Créer des workflows d'IA autonomes avec des LLM

Les grands modèles linguistiques (LLM) ont transformé la façon dont nous interagissons avec la technologie, passant rapidement de simples chatbots conversationnels à des moteurs de raisonnement capables de conduire des actions complexes en plusieurs étapes. Bien qu’une seule interaction avec une réponse rapide puisse être puissante, la véritable valeur de l’IA générative dans les environnements d’entreprise réside dans les flux de travail d’IA autonomes.
Plutôt que de compter sur des opérateurs humains pour orchestrer chaque étape, les flux de travail autonomes utilisent les LLM comme décideurs centraux qui planifient, exécutent, évaluent et corrigent automatiquement les tâches sur de longues périodes.
Cette étude approfondie explore comment concevoir, créer et déployer des flux de travail d’IA autonomes et fiables à l’aide de modèles de conception modernes, de machines à états et de garde-corps robustes.
1. Le virage agent : chatbots contre workflows
L’évolution des applications LLM peut être classée en quatre niveaux distincts d’autonomie :
| Niveau | Paradigme | Rôle humain | Mécanisme de base |
|---|---|---|---|
| Niveau 1 | Chat conversationnel | Élevé (invite à chaque tour) | Achèvements en un seul tour sans état |
| Niveau 2 | Appel d’outil / Appel de fonction | Moyen (Fournit le contexte) | Le modèle choisit l’API à appeler ; renvoie le résultat |
| Niveau 3 | Flux de travail dirigés | Faible (définit les objectifs et le graphique) | Machine à états codée en dur avec routage LLM |
| Niveau 4 | Agents entièrement autonomes | Minimal (Définit l’objectif/le budget) | Boucles de planification, d’exécution et de réflexion basées sur le LLM |
Même si les agents de niveau 4 sont très flexibles, ils sont notoirement difficiles à prédire dans les environnements de production. Par conséquent, la plupart des architectures d’entreprise sont construites sur le Niveau 3 : Flux de travail dirigés, combinant la fiabilité déterministe des machines à états logicielles avec le raisonnement dynamique des LLM.
2. Piliers fondamentaux des flux de travail autonomes
Pour créer un flux de travail autonome, vous devez combiner quatre composants fondamentaux :
A. Raisonnement et planification
Au cœur du flux de travail se trouve le paradigme de la planification. Un appel LLM naïf tente de produire immédiatement la réponse finale, ce qui conduit souvent à des échecs de raisonnement. Les flux de travail autonomes utilisent des boucles de planification spécialisées :
- ReAct (Reason + Act) : Le modèle pense, agit (appelle un outil) et observe le résultat de manière itérative, en répétant cette boucle jusqu’à ce que l’objectif soit atteint.
- Chaîne de pensée (CoT) : forcer le modèle à produire son raisonnement étape par étape avant d’arriver à une conclusion.
- Arbre de pensées (ToT) : génération et évaluation de plusieurs chemins alternatifs, suivi des différentes branches et retour en arrière lorsqu’un chemin échoue.
B. Mémoire à court et à long terme
Un système autonome doit maintenir son état sur plusieurs cycles d’exécution :
- Mémoire à court terme : le contexte du thread, les variables d’état et les journaux d’exécution qui assurent le suivi de ce que fait actuellement le flux de travail.
- Mémoire à long terme : bases de données vectorielles et systèmes de récupération sémantique qui permettent au flux de travail de rappeler les exécutions historiques, les préférences utilisateur et la documentation de l’entreprise.
C. Outils et intégration Web
Pour agir sur le monde physique ou numérique, les LLM doivent s’interfacer avec des services externes. Le modèle doit accéder aux pilotes de base de données, aux systèmes de fichiers, aux navigateurs Web et aux API tierces. Les flux de travail modernes adoptent de plus en plus le Model Context Protocol (MCP), standardisant la façon dont les LLM découvrent et se connectent en toute sécurité aux sources de données contextuelles et aux sandbox d’exécution.
3. Principaux modèles de conception architecturale
Lors de la création de systèmes agentiques complexes, les ingénieurs logiciels s’appuient sur un ensemble de modèles de conception éprouvés pour gérer la complexité et maintenir la prévisibilité :
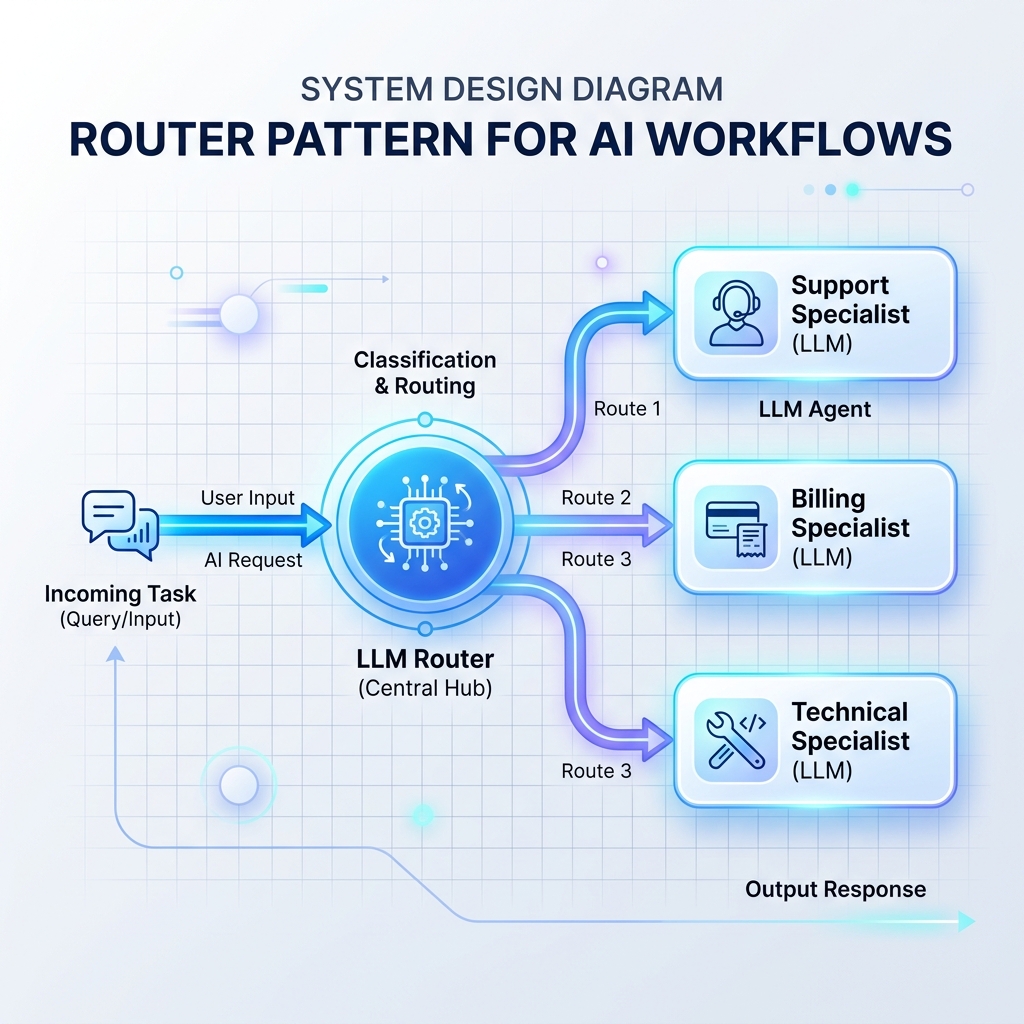
Modèle 1 : Le modèle de routeur
Un routeur lit les entrées entrantes et décide quelle invite LLM spécialisée, quelle base de données ou quel gestionnaire d’API doit les traiter ensuite. Cela évite qu’une seule invite LLM monolithique ne soit surchargée avec trop d’instructions.
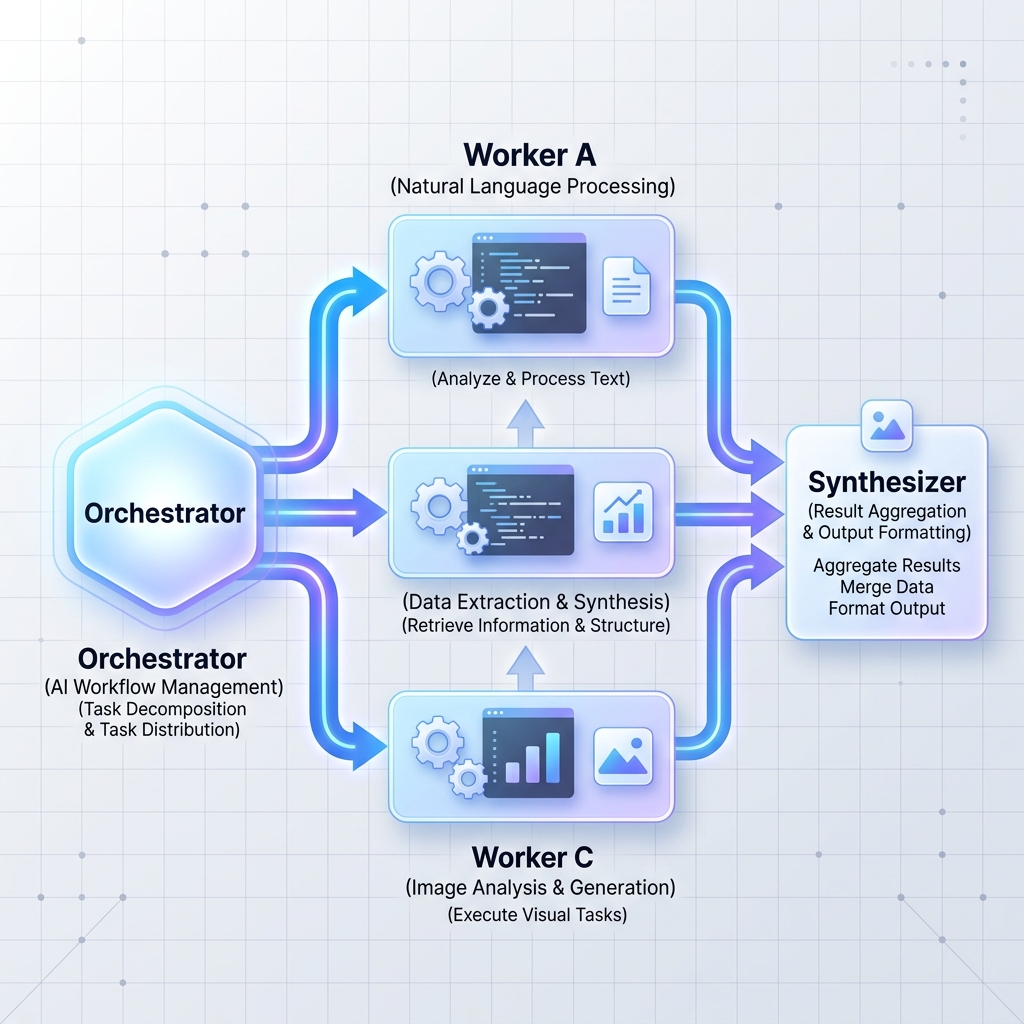
Modèle 2 : Orchestrateurs-travailleurs
Un orchestrateur central LLM décompose une tâche vaste et complexe en sous-tâches indépendantes. Il délègue ensuite ces tâches à des nœuds de travail (qui peuvent être des LLM spécialisés ou des microservices standards) et synthétise les résultats.
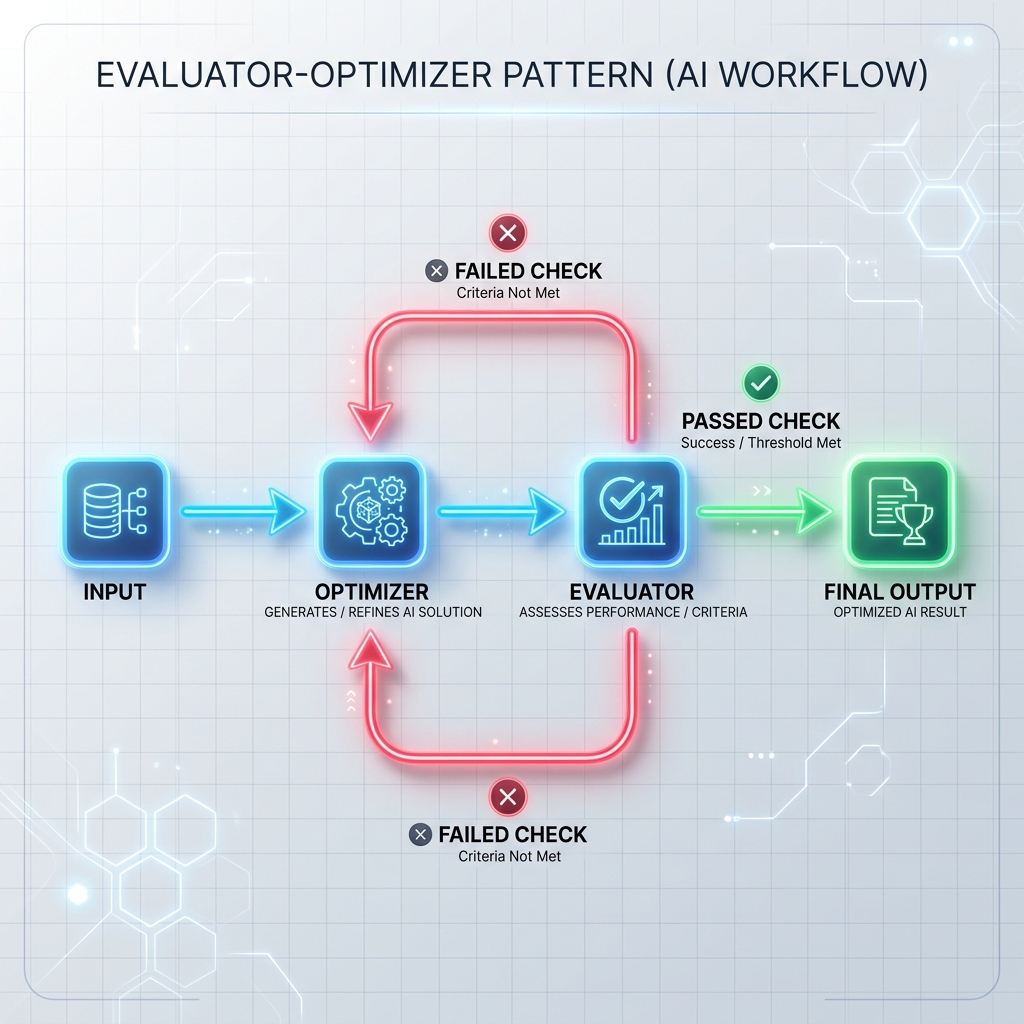
Modèle 3 : Boucle évaluateur-optimiseur
L’optimiseur génère un brouillon de réponse ou exécute une tâche, et l’évaluateur le vérifie par rapport à des critères formels (tels que des tests unitaires, des scanners de sécurité ou une invite d’évaluation distincte). Si la vérification échoue, le retour est renvoyé à l’optimiseur pour régénérer la réponse.
4. Créer un agent basé sur un état en Python
Examinons une implémentation concrète d’un agent autonome utilisant une simple machine à états. Nous définirons un agent qui traitera les demandes de remboursement. L’agent vérifie l’historique des achats du client, valide la demande par rapport aux politiques, rédige une réponse par e-mail et demande l’approbation humaine si le remboursement dépasse 100 $.
import json
from typing import Dict, Any
# Mock databases and tools
PURCHASE_DB = {
"user_123": {"item": "Premium Subscription", "price": 149.00, "days_ago": 12},
"user_456": {"item": "Basic License", "price": 49.00, "days_ago": 45}
}
class AutonomousRefundAgent:
def __init__(self):
self.state: Dict[str, Any] = {
"step": "INIT",
"user_id": None,
"refund_amount": 0.0,
"policy_passed": False,
"requires_approval": False,
"approved": False,
"response_draft": "",
"log": []
}
def run(self, user_id: str, request_text: str):
self.state["user_id"] = user_id
self.state["log"].append(f"Started workflow for user {user_id} with request: '{request_text}'")
while self.state["step"] != "COMPLETE":
current_step = self.state["step"]
if current_step == "INIT":
self._fetch_user_data()
elif current_step == "VALIDATE_POLICY":
self._validate_policy()
elif current_step == "CHECK_APPROVAL":
self._check_approval_requirements()
elif current_step == "WAITING_FOR_HUMAN":
# Pause execution and yield control back to the orchestrator
self.state["log"].append("Execution paused: waiting for human operator approval.")
break
elif current_step == "EXECUTE_REFUND":
self._execute_refund()
elif current_step == "DRAFT_RESPONSE":
self._draft_response()
return self.state
def _fetch_user_data(self):
user_id = self.state["user_id"]
purchase = PURCHASE_DB.get(user_id)
if not purchase:
self.state["response_draft"] = "No purchase history found for this user."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Fetch failed: User not found in database.")
return
self.state["refund_amount"] = purchase["price"]
self.state["purchase_age_days"] = purchase["days_ago"]
self.state["step"] = "VALIDATE_POLICY"
self.state["log"].append(f"Fetched purchase data: {purchase}")
def _validate_policy(self):
# Business rule: Refunds only allowed within 30 days
age = self.state["purchase_age_days"]
if age <= 30:
self.state["policy_passed"] = True
self.state["step"] = "CHECK_APPROVAL"
self.state["log"].append("Policy validation passed (within 30-day window).")
else:
self.state["policy_passed"] = False
self.state["response_draft"] = "Sorry, our policy only allows refunds within 30 days of purchase."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Policy validation failed: Purchase older than 30 days.")
def _check_approval_requirements(self):
# Business rule: Refunds over $100 require human review
amount = self.state["refund_amount"]
if amount > 100.0:
self.state["requires_approval"] = True
self.state["step"] = "WAITING_FOR_HUMAN"
self.state["log"].append(f"Refund of ${amount} exceeds limit. Moving to human approval state.")
else:
self.state["requires_approval"] = False
self.state["step"] = "EXECUTE_REFUND"
self.state["log"].append(f"Refund of ${amount} is within limits. Proceeding to execution.")
def resume_with_human_decision(self, approved: bool):
if self.state["step"] != "WAITING_FOR_HUMAN":
raise ValueError("Agent is not currently waiting for approval.")
self.state["approved"] = approved
self.state["log"].append(f"Human manager decision received: Approved = {approved}")
if approved:
self.state["step"] = "EXECUTE_REFUND"
else:
self.state["response_draft"] = "Your refund request has been reviewed and declined by a customer service manager."
self.state["step"] = "DRAFT_RESPONSE"
# Resume the workflow loop
return self.run(self.state["user_id"], "")
def _execute_refund(self):
amount = self.state["refund_amount"]
# Trigger actual external API call/Stripe integration here
self.state["log"].append(f"Successfully processed stripe refund for ${amount}.")
self.state["response_draft"] = f"Your refund request for ${amount} has been successfully processed."
self.state["step"] = "DRAFT_RESPONSE"
def _draft_response(self):
# Prompt LLM to draft a polite, personalized message incorporating response_draft
self.state["final_message"] = f"Dear Customer,\n\n{self.state['response_draft']}\n\nBest regards,\nGhaznix Support Agent"
self.state["step"] = "COMPLETE"
self.state["log"].append("Customer email drafted successfully. Workflow complete.")
5. Fiabilité de la production et garde-fous de sécurité
Le déploiement de systèmes autonomes nécessite un changement dans notre façon de penser les tests et la gestion des erreurs. Voici les garde-fous essentiels que vous devez intégrer dans tout système de production :
A. Prévenir les boucles d’exécution incontrôlables
Un agent autonome qui rencontre une erreur ou un cas limite peut interroger le même outil à plusieurs reprises, dépensant des milliers de dollars en coûts d’API en quelques minutes.
- Solution : implémentez des limites d’exécution maximales. Définissez toujours un plafond strict sur le nombre d’étapes ou le nombre total de jetons de modèle autorisés par instance de flux de travail (par exemple, un maximum de 10 itérations).
B. Validation du schéma structurel
Les LLM sont probabilistes et ne garantissent pas naturellement des sorties structurées comme un JSON valide ou des schémas correspondants.
- Solution : utilisez des bibliothèques de validation telles que Pydantic, Instructor ou Outlines pour appliquer la structure au niveau de l’inférence. Si un modèle génère des schémas non valides, rejetez-le rapidement et invitez le modèle avec l’erreur d’analyse à se corriger (une partie de la boucle Evaluator-Optimizer).
C. Exécution du code en sandbox
Si votre agent écrit et exécute du code (comme l’analyse de données ou les transformations de bases de données), son exécution directement sur votre serveur d’applications constitue une vulnérabilité de sécurité majeure.
- Solution : utilisez des environnements micro-VM sécurisés et éphémères (comme les conteneurs Docker, gVisor ou les environnements d’exécution WASM) pour exécuter en toute sécurité des scripts générés par l’utilisateur ou par l’agent.
Conclusion
Créer des flux de travail d’IA autonomes avec des LLM nécessite de combler le fossé entre le raisonnement flexible de l’IA et la discipline d’ingénierie structurée. En remplaçant les agents ouverts par des flux de travail dirigés par des machines à états, en structurant les tâches via des modèles tels que Orchestrator-Workers et en enveloppant le tout dans des garde-fous d’exécution et de sécurité stricts, les développeurs peuvent créer des systèmes à la fois hautement intelligents et prêts pour l’entreprise.
L’avenir de l’architecture logicielle ne consiste pas à remplacer le code par des invites : il s’agit d’orchestrer des agents et des systèmes déterministes pour créer des flux de travail qui fonctionnent de manière autonome, apprennent de manière dynamique et fournissent des résultats de manière fiable.
Découvrez davantage d’articles sur l’ingénierie de l’IA sur le blog Ghaznix →