Creación de flujos de trabajo de IA autónomos con LLM

Los grandes modelos de lenguaje (LLM) han transformado la forma en que interactuamos con la tecnología, pasando rápidamente de simples chatbots conversacionales a motores de razonamiento capaces de impulsar acciones complejas de varios pasos. Si bien una única interacción de respuesta rápida puede ser poderosa, el valor real de la IA generativa en entornos empresariales reside en los flujos de trabajo de IA autónomos.
En lugar de depender de operadores humanos para orquestar cada paso, los flujos de trabajo autónomos utilizan a los LLM como tomadores de decisiones centrales que planifican, ejecutan, evalúan y autocorrigen tareas durante largos períodos.
Esta inmersión profunda explora cómo diseñar, construir e implementar flujos de trabajo de IA autónomos y confiables utilizando patrones de diseño modernos, máquinas de estado y barreras de seguridad sólidas.
1. El cambio agente: chatbots versus flujos de trabajo
La evolución de las aplicaciones LLM se puede clasificar en cuatro niveles distintos de autonomía:
| Nivel | paradigma | Papel Humano | Mecanismo central |
|---|---|---|---|
| Nivel 1 | Chat conversacional | Alto (Avisa en cada turno) | Terminaciones de una sola vuelta sin estado |
| Nivel 2 | Llamada de herramientas/llamada de funciones | Medio (proporciona contexto) | El modelo elige la API para llamar; devuelve resultado |
| Nivel 3 | Flujos de trabajo dirigidos | Baja (Define metas y gráfica) | Máquina de estado codificada con enrutamiento LLM |
| Nivel 4 | Agentes Totalmente Autónomos | Mínimo (Define objetivo/presupuesto) | Ciclos de planificación, ejecución y reflexión impulsados por LLM |
Si bien los agentes de nivel 4 son muy flexibles, son notoriamente difíciles de predecir en entornos de producción. Por lo tanto, la mayoría de las arquitecturas empresariales se basan en el Nivel 3: flujos de trabajo dirigidos, que combina la confiabilidad determinista de las máquinas de estado del software con el razonamiento dinámico de los LLM.
2. Pilares centrales de los flujos de trabajo autónomos
Para crear un flujo de trabajo autónomo, es necesario combinar cuatro componentes fundamentales:
A. Razonamiento y planificación
En el corazón del flujo de trabajo se encuentra el paradigma de planificación. Una ingenua llamada de LLM intenta generar la respuesta final de inmediato, lo que a menudo conduce a fallas de razonamiento. Los flujos de trabajo autónomos utilizan bucles de planificación especializados:
- ReAct (Razón + Actuación): el modelo piensa, actúa (llama a una herramienta) y observa el resultado de forma iterativa, repitiendo este ciclo hasta que se logra el objetivo.
- Cadena de pensamiento (CoT): Obligar al modelo a generar su razonamiento paso a paso antes de llegar a una conclusión.
- Árbol de pensamientos (ToT): generar y evaluar múltiples caminos alternativos, realizar un seguimiento de diferentes ramas y retroceder cuando un camino falla.
B. Memoria a corto y largo plazo
Un sistema autónomo debe mantener el estado a lo largo de múltiples ciclos de ejecución:
- Memoria a corto plazo: el contexto del subproceso, las variables de estado y los registros de ejecución que realizan un seguimiento de lo que el flujo de trabajo está haciendo actualmente.
- Memoria a largo plazo: bases de datos vectoriales y sistemas de recuperación semántica que permiten que el flujo de trabajo recuerde ejecuciones históricas, preferencias del usuario y documentación empresarial.
C. Herramientas e integración web
Para actuar en el mundo físico o digital, los LLM deben interactuar con servicios externos. El modelo necesita acceso a controladores de bases de datos, sistemas de archivos, navegadores web y API de terceros. Los flujos de trabajo modernos adoptan cada vez más el Protocolo de contexto modelo (MCP), estandarizando cómo los LLM descubren y se conectan de forma segura a fuentes de datos contextuales y entornos limitados de ejecución.
3. Patrones clave de diseño arquitectónico
Al crear sistemas agentes complejos, los ingenieros de software confían en un conjunto de patrones de diseño probados para gestionar la complejidad y mantener la previsibilidad:
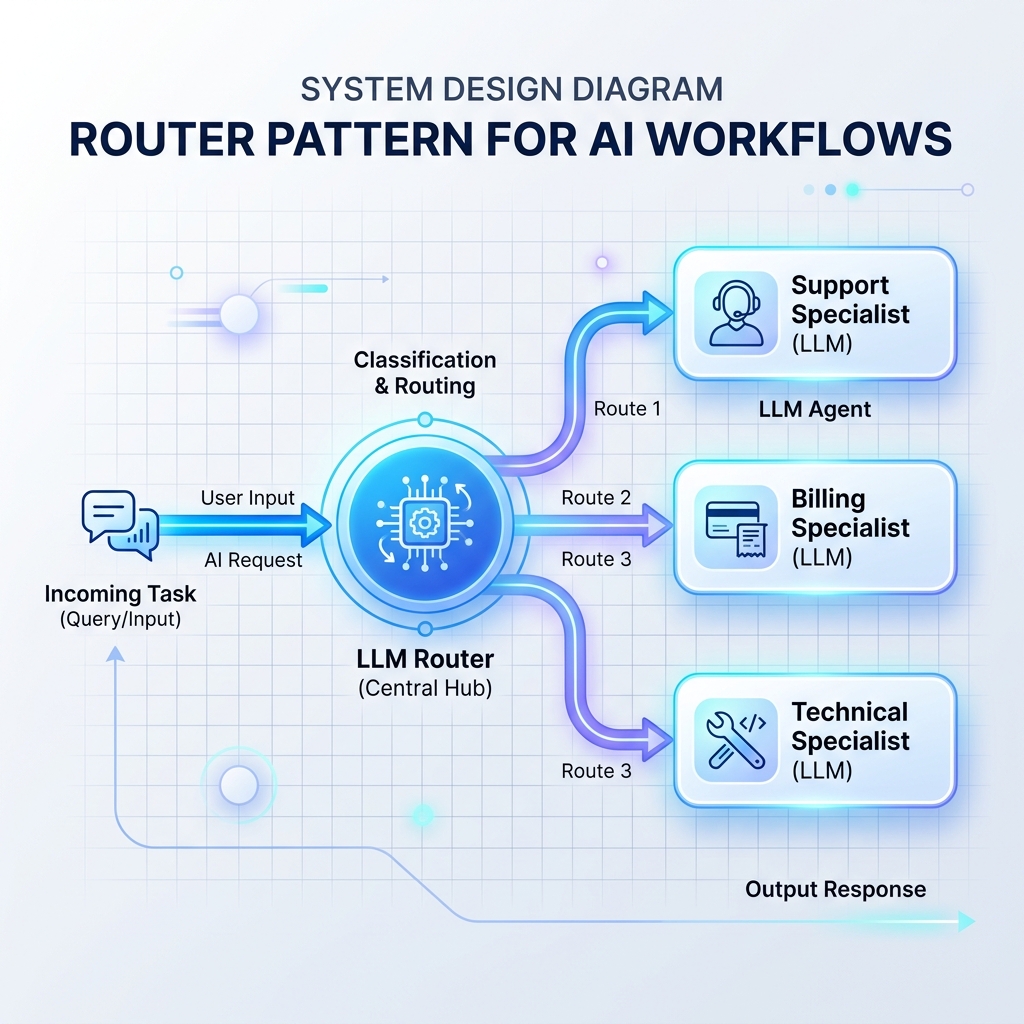
Patrón 1: El patrón del enrutador
Un enrutador lee las entradas entrantes y decide qué indicador LLM especializado, base de datos o controlador API debe procesarlo a continuación. Esto evita que un mensaje LLM único y monolítico se sobrecargue con demasiadas instrucciones.
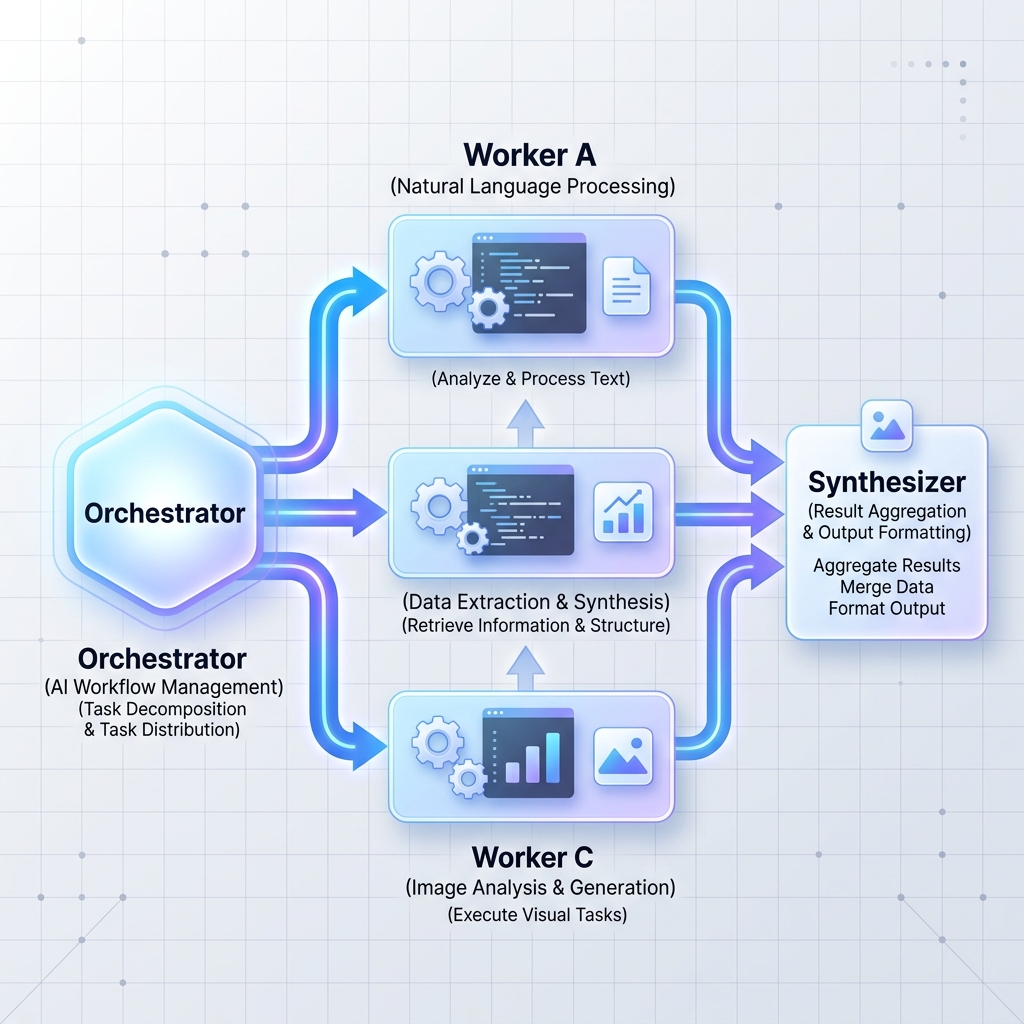
Patrón 2: Orquestador-Trabajadores
Un LLM de orquestador central divide una tarea grande y compleja en subtareas independientes. Luego delega estas tareas a nodos trabajadores (que pueden ser LLM especializados o microservicios estándar) y sintetiza los resultados.
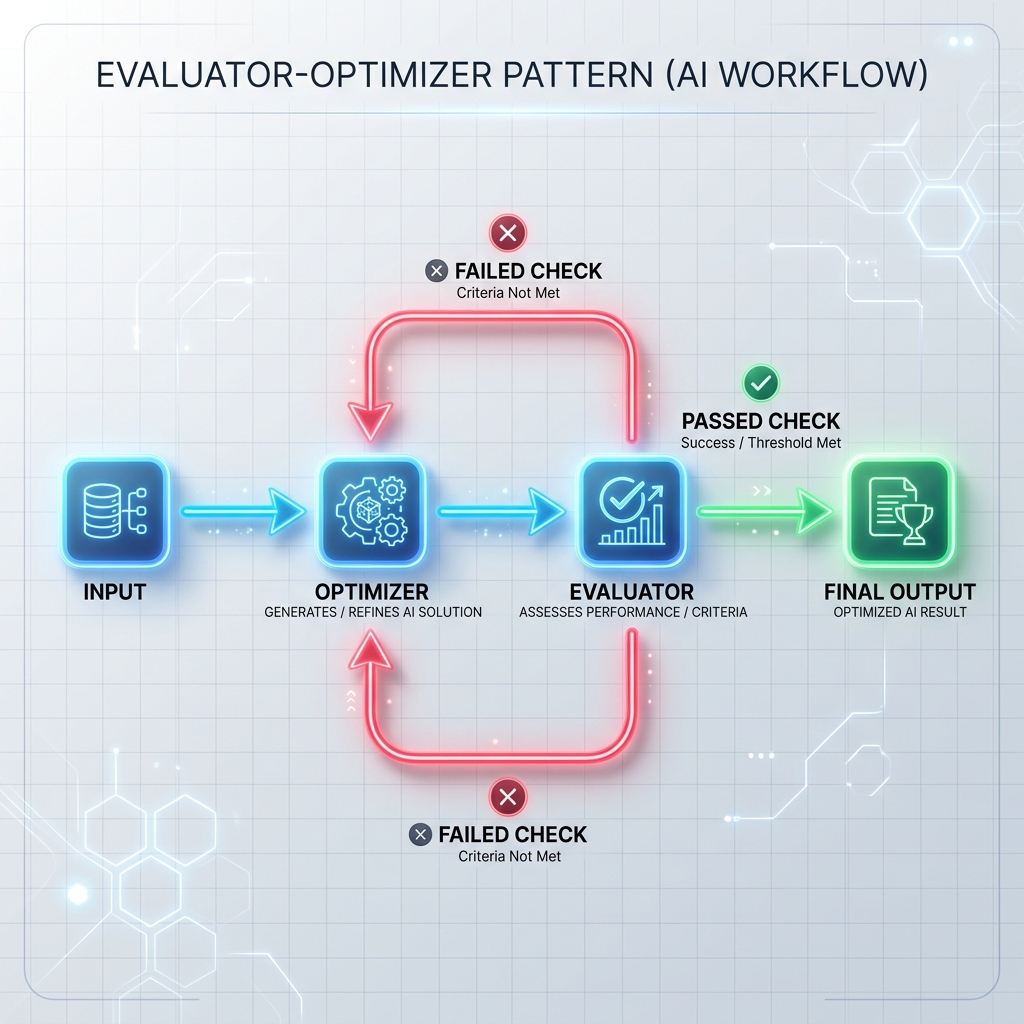
Patrón 3: Bucle evaluador-optimizador
El optimizador genera un borrador de respuesta o ejecuta una tarea, y el evaluador lo compara con criterios formales (como pruebas unitarias, escáneres de seguridad o un mensaje de evaluación separado). Si la verificación falla, la retroalimentación se devuelve al optimizador para regenerar la respuesta.
4. Construyendo un agente basado en estado en Python
Veamos una implementación concreta de un agente autónomo utilizando una máquina de estados simple. Definiremos un agente que procese las solicitudes de reembolso. El agente verifica el historial de compras del cliente, valida la solicitud según las políticas, redacta una respuesta por correo electrónico y solicita la aprobación humana si el reembolso supera los $100.
import json
from typing import Dict, Any
# Mock databases and tools
PURCHASE_DB = {
"user_123": {"item": "Premium Subscription", "price": 149.00, "days_ago": 12},
"user_456": {"item": "Basic License", "price": 49.00, "days_ago": 45}
}
class AutonomousRefundAgent:
def __init__(self):
self.state: Dict[str, Any] = {
"step": "INIT",
"user_id": None,
"refund_amount": 0.0,
"policy_passed": False,
"requires_approval": False,
"approved": False,
"response_draft": "",
"log": []
}
def run(self, user_id: str, request_text: str):
self.state["user_id"] = user_id
self.state["log"].append(f"Started workflow for user {user_id} with request: '{request_text}'")
while self.state["step"] != "COMPLETE":
current_step = self.state["step"]
if current_step == "INIT":
self._fetch_user_data()
elif current_step == "VALIDATE_POLICY":
self._validate_policy()
elif current_step == "CHECK_APPROVAL":
self._check_approval_requirements()
elif current_step == "WAITING_FOR_HUMAN":
# Pause execution and yield control back to the orchestrator
self.state["log"].append("Execution paused: waiting for human operator approval.")
break
elif current_step == "EXECUTE_REFUND":
self._execute_refund()
elif current_step == "DRAFT_RESPONSE":
self._draft_response()
return self.state
def _fetch_user_data(self):
user_id = self.state["user_id"]
purchase = PURCHASE_DB.get(user_id)
if not purchase:
self.state["response_draft"] = "No purchase history found for this user."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Fetch failed: User not found in database.")
return
self.state["refund_amount"] = purchase["price"]
self.state["purchase_age_days"] = purchase["days_ago"]
self.state["step"] = "VALIDATE_POLICY"
self.state["log"].append(f"Fetched purchase data: {purchase}")
def _validate_policy(self):
# Business rule: Refunds only allowed within 30 days
age = self.state["purchase_age_days"]
if age <= 30:
self.state["policy_passed"] = True
self.state["step"] = "CHECK_APPROVAL"
self.state["log"].append("Policy validation passed (within 30-day window).")
else:
self.state["policy_passed"] = False
self.state["response_draft"] = "Sorry, our policy only allows refunds within 30 days of purchase."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Policy validation failed: Purchase older than 30 days.")
def _check_approval_requirements(self):
# Business rule: Refunds over $100 require human review
amount = self.state["refund_amount"]
if amount > 100.0:
self.state["requires_approval"] = True
self.state["step"] = "WAITING_FOR_HUMAN"
self.state["log"].append(f"Refund of ${amount} exceeds limit. Moving to human approval state.")
else:
self.state["requires_approval"] = False
self.state["step"] = "EXECUTE_REFUND"
self.state["log"].append(f"Refund of ${amount} is within limits. Proceeding to execution.")
def resume_with_human_decision(self, approved: bool):
if self.state["step"] != "WAITING_FOR_HUMAN":
raise ValueError("Agent is not currently waiting for approval.")
self.state["approved"] = approved
self.state["log"].append(f"Human manager decision received: Approved = {approved}")
if approved:
self.state["step"] = "EXECUTE_REFUND"
else:
self.state["response_draft"] = "Your refund request has been reviewed and declined by a customer service manager."
self.state["step"] = "DRAFT_RESPONSE"
# Resume the workflow loop
return self.run(self.state["user_id"], "")
def _execute_refund(self):
amount = self.state["refund_amount"]
# Trigger actual external API call/Stripe integration here
self.state["log"].append(f"Successfully processed stripe refund for ${amount}.")
self.state["response_draft"] = f"Your refund request for ${amount} has been successfully processed."
self.state["step"] = "DRAFT_RESPONSE"
def _draft_response(self):
# Prompt LLM to draft a polite, personalized message incorporating response_draft
self.state["final_message"] = f"Dear Customer,\n\n{self.state['response_draft']}\n\nBest regards,\nGhaznix Support Agent"
self.state["step"] = "COMPLETE"
self.state["log"].append("Customer email drafted successfully. Workflow complete.")
5. Barandillas de seguridad y confiabilidad de la producción
La implementación de sistemas autónomos requiere un cambio en nuestra forma de pensar sobre las pruebas y el manejo de errores. Estas son las barreras críticas que debe incorporar a cualquier sistema de producción:
A. Prevención de bucles de ejecución fuera de control
Un agente autónomo que encuentre un error o un caso límite podría consultar la misma herramienta repetidamente, gastando miles de dólares en costos de API en cuestión de minutos.
- Solución: Implementar límites máximos de ejecución. Defina siempre un límite máximo en la cantidad de pasos o tokens de modelo totales permitidos por instancia de flujo de trabajo (por ejemplo, un máximo de 10 iteraciones).
B. Validación del esquema estructural
Los LLM son probabilísticos y, naturalmente, no garantizan resultados estructurados como JSON válido o esquemas coincidentes.
- Solución: Utilice bibliotecas de validación como Pydantic, Instructor o Outlines para imponer la estructura en el nivel de inferencia. Si un modelo genera esquemas no válidos, rechácelo temprano y solicite al modelo con el error de análisis que se solucione solo (parte del ciclo Evaluador-Optimizador).
C. Ejecución de código en Sandbox
Si su agente escribe y ejecuta código (como análisis de datos o transformaciones de bases de datos), ejecutarlo directamente en su servidor de aplicaciones es una vulnerabilidad de seguridad importante.
- Solución: utilice entornos de micro-VM seguros y efímeros (como contenedores Docker, gVisor o tiempos de ejecución WASM) para ejecutar scripts generados por usuarios o agentes de forma segura.
Conclusión
Crear flujos de trabajo de IA autónomos con LLM requiere cerrar la brecha entre el razonamiento de IA flexible y la disciplina de ingeniería estructurada. Al reemplazar los agentes abiertos con flujos de trabajo dirigidos por máquinas de estado, estructurar tareas a través de patrones como Orchestrator-Workers y envolver todo en estrictas barreras de seguridad y ejecución, los desarrolladores pueden crear sistemas que sean altamente inteligentes y estén preparados para la empresa.
El futuro de la arquitectura de software no se trata de reemplazar el código con indicaciones, sino de orquestar agentes y sistemas deterministas para crear flujos de trabajo que funcionen de forma autónoma, aprendan dinámicamente y entreguen resultados de manera confiable.
Explore más artículos de ingeniería de IA en el Blog de Ghaznix →