Creazione di flussi di lavoro IA autonomi con LLM

I Large Language Models (LLM) hanno trasformato il modo in cui interagiamo con la tecnologia, passando rapidamente da semplici chatbot conversazionali a motori di ragionamento in grado di guidare azioni complesse in più fasi. Sebbene una singola interazione con risposta rapida possa essere potente, il valore reale dell’intelligenza artificiale generativa in contesti aziendali risiede nei flussi di lavoro AI autonomi.
Invece di fare affidamento su operatori umani per orchestrare ogni passaggio, i flussi di lavoro autonomi utilizzano gli LLM come decisori centrali che pianificano, eseguono, valutano e correggono autonomamente le attività per lunghi periodi.
Questo approfondimento esplora come progettare, costruire e distribuire flussi di lavoro IA autonomi e affidabili utilizzando modelli di progettazione moderni, macchine a stati e robusti guardrail.
1. Il cambiamento dell’agente: chatbot e flussi di lavoro
L’evoluzione delle applicazioni LLM può essere classificata in quattro distinti livelli di autonomia:
| Livello | Paradigma | Ruolo umano | Meccanismo principale |
|---|---|---|---|
| Livello 1 | Chat conversazionale | Alto (richiede ogni turno) | Completamenti a turno singolo senza stato |
| Livello 2 | Chiamata strumento/Chiamata funzione | Medio (fornisce il contesto) | Il modello sceglie l’API da chiamare; restituisce risultato |
| Livello 3 | Flussi di lavoro diretti | Basso (Definisce obiettivi e grafico) | Macchina a stati hardcoded con routing LLM |
| Livello 4 | Agenti completamente autonomi | Minimo (Definisce obiettivo/budget) | Pianificazione, esecuzione e cicli di riflessione guidati da LLM |
Sebbene gli agenti di livello 4 siano altamente flessibili, sono notoriamente difficili da prevedere negli ambienti di produzione. Pertanto, la maggior parte delle architetture aziendali sono costruite sul Livello 3: flussi di lavoro diretti, combinando l’affidabilità deterministica delle macchine a stati software con il ragionamento dinamico degli LLM.
2. Pilastri fondamentali dei flussi di lavoro autonomi
Per creare un flusso di lavoro autonomo, è necessario combinare quattro componenti fondamentali:
A. Ragionamento e pianificazione
Al centro del flusso di lavoro c’è il paradigma di pianificazione. Una chiamata LLM ingenua tenta di fornire immediatamente la risposta finale, il che spesso porta a errori di ragionamento. I flussi di lavoro autonomi utilizzano cicli di pianificazione specializzati:
- ReAct (Reason + Act): il modello pensa, agisce (chiama uno strumento) in modo iterativo e osserva il risultato, ripetendo questo ciclo finché l’obiettivo non viene raggiunto.
- Catena di pensiero (CoT): forzare il modello a produrre il suo ragionamento passo passo prima di arrivare a una conclusione.
- Albero dei pensieri (ToT): generare e valutare più percorsi alternativi, tenere traccia dei diversi rami e tornare indietro quando un percorso fallisce.
B. Memoria a breve e lungo termine
Un sistema autonomo deve mantenere lo stato attraverso più cicli di esecuzione:
- Memoria a breve termine: il contesto del thread, le variabili di stato e i log di esecuzione che tengono traccia di ciò che il flusso di lavoro sta attualmente facendo.
- Memoria a lungo termine: database vettoriali e sistemi di recupero semantico che consentono al flusso di lavoro di richiamare esecuzioni storiche, preferenze dell’utente e documentazione aziendale.
C. Strumenti e integrazione web
Per agire sul mondo fisico o digitale, gli LLM devono interfacciarsi con servizi esterni. Il modello necessita dell’accesso a driver di database, file system, browser Web e API di terze parti. I flussi di lavoro moderni stanno adottando sempre più il Model Context Protocol (MCP), standardizzando il modo in cui i LLM scoprono e si connettono in modo sicuro a origini dati contestuali e sandbox di esecuzione.
3. Principali modelli di progettazione architettonica
Quando costruiscono sistemi ad agenti complessi, gli ingegneri del software si affidano a una serie di modelli di progettazione comprovati per gestire la complessità e mantenere la prevedibilità:
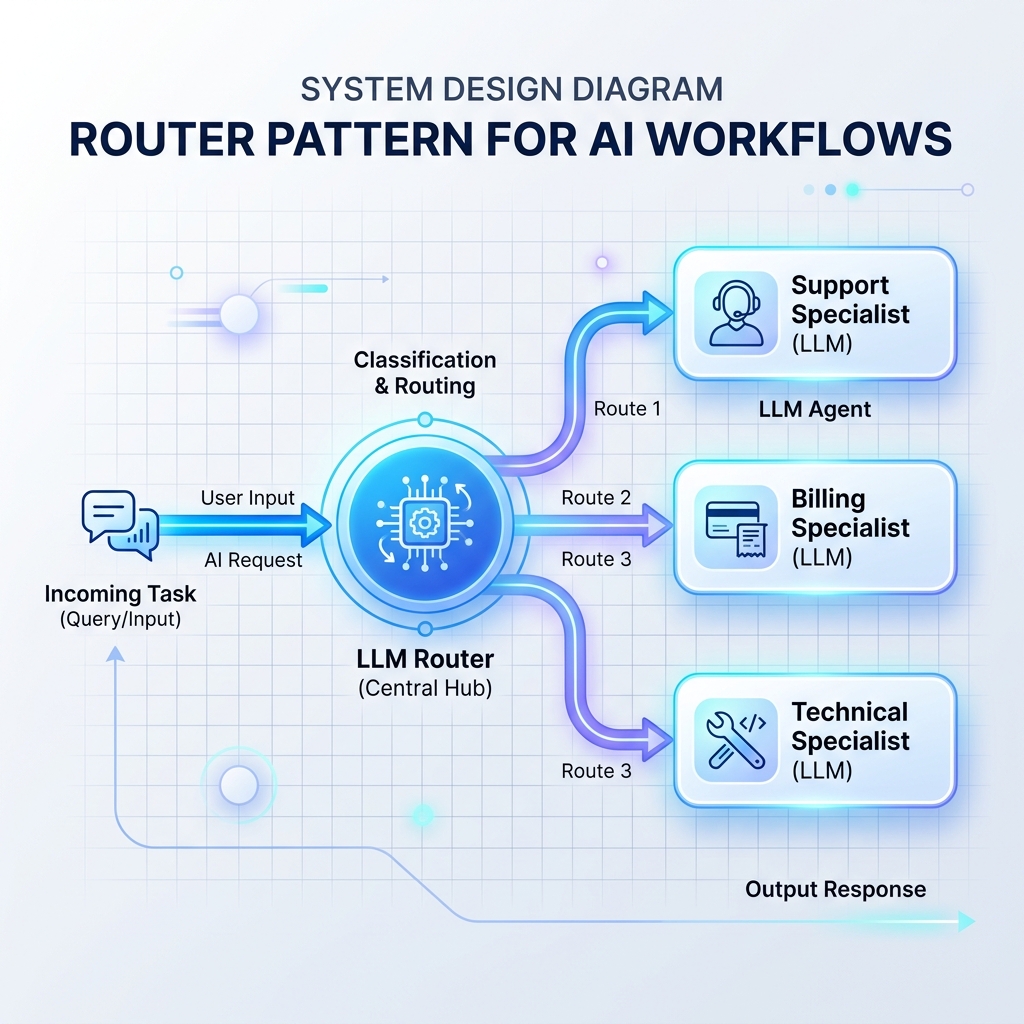
Modello 1: Il modello del router
Un router legge gli input in entrata e decide quale prompt LLM, database o gestore API specializzato dovrà elaborarli successivamente. Ciò impedisce che un singolo prompt LLM monolitico venga sovraccaricato con troppe istruzioni.
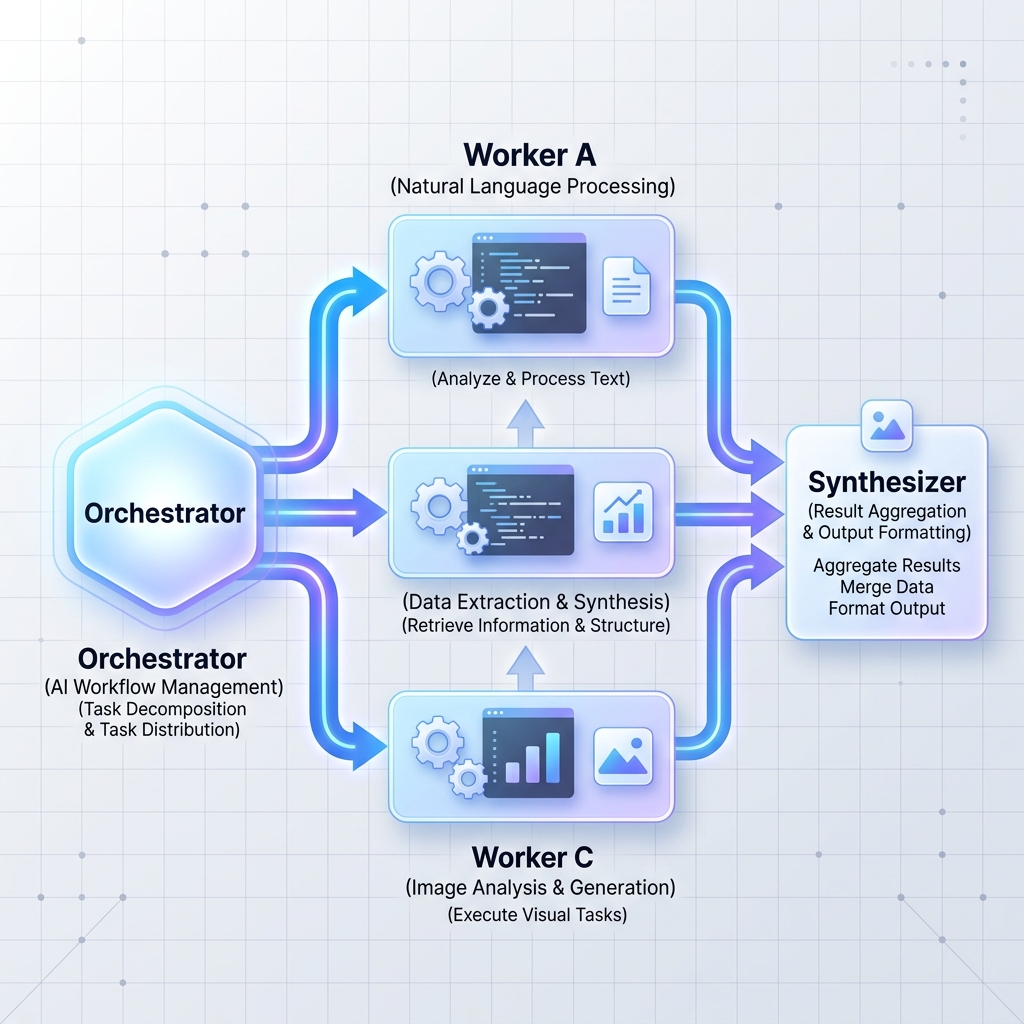
Modello 2: Orchestratori-Operai
Un LLM dell’orchestratore centrale suddivide un’attività ampia e complessa in attività secondarie indipendenti. Quindi delega queste attività ai nodi di lavoro (che possono essere LLM specializzati o microservizi standard) e sintetizza i risultati.
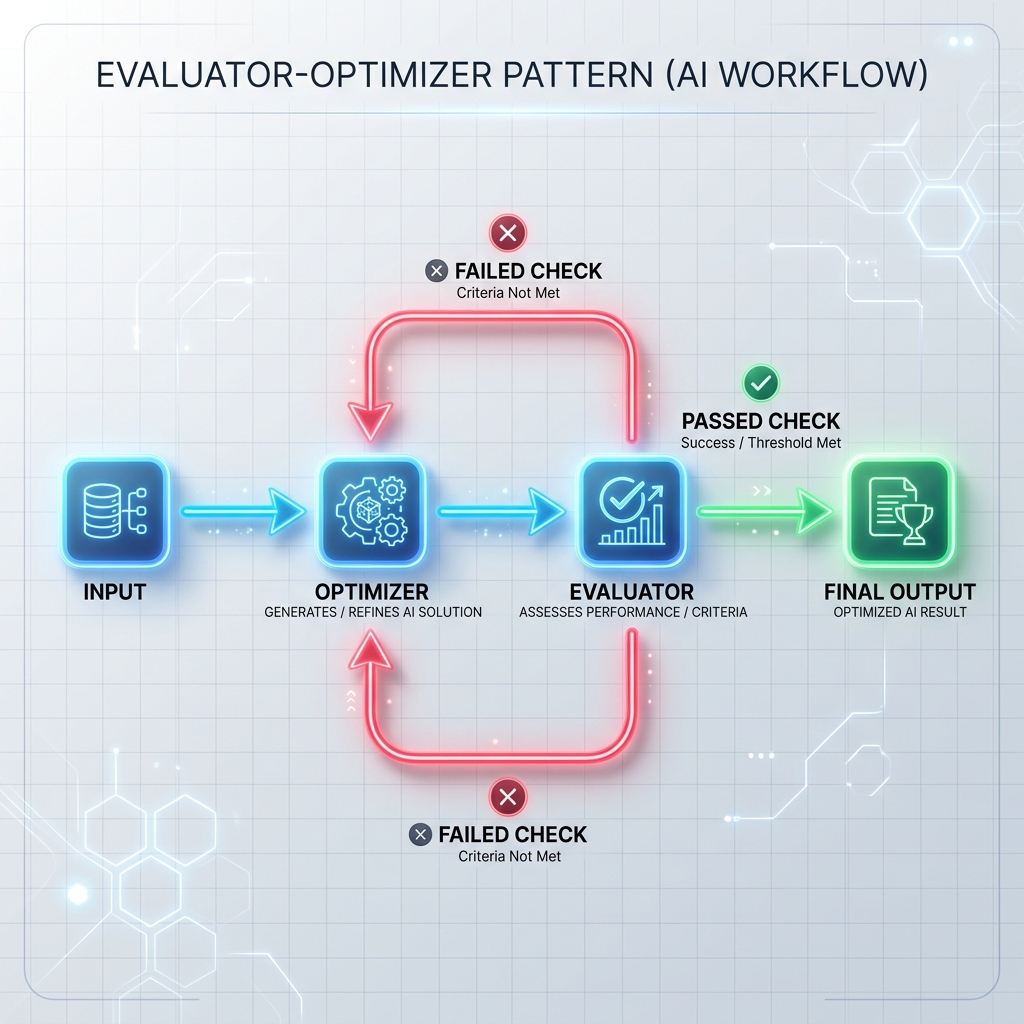
Modello 3: Ciclo Valutatore-Ottimizzatore
L’ottimizzatore genera una bozza di risposta o esegue un’attività e il valutatore la confronta con criteri formali (come test unitari, scanner di sicurezza o un prompt di valutazione separato). Se il controllo fallisce, il feedback viene passato all’ottimizzatore per rigenerare la risposta.
4. Costruire un agente basato sullo stato in Python
Diamo un’occhiata a un’implementazione concreta di un agente autonomo utilizzando una semplice macchina a stati. Definiremo un agente che elaborerà le richieste di rimborso. L’agente controlla la cronologia degli acquisti del cliente, convalida la richiesta rispetto alle politiche, redige una risposta via email e richiede l’approvazione umana se il rimborso supera i 100 dollari.
import json
from typing import Dict, Any
# Mock databases and tools
PURCHASE_DB = {
"user_123": {"item": "Premium Subscription", "price": 149.00, "days_ago": 12},
"user_456": {"item": "Basic License", "price": 49.00, "days_ago": 45}
}
class AutonomousRefundAgent:
def __init__(self):
self.state: Dict[str, Any] = {
"step": "INIT",
"user_id": None,
"refund_amount": 0.0,
"policy_passed": False,
"requires_approval": False,
"approved": False,
"response_draft": "",
"log": []
}
def run(self, user_id: str, request_text: str):
self.state["user_id"] = user_id
self.state["log"].append(f"Started workflow for user {user_id} with request: '{request_text}'")
while self.state["step"] != "COMPLETE":
current_step = self.state["step"]
if current_step == "INIT":
self._fetch_user_data()
elif current_step == "VALIDATE_POLICY":
self._validate_policy()
elif current_step == "CHECK_APPROVAL":
self._check_approval_requirements()
elif current_step == "WAITING_FOR_HUMAN":
# Pause execution and yield control back to the orchestrator
self.state["log"].append("Execution paused: waiting for human operator approval.")
break
elif current_step == "EXECUTE_REFUND":
self._execute_refund()
elif current_step == "DRAFT_RESPONSE":
self._draft_response()
return self.state
def _fetch_user_data(self):
user_id = self.state["user_id"]
purchase = PURCHASE_DB.get(user_id)
if not purchase:
self.state["response_draft"] = "No purchase history found for this user."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Fetch failed: User not found in database.")
return
self.state["refund_amount"] = purchase["price"]
self.state["purchase_age_days"] = purchase["days_ago"]
self.state["step"] = "VALIDATE_POLICY"
self.state["log"].append(f"Fetched purchase data: {purchase}")
def _validate_policy(self):
# Business rule: Refunds only allowed within 30 days
age = self.state["purchase_age_days"]
if age <= 30:
self.state["policy_passed"] = True
self.state["step"] = "CHECK_APPROVAL"
self.state["log"].append("Policy validation passed (within 30-day window).")
else:
self.state["policy_passed"] = False
self.state["response_draft"] = "Sorry, our policy only allows refunds within 30 days of purchase."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Policy validation failed: Purchase older than 30 days.")
def _check_approval_requirements(self):
# Business rule: Refunds over $100 require human review
amount = self.state["refund_amount"]
if amount > 100.0:
self.state["requires_approval"] = True
self.state["step"] = "WAITING_FOR_HUMAN"
self.state["log"].append(f"Refund of ${amount} exceeds limit. Moving to human approval state.")
else:
self.state["requires_approval"] = False
self.state["step"] = "EXECUTE_REFUND"
self.state["log"].append(f"Refund of ${amount} is within limits. Proceeding to execution.")
def resume_with_human_decision(self, approved: bool):
if self.state["step"] != "WAITING_FOR_HUMAN":
raise ValueError("Agent is not currently waiting for approval.")
self.state["approved"] = approved
self.state["log"].append(f"Human manager decision received: Approved = {approved}")
if approved:
self.state["step"] = "EXECUTE_REFUND"
else:
self.state["response_draft"] = "Your refund request has been reviewed and declined by a customer service manager."
self.state["step"] = "DRAFT_RESPONSE"
# Resume the workflow loop
return self.run(self.state["user_id"], "")
def _execute_refund(self):
amount = self.state["refund_amount"]
# Trigger actual external API call/Stripe integration here
self.state["log"].append(f"Successfully processed stripe refund for ${amount}.")
self.state["response_draft"] = f"Your refund request for ${amount} has been successfully processed."
self.state["step"] = "DRAFT_RESPONSE"
def _draft_response(self):
# Prompt LLM to draft a polite, personalized message incorporating response_draft
self.state["final_message"] = f"Dear Customer,\n\n{self.state['response_draft']}\n\nBest regards,\nGhaznix Support Agent"
self.state["step"] = "COMPLETE"
self.state["log"].append("Customer email drafted successfully. Workflow complete.")
5. Affidabilità della produzione e barriere di sicurezza
L’implementazione di sistemi autonomi richiede un cambiamento nel modo in cui pensiamo ai test e alla gestione degli errori. Ecco i guardrail fondamentali che devi integrare in qualsiasi sistema di produzione:
A. Prevenire cicli di esecuzione incontrollati
Un agente autonomo che riscontra un errore o un caso limite potrebbe interrogare ripetutamente lo stesso strumento, spendendo migliaia di dollari in costi API in pochi minuti.
- Soluzione: implementare limiti massimi di esecuzione. Definire sempre un limite massimo al numero di passaggi o ai token totali del modello consentiti per istanza del flusso di lavoro (ad esempio, massimo 10 iterazioni).
B. Convalida dello schema strutturale
Gli LLM sono probabilistici e non garantiscono naturalmente output strutturati come JSON validi o schemi corrispondenti.
- Soluzione: utilizzare librerie di convalida come Pydantic, Instructor o Outlines per applicare la struttura a livello di inferenza. Se un modello restituisce schemi non validi, rifiutalo in anticipo e chiedi al modello con l’errore di analisi di risolversi da solo (parte del ciclo Valutatore-Ottimizzatore).
C. Esecuzione sandbox del codice
Se il tuo agente scrive ed esegue codice (come analisi dei dati o trasformazioni di database), eseguirlo direttamente sul tuo server delle applicazioni rappresenta una grave vulnerabilità della sicurezza.
- Soluzione: utilizza ambienti micro-VM sicuri ed effimeri (come contenitori Docker, gVisor o runtime WASM) per eseguire script generati dagli utenti o dagli agenti in modo sicuro.
Conclusione
La creazione di flussi di lavoro IA autonomi con LLM richiede di colmare il divario tra il ragionamento AI flessibile e la disciplina ingegneristica strutturata. Sostituendo gli agenti a tempo indeterminato con flussi di lavoro diretti dalle macchine a stati, strutturando le attività tramite modelli come Orchestrator-Workers e racchiudendo il tutto in rigorose misure di esecuzione e protezioni di sicurezza, gli sviluppatori possono creare sistemi altamente intelligenti e pronti per l’azienda.
Il futuro dell’architettura software non consiste nella sostituzione del codice con prompt, ma nell’orchestrazione di agenti e sistemi deterministici per creare flussi di lavoro che operano in modo autonomo, apprendono dinamicamente e forniscono risultati in modo affidabile.
Scopri altri articoli di ingegneria dell’intelligenza artificiale sul blog di Ghaznix →