Construindo fluxos de trabalho de IA autônomos com LLMs

Os Large Language Models (LLMs) transformaram a forma como interagimos com a tecnologia, passando rapidamente de simples chatbots de conversação para motores de raciocínio capazes de conduzir ações complexas e em várias etapas. Embora uma única interação de resposta imediata possa ser poderosa, o valor real da IA generativa em ambientes empresariais está nos Fluxos de trabalho de IA autônomos.
Em vez de depender de operadores humanos para orquestrar cada etapa, os fluxos de trabalho autônomos usam LLMs como tomadores de decisão centrais que planejam, executam, avaliam e autocorrigem tarefas durante longos períodos.
Este mergulho profundo explora como arquitetar, construir e implantar fluxos de trabalho de IA autônomos e confiáveis usando padrões de design modernos, máquinas de estado e proteções robustas.
1. A mudança agente: chatbots vs. fluxos de trabalho
A evolução das aplicações LLM pode ser categorizada em quatro níveis distintos de autonomia:
| Nível | Paradigma | Papel Humano | Mecanismo Central |
|---|---|---|---|
| Nível 1 | Bate-papo conversacional | Alto (solicita a cada turno) | Completações de volta única sem estado |
| Nível 2 | Chamada de ferramenta/chamada de função | Médio (fornece contexto) | O modelo escolhe a API para chamar; retorna resultado |
| Nível 3 | Fluxos de trabalho direcionados | Baixo (Define metas e gráfico) | Máquina de estado codificada com roteamento LLM |
| Nível 4 | Agentes Totalmente Autônomos | Mínimo (Define objetivo/orçamento) | Ciclos de planejamento, execução e reflexão orientados por LLM |
Embora os agentes de Nível 4 sejam altamente flexíveis, eles são notoriamente difíceis de prever em ambientes de produção. Portanto, a maioria das arquiteturas empresariais são construídas no Nível 3: fluxos de trabalho direcionados, combinando a confiabilidade determinística das máquinas de estado de software com o raciocínio dinâmico dos LLMs.
2. Pilares Fundamentais dos Fluxos de Trabalho Autônomos
Para construir um fluxo de trabalho autônomo, você precisa combinar quatro componentes fundamentais:
A. Raciocínio e planejamento
No centro do fluxo de trabalho está o paradigma de planejamento. Uma chamada ingênua de LLM tenta produzir a resposta final imediatamente, o que muitas vezes leva a falhas de raciocínio. Os fluxos de trabalho autônomos usam ciclos de planejamento especializados:
- ReAct (Razão + Ação): O modelo pensa, age (chama uma ferramenta) iterativamente e observa o resultado, repetindo esse ciclo até que o objetivo seja alcançado.
- Cadeia de Pensamento (CoT): Forçar o modelo a apresentar seu raciocínio passo a passo antes de chegar a uma conclusão.
- Árvore de Pensamentos (ToT): Geração e avaliação de vários caminhos alternativos, acompanhamento de diferentes ramificações e retrocesso quando um caminho falha.
B. Memória de curto e longo prazo
Um sistema autônomo deve manter o estado em vários ciclos de execução:
- Memória de curto prazo: o contexto do thread, as variáveis de estado e os logs de execução que controlam o que o fluxo de trabalho está fazendo no momento.
- Memória de longo prazo: bancos de dados vetoriais e sistemas de recuperação semântica que permitem que o fluxo de trabalho recupere execuções históricas, preferências do usuário e documentação empresarial.
C. Ferramentas e integração web
Para atuar no mundo físico ou digital, os LLMs devem interagir com serviços externos. O modelo precisa de acesso a drivers de banco de dados, sistemas de arquivos, navegadores da web e APIs de terceiros. Os fluxos de trabalho modernos estão adotando cada vez mais o Model Context Protocol (MCP), padronizando como os LLMs descobrem e se conectam com segurança a fontes de dados contextuais e sandboxes de execução.
3. Principais padrões de projeto arquitetônico
Ao construir sistemas agentes complexos, os engenheiros de software contam com um conjunto de padrões de design comprovados para gerenciar a complexidade e manter a previsibilidade:
Padrão 1: O padrão do roteador
Um roteador lê as entradas recebidas e decide qual prompt LLM especializado, banco de dados ou manipulador de API deve processá-las em seguida. Isso evita que um único prompt LLM monolítico seja sobrecarregado com muitas instruções.
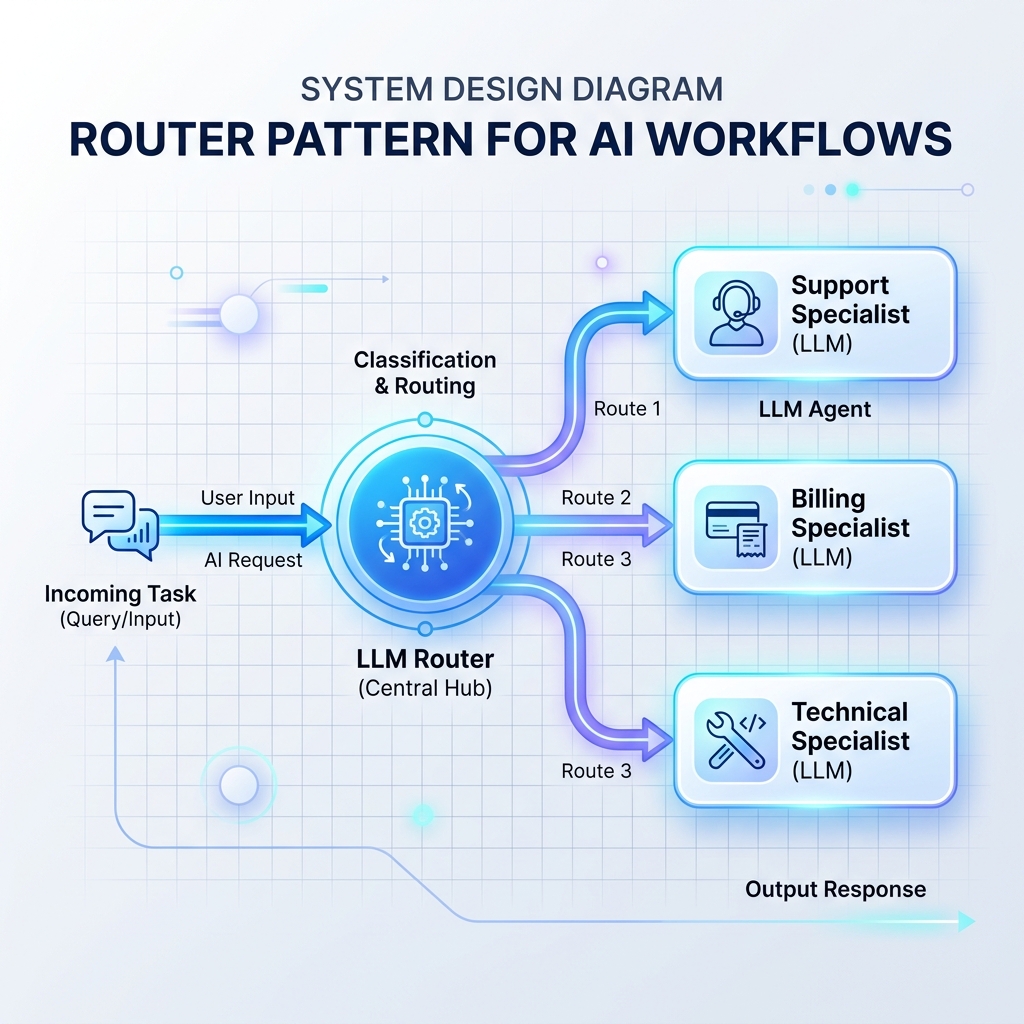
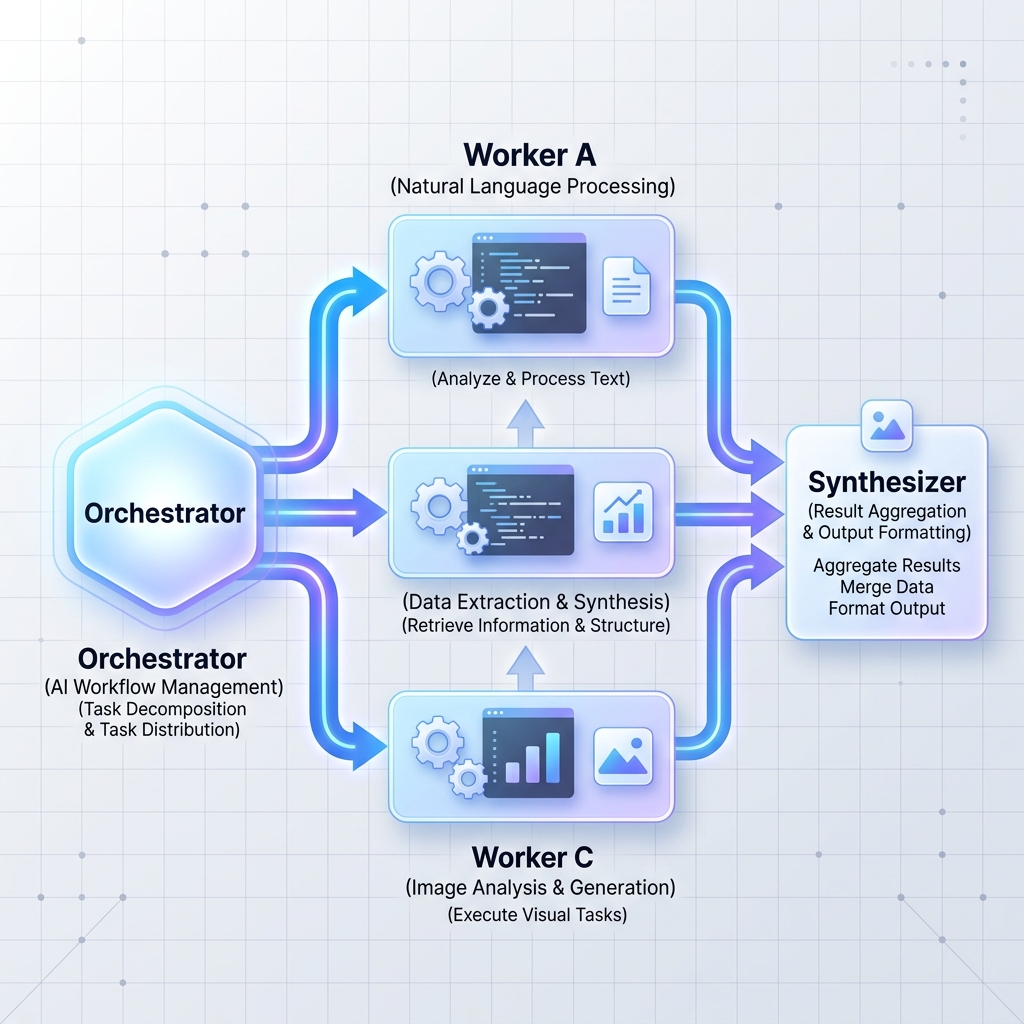
Padrão 2: Trabalhadores orquestradores
Um orquestrador central LLM divide uma tarefa grande e complexa em subtarefas independentes. Em seguida, ele delega essas tarefas aos nós de trabalho (que podem ser LLMs especializados ou microsserviços padrão) e sintetiza os resultados.
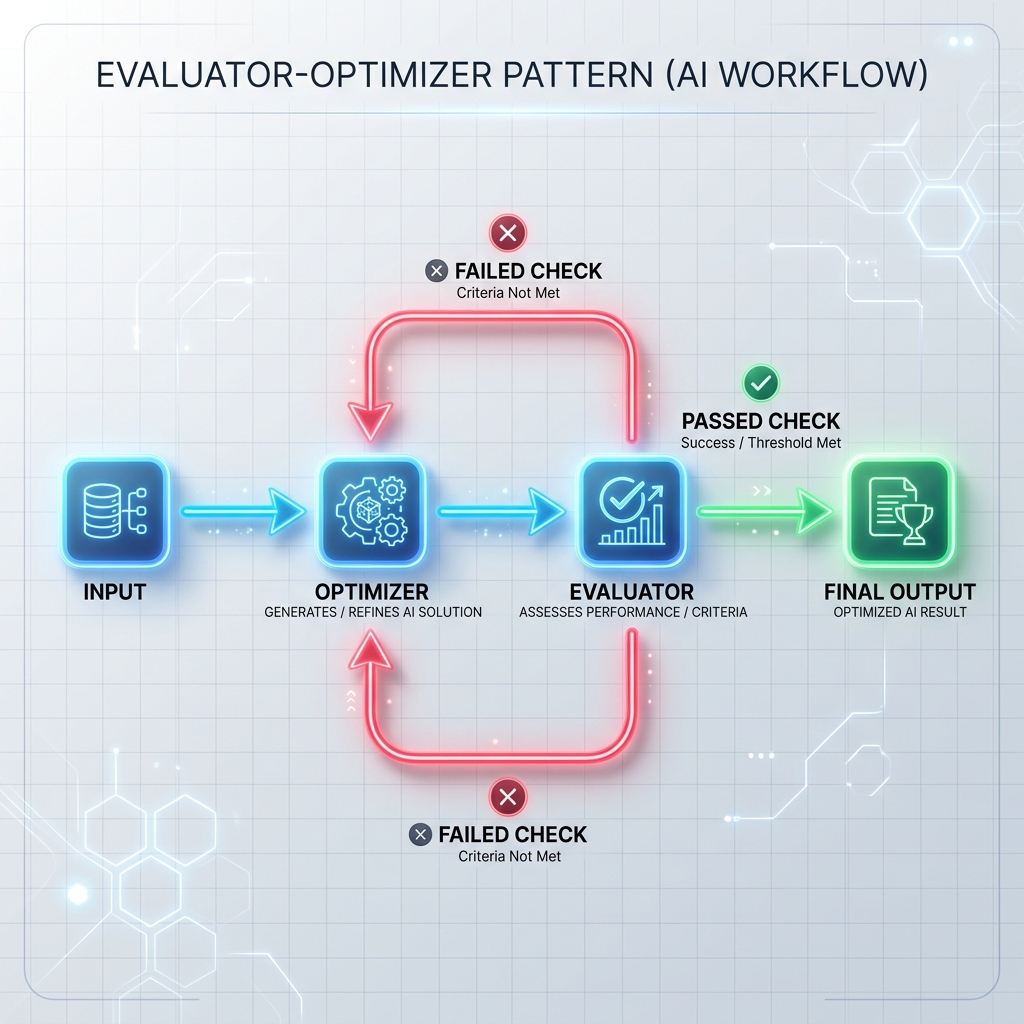
Padrão 3: Ciclo Avaliador-Otimizador
O otimizador gera um rascunho de resposta ou executa uma tarefa, e o avaliador a verifica em relação a critérios formais (como testes de unidade, scanners de segurança ou um prompt de avaliação separado). Se a verificação falhar, o feedback será repassado ao otimizador para regenerar a resposta.
4. Construindo um agente baseado em estado em Python
Vejamos uma implementação concreta de um agente autônomo usando uma máquina de estados simples. Definiremos um agente que processe as solicitações de reembolso. O agente verifica o histórico de compras do cliente, valida a solicitação em relação às políticas, redige uma resposta por e-mail e solicita aprovação humana se o reembolso exceder US$ 100.
import json
from typing import Dict, Any
# Mock databases and tools
PURCHASE_DB = {
"user_123": {"item": "Premium Subscription", "price": 149.00, "days_ago": 12},
"user_456": {"item": "Basic License", "price": 49.00, "days_ago": 45}
}
class AutonomousRefundAgent:
def __init__(self):
self.state: Dict[str, Any] = {
"step": "INIT",
"user_id": None,
"refund_amount": 0.0,
"policy_passed": False,
"requires_approval": False,
"approved": False,
"response_draft": "",
"log": []
}
def run(self, user_id: str, request_text: str):
self.state["user_id"] = user_id
self.state["log"].append(f"Started workflow for user {user_id} with request: '{request_text}'")
while self.state["step"] != "COMPLETE":
current_step = self.state["step"]
if current_step == "INIT":
self._fetch_user_data()
elif current_step == "VALIDATE_POLICY":
self._validate_policy()
elif current_step == "CHECK_APPROVAL":
self._check_approval_requirements()
elif current_step == "WAITING_FOR_HUMAN":
# Pause execution and yield control back to the orchestrator
self.state["log"].append("Execution paused: waiting for human operator approval.")
break
elif current_step == "EXECUTE_REFUND":
self._execute_refund()
elif current_step == "DRAFT_RESPONSE":
self._draft_response()
return self.state
def _fetch_user_data(self):
user_id = self.state["user_id"]
purchase = PURCHASE_DB.get(user_id)
if not purchase:
self.state["response_draft"] = "No purchase history found for this user."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Fetch failed: User not found in database.")
return
self.state["refund_amount"] = purchase["price"]
self.state["purchase_age_days"] = purchase["days_ago"]
self.state["step"] = "VALIDATE_POLICY"
self.state["log"].append(f"Fetched purchase data: {purchase}")
def _validate_policy(self):
# Business rule: Refunds only allowed within 30 days
age = self.state["purchase_age_days"]
if age <= 30:
self.state["policy_passed"] = True
self.state["step"] = "CHECK_APPROVAL"
self.state["log"].append("Policy validation passed (within 30-day window).")
else:
self.state["policy_passed"] = False
self.state["response_draft"] = "Sorry, our policy only allows refunds within 30 days of purchase."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Policy validation failed: Purchase older than 30 days.")
def _check_approval_requirements(self):
# Business rule: Refunds over $100 require human review
amount = self.state["refund_amount"]
if amount > 100.0:
self.state["requires_approval"] = True
self.state["step"] = "WAITING_FOR_HUMAN"
self.state["log"].append(f"Refund of ${amount} exceeds limit. Moving to human approval state.")
else:
self.state["requires_approval"] = False
self.state["step"] = "EXECUTE_REFUND"
self.state["log"].append(f"Refund of ${amount} is within limits. Proceeding to execution.")
def resume_with_human_decision(self, approved: bool):
if self.state["step"] != "WAITING_FOR_HUMAN":
raise ValueError("Agent is not currently waiting for approval.")
self.state["approved"] = approved
self.state["log"].append(f"Human manager decision received: Approved = {approved}")
if approved:
self.state["step"] = "EXECUTE_REFUND"
else:
self.state["response_draft"] = "Your refund request has been reviewed and declined by a customer service manager."
self.state["step"] = "DRAFT_RESPONSE"
# Resume the workflow loop
return self.run(self.state["user_id"], "")
def _execute_refund(self):
amount = self.state["refund_amount"]
# Trigger actual external API call/Stripe integration here
self.state["log"].append(f"Successfully processed stripe refund for ${amount}.")
self.state["response_draft"] = f"Your refund request for ${amount} has been successfully processed."
self.state["step"] = "DRAFT_RESPONSE"
def _draft_response(self):
# Prompt LLM to draft a polite, personalized message incorporating response_draft
self.state["final_message"] = f"Dear Customer,\n\n{self.state['response_draft']}\n\nBest regards,\nGhaznix Support Agent"
self.state["step"] = "COMPLETE"
self.state["log"].append("Customer email drafted successfully. Workflow complete.")
5. Confiabilidade de produção e proteções de segurança
A implantação de sistemas autônomos requer uma mudança na forma como pensamos sobre testes e tratamento de erros. Aqui estão as proteções críticas que você deve incorporar em qualquer sistema de produção:
A. Prevenção de loops de execução descontrolados
Um agente autônomo que encontra um erro ou um caso extremo pode consultar a mesma ferramenta repetidamente, gastando milhares de dólares em custos de API em questão de minutos.
- Solução: Implemente limites máximos de execução. Sempre defina um limite máximo para o número de etapas ou total de tokens de modelo permitidos por instância de fluxo de trabalho (por exemplo, máximo de 10 iterações).
B. Validação do Esquema Estrutural
LLMs são probabilísticos e não garantem naturalmente resultados estruturados como JSON válido ou esquemas correspondentes.
- Solução: Use bibliotecas de validação como Pydantic, Instructor ou Outlines para impor estrutura no nível de inferência. Se um modelo gerar esquemas inválidos, rejeite-o antecipadamente e solicite ao modelo com o erro de análise que se corrija (parte do loop Evaluator-Optimizer).
C. Execução de código em sandbox
Se o seu agente escreve e executa código (como análise de dados ou transformações de banco de dados), executá-lo diretamente no servidor de aplicativos é uma grande vulnerabilidade de segurança.
- Solução: Use ambientes micro-VM seguros e efêmeros (como contêineres Docker, gVisor ou tempos de execução WASM) para executar scripts gerados pelo usuário ou pelo agente com segurança.
Conclusão
A construção de fluxos de trabalho de IA autônomos com LLMs exige preencher a lacuna entre o raciocínio flexível de IA e a disciplina de engenharia estruturada. Ao substituir agentes abertos por fluxos de trabalho direcionados a máquinas de estado, estruturar tarefas por meio de padrões como Orchestrator-Workers e envolver tudo em execução rigorosa e grades de segurança, os desenvolvedores podem construir sistemas altamente inteligentes e prontos para empresas.
O futuro da arquitetura de software não consiste em substituir código por prompts; trata-se de orquestrar agentes e sistemas determinísticos para criar fluxos de trabalho que operem de forma autônoma, aprendam dinamicamente e forneçam resultados confiáveis.