Создание автономных рабочих процессов искусственного интеллекта с помощью LLM

Модели большого языка (LLM) изменили то, как мы взаимодействуем с технологиями, быстро перейдя от простых диалоговых чат-ботов к механизмам рассуждения, способным выполнять сложные, многоэтапные действия. Хотя одно взаимодействие с быстрым ответом может быть мощным, реальная ценность генеративного ИИ в корпоративных условиях заключается в автономных рабочих процессах ИИ.
Вместо того, чтобы полагаться на людей-операторов для координации каждого шага, автономные рабочие процессы используют LLM в качестве центральных лиц, принимающих решения, которые планируют, выполняют, оценивают и самокорректируют задачи в течение длительных периодов времени.
В этом глубоком обзоре рассматривается, как проектировать, создавать и развертывать надежные автономные рабочие процессы искусственного интеллекта с использованием современных шаблонов проектирования, конечных автоматов и надежных защитных ограждений.
1. Агентический сдвиг: чат-боты против рабочих процессов
Эволюцию приложений LLM можно разделить на четыре различных уровня автономии:
| Уровень | Парадигма | Роль человека | Основной механизм |
|---|---|---|---|
| Уровень 1 | Разговорный чат | Высокий (подсказки на каждом ходу) | Однооборотные завершения без сохранения состояния |
| Уровень 2 | Вызов инструмента/вызов функции | Средний (обеспечивает контекст) | Модель выбирает API для вызова; возвращает результат |
| Уровень 3 | Направленные рабочие процессы | Низкий (Определяет цели и график) | Жестко закодированный конечный автомат с маршрутизацией LLM |
| Уровень 4 | Полностью автономные агенты | Минимальный (определяет цель/бюджет) | Циклы планирования, выполнения и анализа на основе LLM |
Хотя агенты уровня 4 обладают высокой гибкостью, их работу крайне сложно прогнозировать в производственных средах. Таким образом, большинство корпоративных архитектур построено на Уровне 3: Направленные рабочие процессы, сочетающем в себе детерминированную надежность конечных автоматов программного обеспечения с динамическим мышлением LLM.
2. Основные принципы автономных рабочих процессов
Чтобы построить автономный рабочий процесс, вам необходимо объединить четыре основополагающих компонента:
A. Обоснование и планирование
В основе рабочего процесса лежит парадигма планирования. Наивный вызов LLM пытается немедленно вывести окончательный ответ, что часто приводит к сбоям в рассуждениях. В автономных рабочих процессах используются специализированные циклы планирования:
- ReAct (Причина + Действие): модель итеративно думает, действует (вызывает инструмент) и наблюдает за результатом, повторяя этот цикл до тех пор, пока цель не будет достигнута.
- Цепочка размышлений (ЦП): принуждение модели выводить пошаговые рассуждения прежде прийти к выводу.
- Древо мыслей (ToT): создание и оценка нескольких альтернативных путей, отслеживание различных ветвей и возврат в случае сбоя пути.
B. Кратковременная и долговременная память
Автономная система должна поддерживать состояние на протяжении нескольких циклов выполнения:
- Кратковременная память: контекст потока, переменные состояния и журналы выполнения, которые отслеживают, что в данный момент делает рабочий процесс.
- Долговременная память: векторные базы данных и системы семантического поиска, которые позволяют рабочему процессу вспоминать исторические запуски, пользовательские настройки и корпоративную документацию.
C. Инструменты и веб-интеграция
Чтобы действовать в физическом или цифровом мире, LLM должны взаимодействовать с внешними сервисами. Модели необходим доступ к драйверам базы данных, файловым системам, веб-браузерам и сторонним API. В современных рабочих процессах все чаще используется Model Context Protocol (MCP), стандартизирующий способы обнаружения и безопасного подключения LLM к источникам контекстных данных и изолированным программным средам выполнения.
3. Ключевые шаблоны архитектурного проектирования
При создании сложных агентных систем инженеры-программисты полагаются на набор проверенных шаблонов проектирования, позволяющих управлять сложностью и поддерживать предсказуемость:
Шаблон 1: Шаблон маршрутизатора
Маршрутизатор считывает входящие входные данные и решает, какой специализированный запрос LLM, база данных или обработчик API должен обработать их следующим. Это предотвращает перегрузку одной монолитной подсказки LLM слишком большим количеством инструкций.
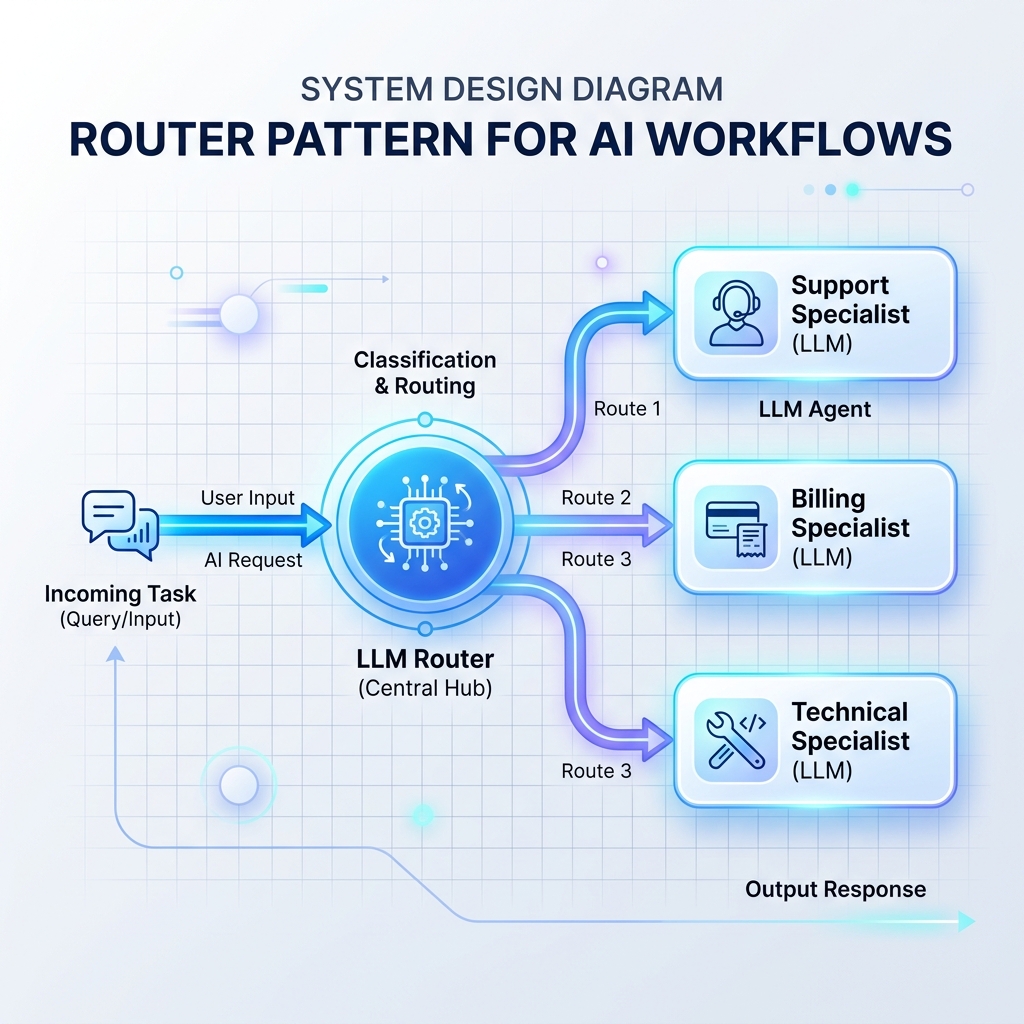
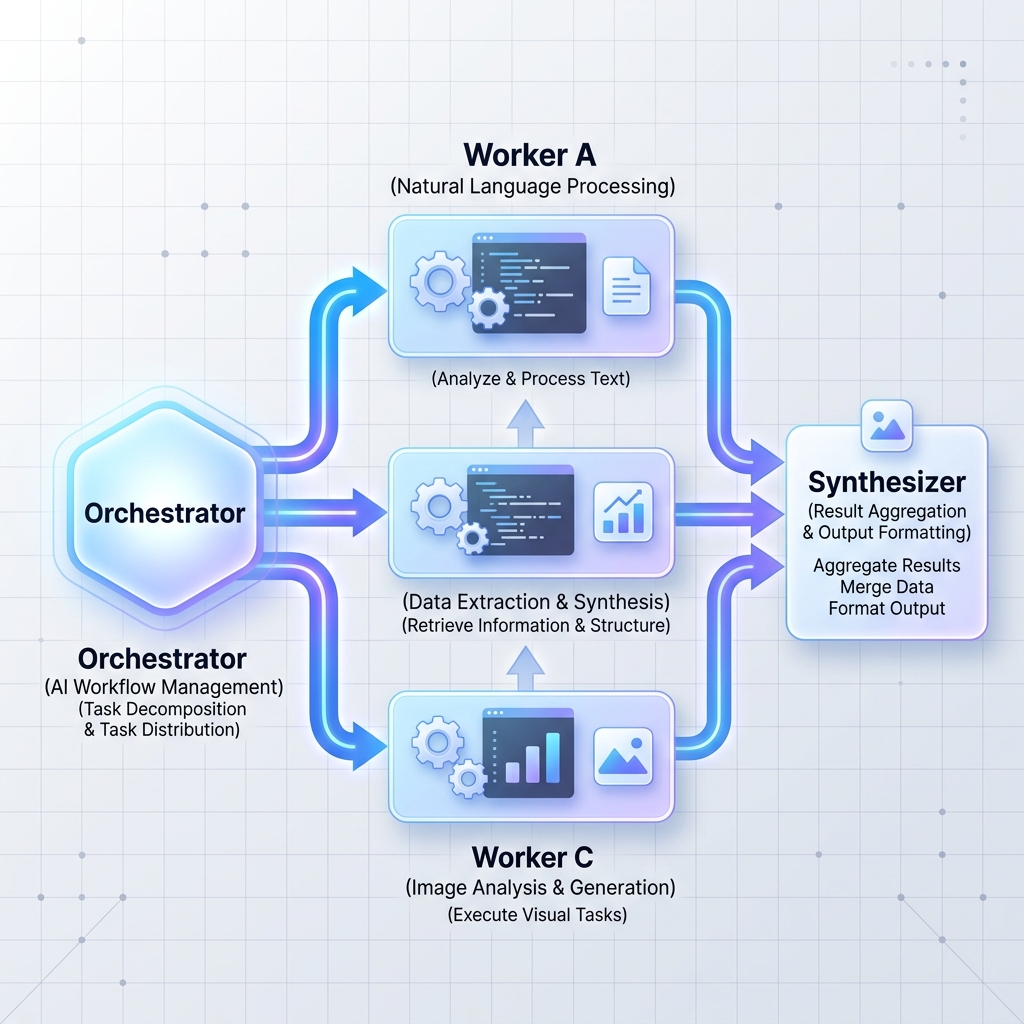
Схема 2: Оркестраторы-работники
Центральный оркестратор LLM разбивает большую и сложную задачу на независимые подзадачи. Затем он делегирует эти задачи рабочим узлам (которые могут быть специализированными LLM или стандартными микросервисами) и синтезирует результаты.
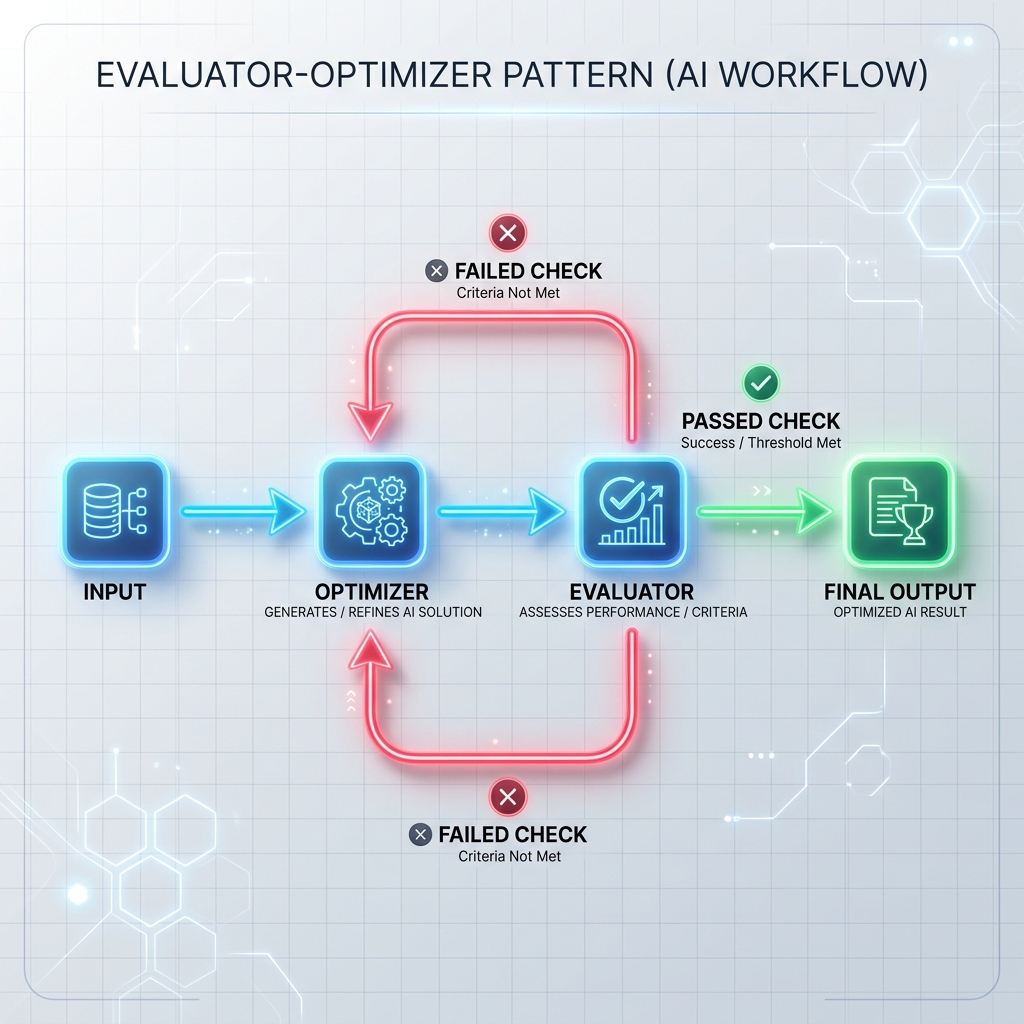
Шаблон 3: Цикл вычислителя-оптимизатора
Оптимизатор генерирует черновик ответа или выполняет задачу, а оценщик проверяет его на соответствие формальным критериям (например, модульным тестам, сканерам безопасности или отдельному запросу оценки). Если проверка не удалась, обратная связь передается обратно оптимизатору для повторной генерации ответа.
4. Создание агента на основе состояния на Python
Давайте посмотрим на конкретную реализацию автономного агента с использованием простого конечного автомата. Мы определим агента, который будет обрабатывать запросы на возврат средств. Агент проверяет историю покупок клиента, проверяет запрос на соответствие политикам, готовит ответ по электронной почте и запрашивает одобрение человека, если возмещение превышает 100 долларов США.
import json
from typing import Dict, Any
# Mock databases and tools
PURCHASE_DB = {
"user_123": {"item": "Premium Subscription", "price": 149.00, "days_ago": 12},
"user_456": {"item": "Basic License", "price": 49.00, "days_ago": 45}
}
class AutonomousRefundAgent:
def __init__(self):
self.state: Dict[str, Any] = {
"step": "INIT",
"user_id": None,
"refund_amount": 0.0,
"policy_passed": False,
"requires_approval": False,
"approved": False,
"response_draft": "",
"log": []
}
def run(self, user_id: str, request_text: str):
self.state["user_id"] = user_id
self.state["log"].append(f"Started workflow for user {user_id} with request: '{request_text}'")
while self.state["step"] != "COMPLETE":
current_step = self.state["step"]
if current_step == "INIT":
self._fetch_user_data()
elif current_step == "VALIDATE_POLICY":
self._validate_policy()
elif current_step == "CHECK_APPROVAL":
self._check_approval_requirements()
elif current_step == "WAITING_FOR_HUMAN":
# Pause execution and yield control back to the orchestrator
self.state["log"].append("Execution paused: waiting for human operator approval.")
break
elif current_step == "EXECUTE_REFUND":
self._execute_refund()
elif current_step == "DRAFT_RESPONSE":
self._draft_response()
return self.state
def _fetch_user_data(self):
user_id = self.state["user_id"]
purchase = PURCHASE_DB.get(user_id)
if not purchase:
self.state["response_draft"] = "No purchase history found for this user."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Fetch failed: User not found in database.")
return
self.state["refund_amount"] = purchase["price"]
self.state["purchase_age_days"] = purchase["days_ago"]
self.state["step"] = "VALIDATE_POLICY"
self.state["log"].append(f"Fetched purchase data: {purchase}")
def _validate_policy(self):
# Business rule: Refunds only allowed within 30 days
age = self.state["purchase_age_days"]
if age <= 30:
self.state["policy_passed"] = True
self.state["step"] = "CHECK_APPROVAL"
self.state["log"].append("Policy validation passed (within 30-day window).")
else:
self.state["policy_passed"] = False
self.state["response_draft"] = "Sorry, our policy only allows refunds within 30 days of purchase."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Policy validation failed: Purchase older than 30 days.")
def _check_approval_requirements(self):
# Business rule: Refunds over $100 require human review
amount = self.state["refund_amount"]
if amount > 100.0:
self.state["requires_approval"] = True
self.state["step"] = "WAITING_FOR_HUMAN"
self.state["log"].append(f"Refund of ${amount} exceeds limit. Moving to human approval state.")
else:
self.state["requires_approval"] = False
self.state["step"] = "EXECUTE_REFUND"
self.state["log"].append(f"Refund of ${amount} is within limits. Proceeding to execution.")
def resume_with_human_decision(self, approved: bool):
if self.state["step"] != "WAITING_FOR_HUMAN":
raise ValueError("Agent is not currently waiting for approval.")
self.state["approved"] = approved
self.state["log"].append(f"Human manager decision received: Approved = {approved}")
if approved:
self.state["step"] = "EXECUTE_REFUND"
else:
self.state["response_draft"] = "Your refund request has been reviewed and declined by a customer service manager."
self.state["step"] = "DRAFT_RESPONSE"
# Resume the workflow loop
return self.run(self.state["user_id"], "")
def _execute_refund(self):
amount = self.state["refund_amount"]
# Trigger actual external API call/Stripe integration here
self.state["log"].append(f"Successfully processed stripe refund for ${amount}.")
self.state["response_draft"] = f"Your refund request for ${amount} has been successfully processed."
self.state["step"] = "DRAFT_RESPONSE"
def _draft_response(self):
# Prompt LLM to draft a polite, personalized message incorporating response_draft
self.state["final_message"] = f"Dear Customer,\n\n{self.state['response_draft']}\n\nBest regards,\nGhaznix Support Agent"
self.state["step"] = "COMPLETE"
self.state["log"].append("Customer email drafted successfully. Workflow complete.")
5. Надежность производства и меры безопасности
Развертывание автономных систем требует изменения нашего подхода к тестированию и обработке ошибок. Вот важные ограничения, которые необходимо встроить в любую производственную систему:
A. Предотвращение неконтролируемых циклов выполнения
Автономный агент, обнаруживший ошибку или крайний случай, может повторно запрашивать один и тот же инструмент, тратя тысячи долларов на API в считанные минуты.
- Решение: установите максимальные ограничения на выполнение. Всегда устанавливайте жесткий потолок количества шагов или общего количества токенов модели, разрешенных для каждого экземпляра рабочего процесса (например, максимум 10 итераций).
B. Проверка структурной схемы
LLM являются вероятностными и, естественно, не гарантируют структурированные выходные данные, такие как действительный JSON или соответствующие схемы.
- Решение: используйте библиотеки проверки, такие как Pydantic, Instructor или Outlines, чтобы обеспечить соблюдение структуры на уровне вывода. Если модель выводит недопустимые схемы, отклоните ее раньше и предложите модели с ошибкой синтаксического анализа исправить себя (часть цикла Evaluator-Optimizer).
C. Выполнение кода в песочнице
Если ваш агент пишет и запускает код (например, анализ данных или преобразование базы данных), запуск его непосредственно на сервере приложений представляет собой серьезную уязвимость безопасности.
- Решение. Используйте безопасные временные среды микро-VM (например, контейнеры Docker, gVisor или среды выполнения WASM) для безопасного запуска сценариев, созданных пользователем или агентом.
Заключение
Создание автономных рабочих процессов ИИ с помощью LLM требует преодоления разрыва между гибкими рассуждениями ИИ и структурированной инженерной дисциплиной. Заменяя открытые агенты рабочими процессами, управляемыми конечным автоматом, структурируя задачи с помощью таких шаблонов, как Orchestrator-Workers, и оборачивая все строгими ограничениями исполнения и безопасности, разработчики могут создавать системы, которые одновременно являются высокоинтеллектуальными и готовыми к использованию на предприятии.
Будущее архитектуры программного обеспечения заключается не в замене кода подсказками, а в организации агентов и детерминированных систем для построения рабочих процессов, которые работают автономно, динамически обучаются и надежно доставляют результаты.
Больше статей об искусственном интеллекте можно найти в блоге Ghaznix →