ایجاد گردش کار هوش مصنوعی مستقل با LLM

مدلهای زبان بزرگ (LLM) نحوه تعامل ما با فناوری را تغییر دادهاند و به سرعت از چت رباتهای مکالمه ساده به موتورهای استدلالی که قادر به انجام اقدامات پیچیده و چند مرحلهای هستند، حرکت میکنند. در حالی که یک تعامل سریع-پاسخ می تواند قدرتمند باشد، ارزش واقعی هوش مصنوعی مولد در تنظیمات سازمانی در روند کاری هوش مصنوعی خودکار نهفته است.
به جای تکیه بر اپراتورهای انسانی برای هماهنگ کردن هر مرحله، گردشهای کاری مستقل از LLM به عنوان تصمیمگیرندگان مرکزی استفاده میکنند که وظایف را در دورههای طولانی برنامهریزی، اجرا، ارزیابی و اصلاح میکنند.
این غواصی عمیق نحوه معماری، ساخت و استقرار گردشهای کاری خودکار هوش مصنوعی قابل اعتماد را با استفاده از الگوهای طراحی مدرن، ماشینهای حالت دار و نردههای محافظ قوی بررسی میکند.
1. Agentic Shift: Chatbots در مقابل گردش کار
تکامل برنامه های LLM را می توان به چهار سطح متمایز از خودمختاری طبقه بندی کرد:
| سطح | پارادایم | نقش انسانی | مکانیسم هسته |
|---|---|---|---|
| سطح 1 | چت محاوره ای | بالا (در هر نوبت به شما هشدار می دهد) | تکمیل تک نوبتی بدون تابعیت |
| سطح 2 | فراخوانی ابزار / فراخوانی تابع | رسانه (ارائه زمینه) | مدل API را برای فراخوانی انتخاب می کند. نتیجه را برمی گرداند |
| سطح 3 | گردش کار هدایت شده | کم (اهداف و نمودار را تعریف می کند) | ماشین حالت هاردکد شده با مسیریابی LLM |
| سطح 4 | نمایندگی های کاملا خودمختار | حداقل (هدف/بودجه را تعریف می کند) | حلقه های برنامه ریزی، اجرا و بازتاب مبتنی بر LLM |
در حالی که عوامل سطح 4 بسیار انعطاف پذیر هستند، پیش بینی آنها در محیط های تولید بسیار دشوار است. بنابراین، بیشتر معماریهای سازمانی بر روی سطح 3: جریانهای کاری هدایتشده ساخته شدهاند که قابلیت اطمینان قطعی ماشینهای حالت نرمافزار را با استدلال پویا LLM ترکیب میکند.
2. ستون های اصلی گردش کار مستقل
برای ایجاد یک گردش کار مستقل، باید چهار جزء اساسی را ترکیب کنید:
الف. استدلال و برنامه ریزی
در قلب جریان کار، پارادایم برنامه ریزی قرار دارد. یک تماس ساده لوحانه LLM سعی می کند بلافاصله پاسخ نهایی را صادر کند، که اغلب منجر به شکست استدلال می شود. گردش کار مستقل از حلقه های برنامه ریزی تخصصی استفاده می کند:
- **ReAct (Reason + Act) **: مدل به طور مکرر فکر می کند، عمل می کند (یک ابزار را صدا می کند) و نتیجه را مشاهده می کند و این حلقه را تا رسیدن به هدف تکرار می کند.
- زنجیره فکر (CoT): مجبور کردن مدل به خروجی استدلال گام به گام قبل از رسیدن به نتیجه.
- درخت افکار (ToT): ایجاد و ارزیابی مسیرهای جایگزین متعدد، پیگیری شاخه های مختلف و عقب نشینی در صورت شکست یک مسیر.
ب. حافظه کوتاه مدت و بلند مدت
یک سیستم خودمختار باید حالت را در طول چرخه های اجرایی متعدد حفظ کند:
- حافظه کوتاه مدت: زمینه رشته، متغیرهای حالت و گزارش های اجرایی که کارهایی را که گردش کار در حال حاضر انجام می دهد را پیگیری می کند.
- حافظه بلند مدت: پایگاه های داده برداری و سیستم های بازیابی معنایی که به گردش کار اجازه می دهد تا اجراهای تاریخی، تنظیمات برگزیده کاربر و اسناد سازمانی را به خاطر بیاورد.
ج. ابزارها و ادغام وب
برای عمل در دنیای فیزیکی یا دیجیتالی، LLM ها باید با خدمات خارجی ارتباط برقرار کنند. این مدل نیاز به دسترسی به درایورهای پایگاه داده، سیستم های فایل، مرورگرهای وب و API های شخص ثالث دارد. گردشهای کاری مدرن به طور فزایندهای از پروتکل زمینه مدل (MCP) استفاده میکنند، که استانداردسازی نحوه کشف و اتصال ایمن LLMها به منابع داده متنی و جعبههای ایمنی اجرایی است.
3. الگوهای کلیدی طراحی معماری
مهندسین نرم افزار هنگام ساختن سیستم های پیچیده عاملی، برای مدیریت پیچیدگی و حفظ قابلیت پیش بینی، بر مجموعه ای از الگوهای طراحی اثبات شده تکیه می کنند:
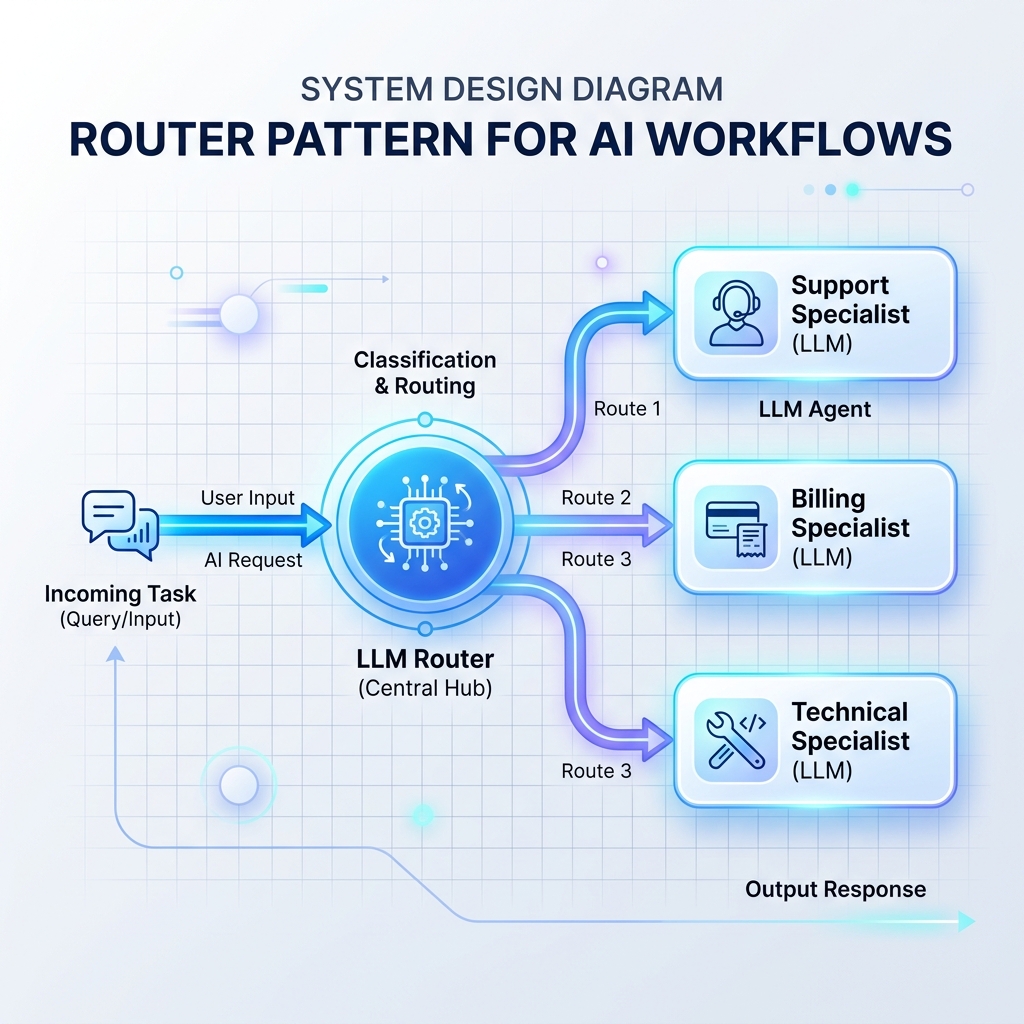
الگوی 1: الگوی روتر
روتر ورودیهای ورودی را میخواند و تصمیم میگیرد که کدام درخواست تخصصی LLM، پایگاه داده یا کنترلکننده API باید آن را پردازش کند. این امر مانع از بارگیری یک دستور LLM یکپارچه با دستورالعمل های بیش از حد می شود.
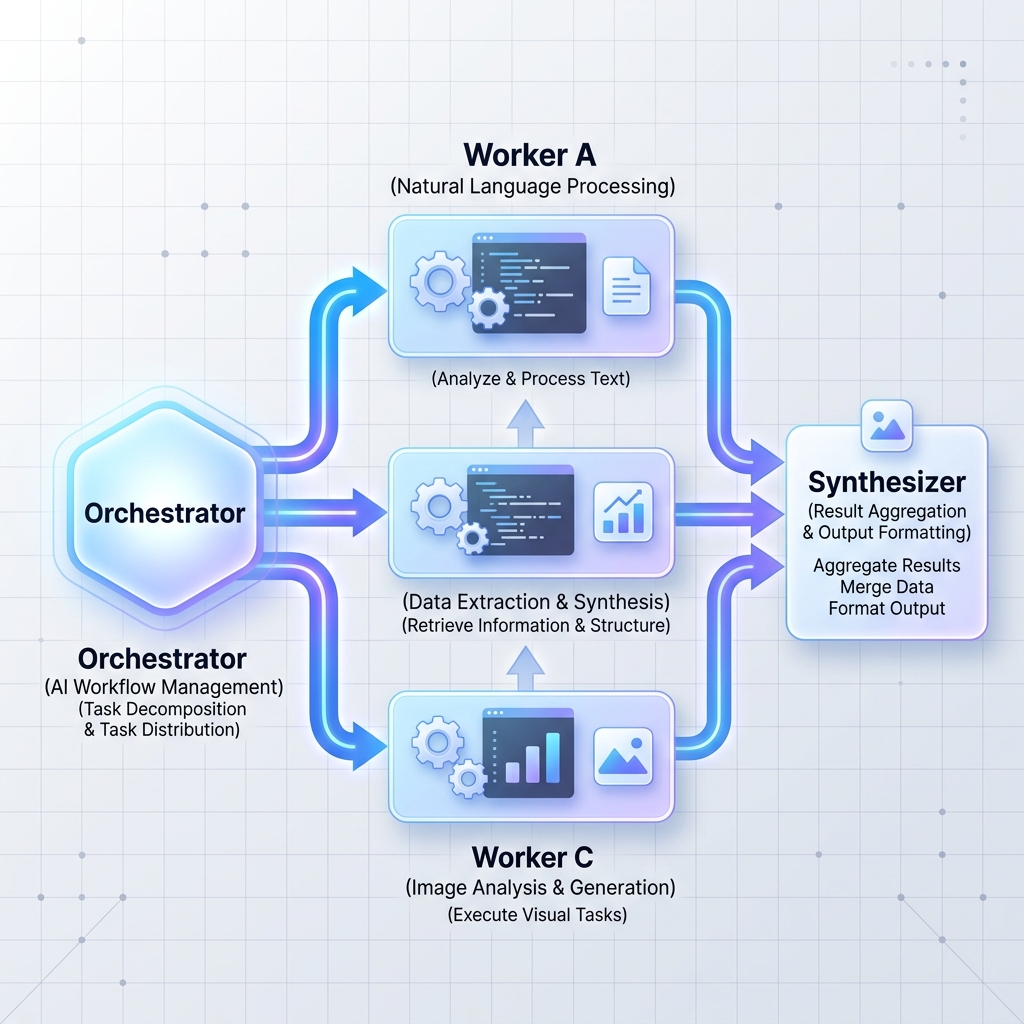
الگوی 2: ارکستراتور-کارگران
یک ارکستراتور مرکزی LLM یک کار بزرگ و پیچیده را به وظایف فرعی مستقل تقسیم می کند. سپس این وظایف را به گره های کارگر (که می توانند LLM های تخصصی یا میکروسرویس های استاندارد باشند) محول می کند و نتایج را ترکیب می کند.
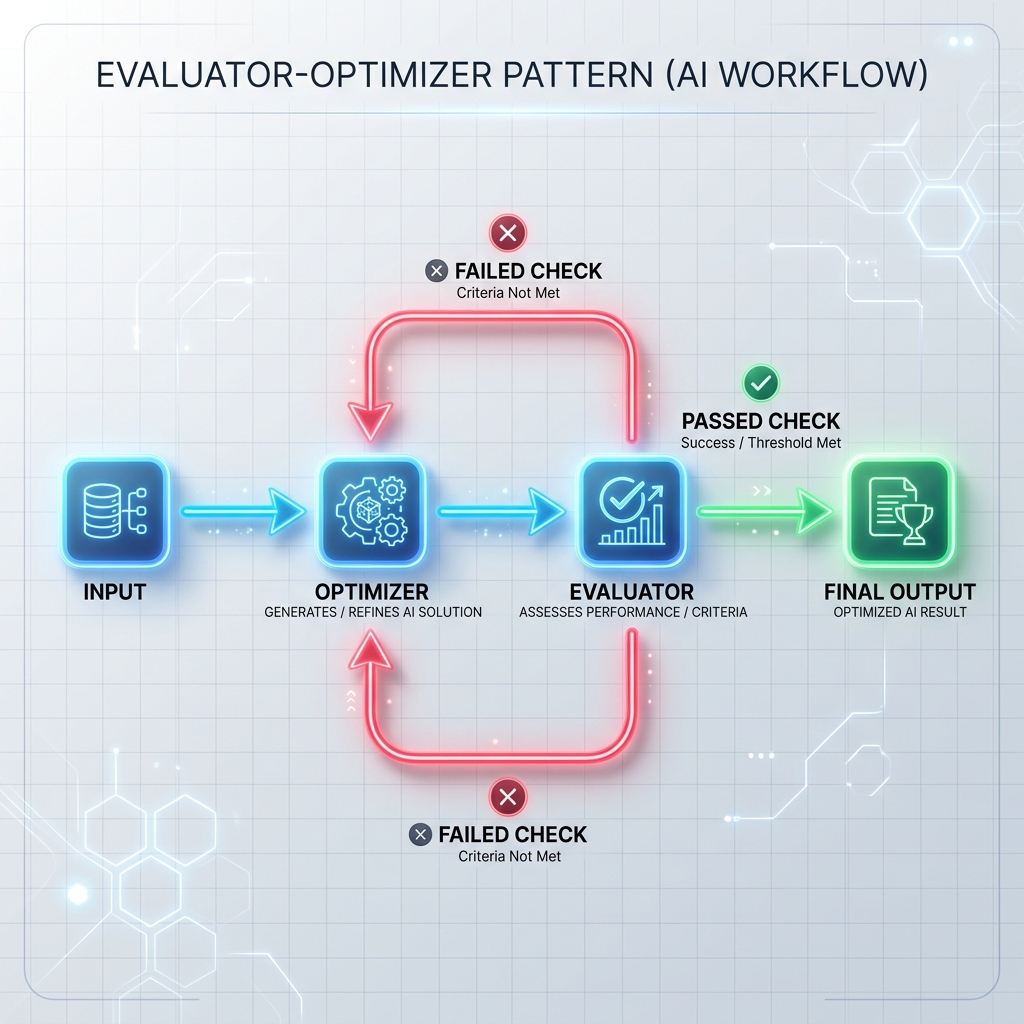
الگوی 3: حلقه ارزیابی کننده-بهینه ساز
بهینه ساز یک پاسخ پیش نویس تولید می کند یا یک کار را اجرا می کند، و ارزیاب آن را بر اساس معیارهای رسمی (مانند تست های واحد، اسکنرهای امنیتی، یا یک درخواست ارزیابی جداگانه) بررسی می کند. اگر بررسی ناموفق باشد، بازخورد به بهینهساز بازگردانده میشود تا پاسخ را دوباره تولید کند.
4. ساخت یک عامل مبتنی بر دولت در پایتون
بیایید به اجرای مشخص یک عامل مستقل با استفاده از یک ماشین حالت ساده نگاه کنیم. ما نماینده ای را تعریف می کنیم که درخواست های بازپرداخت را پردازش می کند. نماینده تاریخچه خرید مشتری را بررسی میکند، درخواست را در برابر خطمشیها تأیید میکند، یک پاسخ ایمیل را پیشنویس میکند و اگر بازپرداخت بیش از 100 دلار باشد، تأییدیه انسانی را درخواست میکند.
import json
from typing import Dict, Any
# Mock databases and tools
PURCHASE_DB = {
"user_123": {"item": "Premium Subscription", "price": 149.00, "days_ago": 12},
"user_456": {"item": "Basic License", "price": 49.00, "days_ago": 45}
}
class AutonomousRefundAgent:
def __init__(self):
self.state: Dict[str, Any] = {
"step": "INIT",
"user_id": None,
"refund_amount": 0.0,
"policy_passed": False,
"requires_approval": False,
"approved": False,
"response_draft": "",
"log": []
}
def run(self, user_id: str, request_text: str):
self.state["user_id"] = user_id
self.state["log"].append(f"Started workflow for user {user_id} with request: '{request_text}'")
while self.state["step"] != "COMPLETE":
current_step = self.state["step"]
if current_step == "INIT":
self._fetch_user_data()
elif current_step == "VALIDATE_POLICY":
self._validate_policy()
elif current_step == "CHECK_APPROVAL":
self._check_approval_requirements()
elif current_step == "WAITING_FOR_HUMAN":
# Pause execution and yield control back to the orchestrator
self.state["log"].append("Execution paused: waiting for human operator approval.")
break
elif current_step == "EXECUTE_REFUND":
self._execute_refund()
elif current_step == "DRAFT_RESPONSE":
self._draft_response()
return self.state
def _fetch_user_data(self):
user_id = self.state["user_id"]
purchase = PURCHASE_DB.get(user_id)
if not purchase:
self.state["response_draft"] = "No purchase history found for this user."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Fetch failed: User not found in database.")
return
self.state["refund_amount"] = purchase["price"]
self.state["purchase_age_days"] = purchase["days_ago"]
self.state["step"] = "VALIDATE_POLICY"
self.state["log"].append(f"Fetched purchase data: {purchase}")
def _validate_policy(self):
# Business rule: Refunds only allowed within 30 days
age = self.state["purchase_age_days"]
if age <= 30:
self.state["policy_passed"] = True
self.state["step"] = "CHECK_APPROVAL"
self.state["log"].append("Policy validation passed (within 30-day window).")
else:
self.state["policy_passed"] = False
self.state["response_draft"] = "Sorry, our policy only allows refunds within 30 days of purchase."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Policy validation failed: Purchase older than 30 days.")
def _check_approval_requirements(self):
# Business rule: Refunds over $100 require human review
amount = self.state["refund_amount"]
if amount > 100.0:
self.state["requires_approval"] = True
self.state["step"] = "WAITING_FOR_HUMAN"
self.state["log"].append(f"Refund of ${amount} exceeds limit. Moving to human approval state.")
else:
self.state["requires_approval"] = False
self.state["step"] = "EXECUTE_REFUND"
self.state["log"].append(f"Refund of ${amount} is within limits. Proceeding to execution.")
def resume_with_human_decision(self, approved: bool):
if self.state["step"] != "WAITING_FOR_HUMAN":
raise ValueError("Agent is not currently waiting for approval.")
self.state["approved"] = approved
self.state["log"].append(f"Human manager decision received: Approved = {approved}")
if approved:
self.state["step"] = "EXECUTE_REFUND"
else:
self.state["response_draft"] = "Your refund request has been reviewed and declined by a customer service manager."
self.state["step"] = "DRAFT_RESPONSE"
# Resume the workflow loop
return self.run(self.state["user_id"], "")
def _execute_refund(self):
amount = self.state["refund_amount"]
# Trigger actual external API call/Stripe integration here
self.state["log"].append(f"Successfully processed stripe refund for ${amount}.")
self.state["response_draft"] = f"Your refund request for ${amount} has been successfully processed."
self.state["step"] = "DRAFT_RESPONSE"
def _draft_response(self):
# Prompt LLM to draft a polite, personalized message incorporating response_draft
self.state["final_message"] = f"Dear Customer,\n\n{self.state['response_draft']}\n\nBest regards,\nGhaznix Support Agent"
self.state["step"] = "COMPLETE"
self.state["log"].append("Customer email drafted successfully. Workflow complete.")
5. قابلیت اطمینان تولید و حفاظ های امنیتی
استقرار سیستمهای مستقل نیاز به تغییر در نحوه تفکر ما در مورد آزمایش و رسیدگی به خطا دارد. در اینجا نرده های حفاظ مهمی وجود دارد که باید در هر سیستم تولیدی بسازید:
A. جلوگیری از حلقه های اعدام فراری
یک عامل مستقل که با یک خطا یا یک edge case مواجه میشود، ممکن است به طور مکرر همان ابزار را جستجو کند و هزاران دلار در هزینههای API در عرض چند دقیقه هزینه کند.
- راه حل: حداکثر محدودیت های اجرا را اعمال کنید. همیشه یک سقف سخت برای تعداد مراحل یا کل نشانههای مدل مجاز در هر نمونه گردش کار تعریف کنید (مثلاً حداکثر 10 تکرار).
ب. اعتبار سنجی طرحواره ساختاری
LLM ها احتمالی هستند و به طور طبیعی خروجی های ساختار یافته مانند JSON معتبر یا طرحواره های منطبق را تضمین نمی کنند.
- راه حل: از کتابخانه های اعتبارسنجی مانند Pydantic، Instructor یا Outlines برای اجرای ساختار در سطح استنتاج استفاده کنید. اگر مدلی طرحوارههای نامعتبر را خروجی میدهد، آن را زودتر رد کنید و از مدل با خطای تجزیه بخواهید خودش را اصلاح کند (بخشی از حلقه ارزیاب-بهینهساز).
ج. اجرای کد
اگر عامل شما کد می نویسد و اجرا می کند (مانند تجزیه و تحلیل داده ها یا تبدیل پایگاه داده)، اجرای مستقیم آن بر روی سرور برنامه شما یک آسیب پذیری امنیتی بزرگ است.
- راه حل: از محیط های میکرو VM ایمن و زودگذر (مانند کانتینرهای Docker، gVisor یا زمان های اجرا WASM) برای اجرای ایمن اسکریپت های تولید شده توسط کاربر یا تولید شده توسط عامل استفاده کنید.
نتیجه گیری
ایجاد جریانهای کاری هوش مصنوعی مستقل با LLM نیازمند پر کردن شکاف بین استدلال انعطافپذیر هوش مصنوعی و رشته مهندسی ساختیافته است. با جایگزینی عوامل باز با گردشهای کاری هدایتشده توسط ماشین دولتی، ساختاردهی وظایف از طریق الگوهایی مانند Orchestrator-Workers، و قرار دادن همه چیز در اجرای دقیق و حفاظهای امنیتی، توسعهدهندگان میتوانند سیستمهایی بسازند که هم بسیار هوشمند و هم برای شرکتها آماده باشند.
آینده معماری نرم افزار در مورد جایگزین کردن کد با اعلان ها نیست - بلکه در مورد عوامل هماهنگ و سیستم های قطعی برای ایجاد جریان های کاری است که به طور مستقل عمل می کنند، به صورت پویا یاد می گیرند و نتایج را به طور قابل اعتماد ارائه می دهند.
مقالات بیشتر مهندسی هوش مصنوعی را در وبلاگ غزنیکس کاوش کنید →