung unserer Denkweise über Tests und Fehlerbehandlung. Hier sind wichtige Leitplanken, die Sie in jedes Produktionssystem integrieren müssen:
A. Verhindern außer Kontrolle geratener Ausführungsschleifen
Ein autonomer Agent, der auf einen Fehler oder einen Grenzfall stößt, fragt möglicherweise dasselbe Tool wiederholt ab und verursacht innerhalb weniger Minuten Tausende von Dollar an API-Kosten.
- Lösung: Maximale Ausführungslimits implementieren. Definieren Sie immer eine feste Obergrenze für die Anzahl der Schritte oder die Gesamtzahl der pro Workflow-Instanz zulässigen Modell-Tokens (z. B. maximal 10 Iterationen).
B. Validierung des Strukturschemas
LLMs sind probabilistisch und garantieren natürlich keine strukturierten Ausgaben wie gültiges JSON oder passende Schemata.
- Lösung: Verwenden Sie Validierungsbibliotheken wie Pydantic, Instructor oder Outlines, um die Struktur auf der Inferenzebene durchzusetzen. Wenn ein Modell ungültige Schemata ausgibt, lehnen Sie es frühzeitig ab und fordern Sie das Modell mit dem Analysefehler auf, sich selbst zu beheben (Teil der Evaluator-Optimizer-Schleife).
C. Sandbox-Ausführung von Code
Wenn Ihr Agent Code schreibt und ausführt (z. B. Datenanalyse oder Datenbanktransformationen), stellt die direkte Ausführung auf Ihrem Anwendungsserver eine große Sicherheitslücke dar.
- Lösung: Verwenden Sie sichere, kurzlebige Mikro-VM-Umgebungen (wie Docker-Container, gVisor oder WASM-Laufzeiten), um benutzer- oder agentengenerierte Skripte sicher auszuführen.
Abschluss
Der Aufbau autonomer KI-Workflows mit LLMs erfordert die Überbrückung der Lücke zwischen flexiblem KI-Denken und strukturierter Ingenieursdisziplin. Indem Entwickler offene Agenten durch zustandsgesteuerte Workflows ersetzen, Aufgaben über Muster wie Orchestrator-Worker strukturieren und alles in strenge Ausführungs- und Sicherheitsvorschriften einschließen, können Entwickler Systeme erstellen, die sowohl hochintelligent als auch unternehmenstauglich sind.
Bei der Zukunft der Softwarearchitektur geht es nicht darum, Code durch Eingabeaufforderungen zu ersetzen, sondern darum, Agenten und deterministische Systeme zu orchestrieren, um Arbeitsabläufe zu erstellen, die autonom funktionieren, dynamisch lernen und zuverlässig Ergebnisse liefern.