LLMs کے ساتھ خود مختار AI ورک فلو کی تعمیر

بڑے لینگویج ماڈلز (LLMs) نے تبدیل کر دیا ہے کہ ہم ٹیکنالوجی کے ساتھ کس طرح تعامل کرتے ہیں، سادہ گفتگو کے چیٹ بوٹس سے پیچیدہ، کثیر قدمی کارروائیوں کو چلانے کے قابل استدلال انجنوں کی طرف تیزی سے آگے بڑھتے ہیں۔ اگرچہ ایک فوری جوابی تعامل طاقتور ہو سکتا ہے، لیکن انٹرپرائز سیٹنگز میں تخلیقی AI کی اصل قدر خودکار AI ورک فلوز میں ہے۔
ہر قدم کو ترتیب دینے کے لیے انسانی آپریٹرز پر انحصار کرنے کے بجائے، خود مختار ورک فلو LLMs کو مرکزی فیصلہ سازوں کے طور پر استعمال کرتے ہیں جو طویل عرصے کے دوران منصوبہ بندی، عمل درآمد، تشخیص اور خود درست کاموں کو انجام دیتے ہیں۔
یہ گہرا غوطہ دریافت کرتا ہے کہ جدید ڈیزائن کے نمونوں، ریاستی مشینوں، اور مضبوط گارڈ ریلز کا استعمال کرتے ہوئے قابل اعتماد خود مختار AI ورک فلو کو کیسے معمار، تعمیر، اور تعینات کیا جائے۔
1. ایجنٹ کی شفٹ: چیٹ بوٹس بمقابلہ ورک فلوز
LLM ایپلی کیشنز کے ارتقاء کو خود مختاری کی چار مختلف سطحوں میں درجہ بندی کیا جا سکتا ہے:
| سطح | تمثیل | انسانی کردار | بنیادی میکانزم |
|---|---|---|---|
| سطح 1 | بات چیت کی بات چیت | اعلی (ہر موڑ کا اشارہ کرتا ہے) | اسٹیٹ لیس سنگل ٹرن تکمیلات |
| سطح 2 | ٹول کالنگ / فنکشن کالنگ | میڈیم (سیاق و سباق فراہم کرتا ہے) | ماڈل کال کرنے کے لیے API کا انتخاب کرتا ہے۔ نتیجہ واپس کرتا ہے |
| سطح 3 | ہدایت شدہ ورک فلو | کم (اہداف اور گراف کی وضاحت کرتا ہے) | ایل ایل ایم روٹنگ کے ساتھ ہارڈ کوڈ شدہ اسٹیٹ مشین |
| سطح 4 | مکمل طور پر خود مختار ایجنٹس | کم سے کم (مقصد/بجٹ کی وضاحت کرتا ہے) | LLM سے چلنے والی منصوبہ بندی، عمل درآمد، اور عکاسی کے لوپس |
جبکہ لیول 4 کے ایجنٹ انتہائی لچکدار ہوتے ہیں، لیکن پیداواری ماحول میں ان کی پیش گوئی کرنا انتہائی مشکل ہے۔ اس لیے، زیادہ تر انٹرپرائز آرکیٹیکچرز سطح 3: ڈائریکٹڈ ورک فلوز پر بنائے گئے ہیں، جو سافٹ ویئر اسٹیٹ مشینوں کی ڈیٹرمنسٹک ریلیبلٹی کو LLMs کے متحرک استدلال کے ساتھ ملاتے ہیں۔
2. خود مختار ورک فلو کے بنیادی ستون
ایک خود مختار ورک فلو بنانے کے لیے، آپ کو چار بنیادی اجزاء کو یکجا کرنے کی ضرورت ہے:
A. استدلال اور منصوبہ بندی
ورک فلو کے مرکز میں منصوبہ بندی کا نمونہ ہے۔ ایک بولی LLM کال حتمی جواب کو فوری طور پر آؤٹ پٹ کرنے کی کوشش کرتی ہے، جو اکثر استدلال کی ناکامی کا باعث بنتی ہے۔ خود مختار ورک فلو خصوصی پلاننگ لوپس کا استعمال کرتے ہیں:
- ری ایکٹ (وجہ + ایکٹ): ماڈل بار بار سوچتا ہے، عمل کرتا ہے (ایک ٹول کہتا ہے)، اور نتیجہ کا مشاہدہ کرتا ہے، اس لوپ کو اس وقت تک دہراتا ہے جب تک کہ مقصد حاصل نہ ہوجائے۔ خیال کا سلسلہ (CoT): ماڈل کو مجبور کرنا کہ وہ کسی نتیجے پر پہنچنے سے پہلے قدم بہ قدم استدلال پیش کرے۔ ** خیالات کا درخت (ToT): متعدد متبادل راستوں کو بنانا اور ان کا جائزہ لینا، مختلف شاخوں پر نظر رکھنا، اور جب کوئی راستہ ناکام ہوجاتا ہے تو پیچھے ہٹنا۔
B. قلیل مدتی اور طویل مدتی یادداشت
ایک خود مختار نظام کو ایک سے زیادہ عملدرآمد کے چکروں میں ریاست کو برقرار رکھنا چاہیے:
- شارٹ ٹرم میموری: تھریڈ سیاق و سباق، ریاستی متغیرات، اور عمل کاری کے لاگز جو اس بات پر نظر رکھتے ہیں کہ ورک فلو فی الحال کیا کر رہا ہے۔
- طویل مدتی یادداشت: ویکٹر ڈیٹا بیس اور سیمنٹک بازیافت کے نظام جو ورک فلو کو تاریخی رنز، صارف کی ترجیحات، اور انٹرپرائز دستاویزات کو یاد کرنے کی اجازت دیتے ہیں۔
C. ٹولز اور ویب انٹیگریشن
جسمانی یا ڈیجیٹل دنیا پر عمل کرنے کے لیے، LLMs کو بیرونی خدمات کے ساتھ انٹرفیس کرنا چاہیے۔ ماڈل کو ڈیٹا بیس ڈرائیورز، فائل سسٹم، ویب براؤزرز، اور تھرڈ پارٹی APIs تک رسائی کی ضرورت ہے۔ جدید ورک فلو تیزی سے ماڈل سیاق و سباق پروٹوکول (MCP) کو اپنا رہے ہیں، یہ معیاری بناتے ہوئے کہ LLM کس طرح سیاق و سباق سے متعلق ڈیٹا کے ذرائع اور ایگزیکیوشن سینڈ باکسز کو دریافت اور محفوظ طریقے سے مربوط کرتے ہیں۔
3. کلیدی آرکیٹیکچرل ڈیزائن پیٹرن
پیچیدہ ایجنٹی نظام بناتے وقت، سافٹ ویئر انجینئر پیچیدگی کو منظم کرنے اور پیشین گوئی کو برقرار رکھنے کے لیے ثابت شدہ ڈیزائن کے نمونوں کے سیٹ پر انحصار کرتے ہیں:
پیٹرن 1: راؤٹر پیٹرن
ایک راؤٹر آنے والے ان پٹس کو پڑھتا ہے اور فیصلہ کرتا ہے کہ کون سے خصوصی ایل ایل ایم پرامپٹ، ڈیٹا بیس، یا API ہینڈلر کو اگلی کارروائی کرنی چاہیے۔ یہ ایک واحد، یک سنگی LLM پرامپٹ کو بہت زیادہ ہدایات کے ساتھ اوورلوڈ ہونے سے روکتا ہے۔
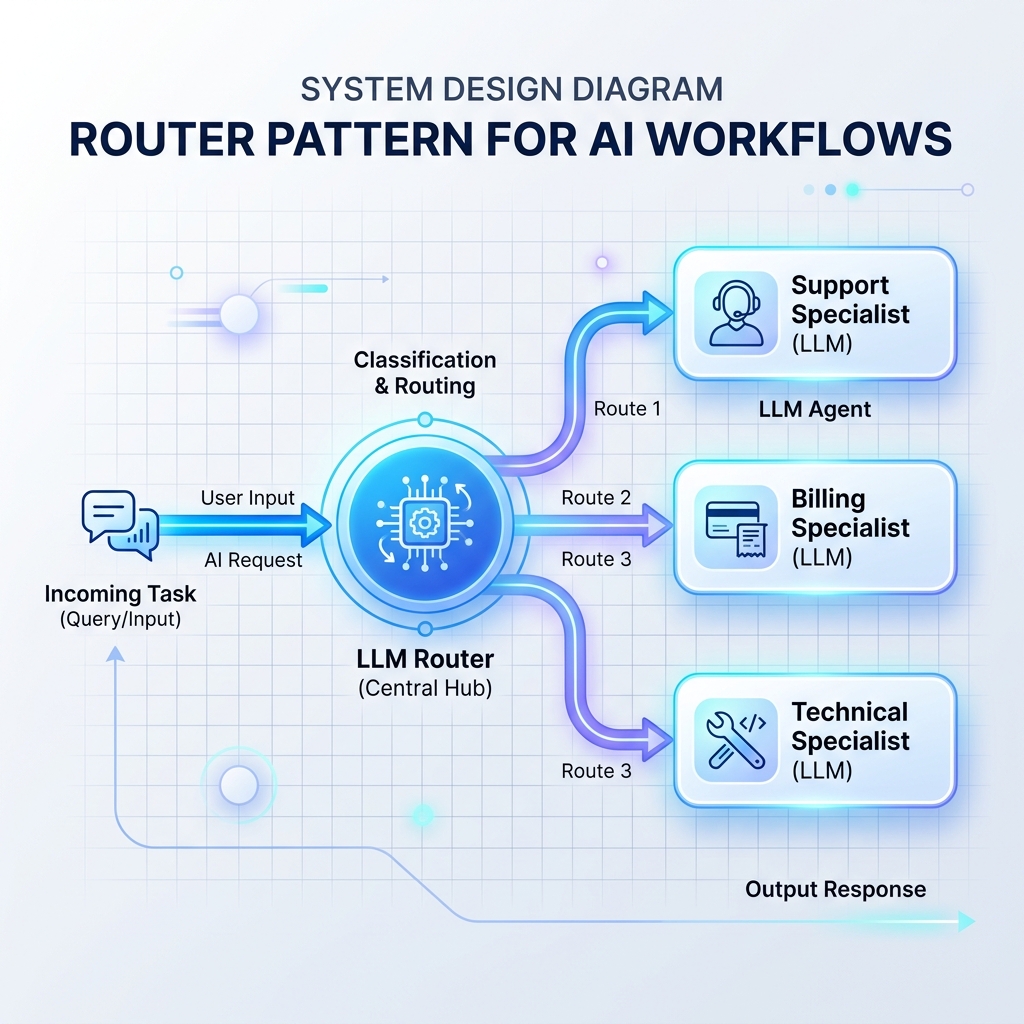
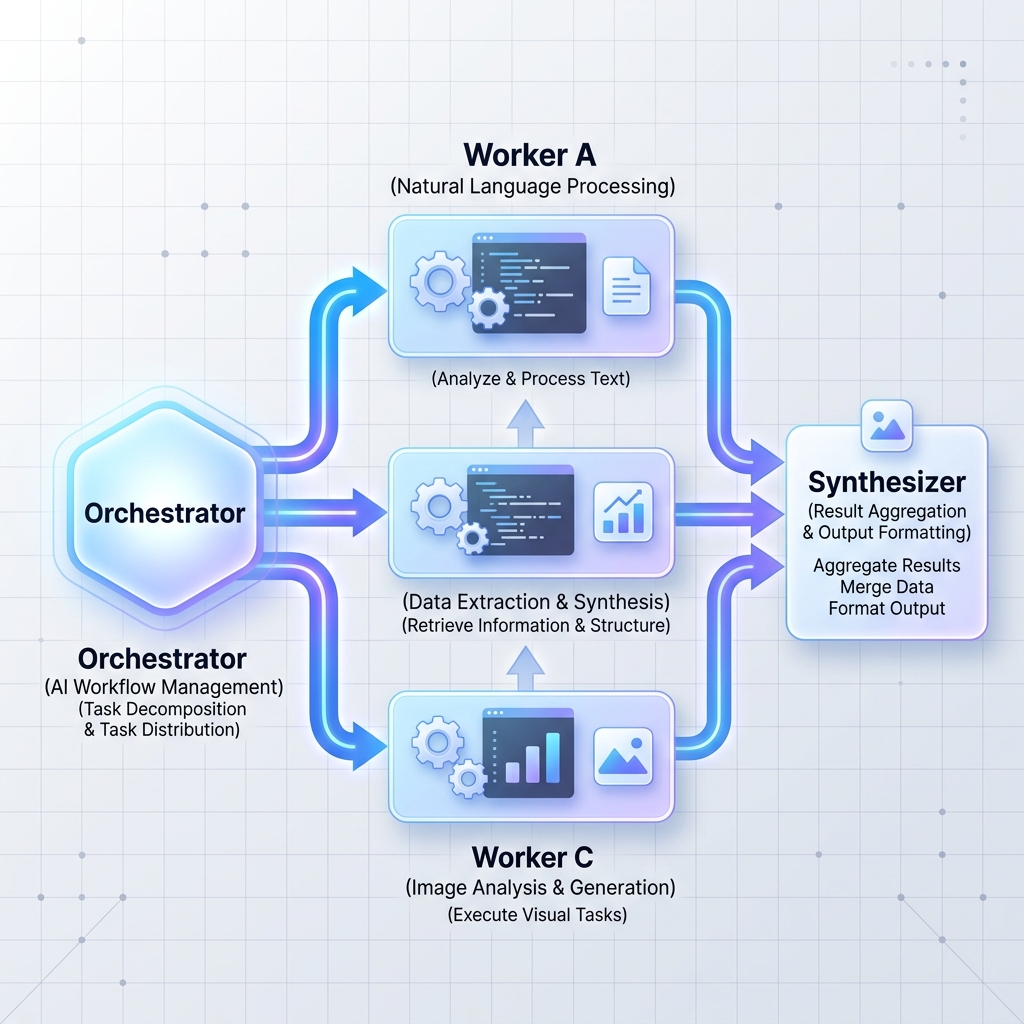
پیٹرن 2: آرکیسٹریٹر- ورکرز
ایک مرکزی آرکیسٹریٹر LLM ایک بڑے، پیچیدہ کام کو آزاد ذیلی کاموں میں تقسیم کرتا ہے۔ اس کے بعد یہ ان کاموں کو ورکر نوڈس (جو خصوصی ایل ایل ایم یا معیاری مائیکرو سروسز ہو سکتے ہیں) کے سپرد کرتا ہے اور نتائج کی ترکیب کرتا ہے۔
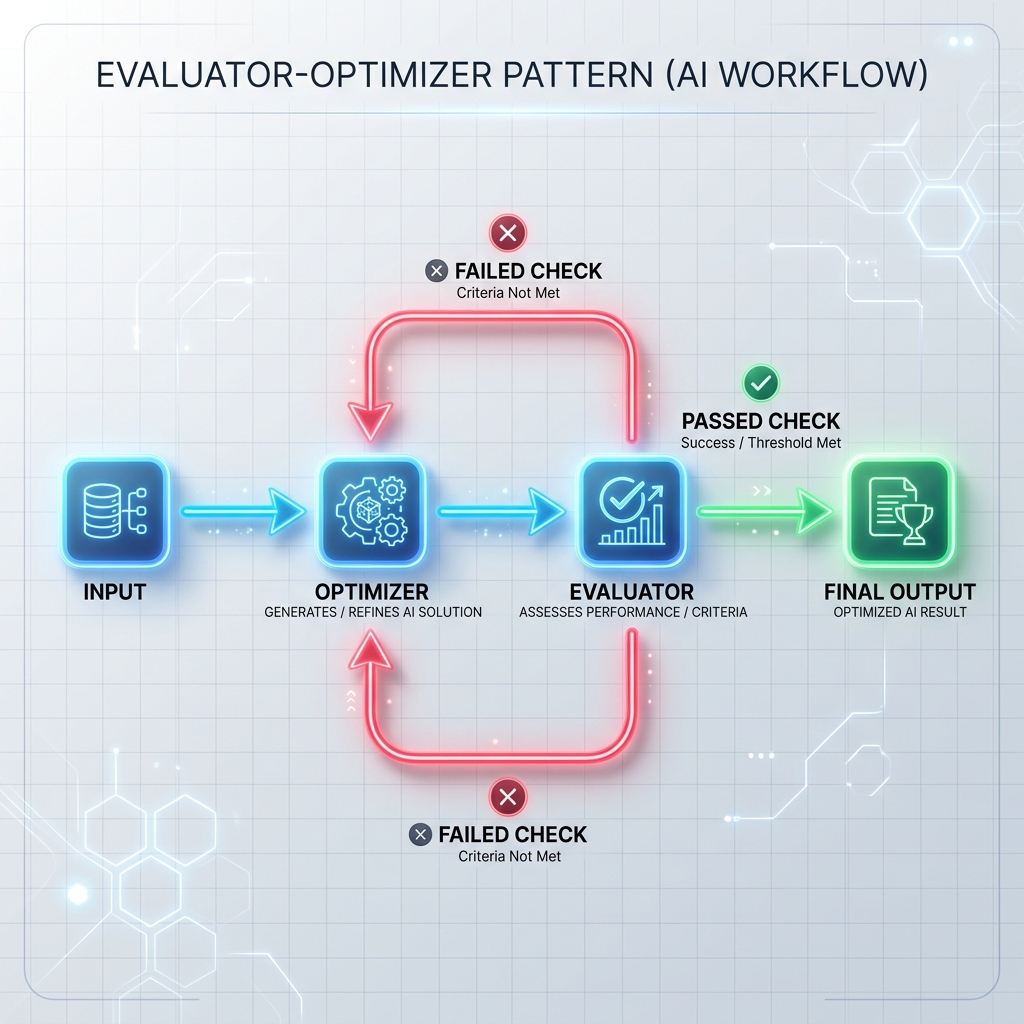
پیٹرن 3: Evaluator-optimizer لوپ
اصلاح کنندہ ایک مسودہ جواب تیار کرتا ہے یا کسی کام کو انجام دیتا ہے، اور جائزہ لینے والا اسے رسمی معیارات (جیسے یونٹ ٹیسٹ، سیکیورٹی اسکینرز، یا الگ تشخیصی پرامپٹ) کے خلاف چیک کرتا ہے۔ اگر چیک ناکام ہو جاتا ہے تو جواب کو دوبارہ تخلیق کرنے کے لیے فیڈ بیک آپٹیمائزر کو واپس بھیج دیا جاتا ہے۔
4. ازگر میں اسٹیٹ بیسڈ ایجنٹ بنانا
آئیے ایک سادہ ریاستی مشین کا استعمال کرتے ہوئے ایک خود مختار ایجنٹ کے ٹھوس نفاذ کو دیکھیں۔ ہم ایک ایسے ایجنٹ کی وضاحت کریں گے جو رقم کی واپسی کی درخواستوں پر کارروائی کرتا ہے۔ ایجنٹ گاہک کی خریداری کی تاریخ کو چیک کرتا ہے، پالیسیوں کے خلاف درخواست کی توثیق کرتا ہے، ای میل کے جواب کا مسودہ تیار کرتا ہے، اور اگر رقم کی واپسی $100 سے زیادہ ہو تو انسانی منظوری کی درخواست کرتا ہے۔
import json
from typing import Dict, Any
# Mock databases and tools
PURCHASE_DB = {
"user_123": {"item": "Premium Subscription", "price": 149.00, "days_ago": 12},
"user_456": {"item": "Basic License", "price": 49.00, "days_ago": 45}
}
class AutonomousRefundAgent:
def __init__(self):
self.state: Dict[str, Any] = {
"step": "INIT",
"user_id": None,
"refund_amount": 0.0,
"policy_passed": False,
"requires_approval": False,
"approved": False,
"response_draft": "",
"log": []
}
def run(self, user_id: str, request_text: str):
self.state["user_id"] = user_id
self.state["log"].append(f"Started workflow for user {user_id} with request: '{request_text}'")
while self.state["step"] != "COMPLETE":
current_step = self.state["step"]
if current_step == "INIT":
self._fetch_user_data()
elif current_step == "VALIDATE_POLICY":
self._validate_policy()
elif current_step == "CHECK_APPROVAL":
self._check_approval_requirements()
elif current_step == "WAITING_FOR_HUMAN":
# Pause execution and yield control back to the orchestrator
self.state["log"].append("Execution paused: waiting for human operator approval.")
break
elif current_step == "EXECUTE_REFUND":
self._execute_refund()
elif current_step == "DRAFT_RESPONSE":
self._draft_response()
return self.state
def _fetch_user_data(self):
user_id = self.state["user_id"]
purchase = PURCHASE_DB.get(user_id)
if not purchase:
self.state["response_draft"] = "No purchase history found for this user."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Fetch failed: User not found in database.")
return
self.state["refund_amount"] = purchase["price"]
self.state["purchase_age_days"] = purchase["days_ago"]
self.state["step"] = "VALIDATE_POLICY"
self.state["log"].append(f"Fetched purchase data: {purchase}")
def _validate_policy(self):
# Business rule: Refunds only allowed within 30 days
age = self.state["purchase_age_days"]
if age <= 30:
self.state["policy_passed"] = True
self.state["step"] = "CHECK_APPROVAL"
self.state["log"].append("Policy validation passed (within 30-day window).")
else:
self.state["policy_passed"] = False
self.state["response_draft"] = "Sorry, our policy only allows refunds within 30 days of purchase."
self.state["step"] = "DRAFT_RESPONSE"
self.state["log"].append("Policy validation failed: Purchase older than 30 days.")
def _check_approval_requirements(self):
# Business rule: Refunds over $100 require human review
amount = self.state["refund_amount"]
if amount > 100.0:
self.state["requires_approval"] = True
self.state["step"] = "WAITING_FOR_HUMAN"
self.state["log"].append(f"Refund of ${amount} exceeds limit. Moving to human approval state.")
else:
self.state["requires_approval"] = False
self.state["step"] = "EXECUTE_REFUND"
self.state["log"].append(f"Refund of ${amount} is within limits. Proceeding to execution.")
def resume_with_human_decision(self, approved: bool):
if self.state["step"] != "WAITING_FOR_HUMAN":
raise ValueError("Agent is not currently waiting for approval.")
self.state["approved"] = approved
self.state["log"].append(f"Human manager decision received: Approved = {approved}")
if approved:
self.state["step"] = "EXECUTE_REFUND"
else:
self.state["response_draft"] = "Your refund request has been reviewed and declined by a customer service manager."
self.state["step"] = "DRAFT_RESPONSE"
# Resume the workflow loop
return self.run(self.state["user_id"], "")
def _execute_refund(self):
amount = self.state["refund_amount"]
# Trigger actual external API call/Stripe integration here
self.state["log"].append(f"Successfully processed stripe refund for ${amount}.")
self.state["response_draft"] = f"Your refund request for ${amount} has been successfully processed."
self.state["step"] = "DRAFT_RESPONSE"
def _draft_response(self):
# Prompt LLM to draft a polite, personalized message incorporating response_draft
self.state["final_message"] = f"Dear Customer,\n\n{self.state['response_draft']}\n\nBest regards,\nGhaznix Support Agent"
self.state["step"] = "COMPLETE"
self.state["log"].append("Customer email drafted successfully. Workflow complete.")
5. پروڈکشن ریلائیبلٹی اور سیکیورٹی گارڈریلز
خود مختار نظاموں کی تعیناتی کے لیے اس تبدیلی کی ضرورت ہوتی ہے کہ ہم جانچ اور غلطی سے نمٹنے کے بارے میں کیسے سوچتے ہیں۔ یہاں اہم گٹرل ہیں جو آپ کو کسی بھی پروڈکشن سسٹم میں بنانا ضروری ہیں:
A. بھگوڑے پھانسی کے لوپس کو روکنا
ایک خودمختار ایجنٹ جو کسی غلطی یا ایج کیس کا سامنا کرتا ہے وہ ایک ہی ٹول کو بار بار پوچھ سکتا ہے، چند منٹوں میں API کے اخراجات میں ہزاروں ڈالر خرچ کر سکتا ہے۔
- حل: عملدرآمد کی زیادہ سے زیادہ حدوں کو نافذ کریں۔ فی ورک فلو مثال کے طور پر اجازت یافتہ قدموں یا کل ماڈل ٹوکنز کی تعداد پر ہمیشہ سخت حد متعین کریں (مثلاً، زیادہ سے زیادہ 10 تکرار)۔
B. ساختی اسکیما کی توثیق
LLMs امکانات ہیں اور قدرتی طور پر درست JSON یا مماثل اسکیموں جیسے ساختی آؤٹ پٹ کی ضمانت نہیں دیتے ہیں۔
- حل: توثیق کی لائبریریوں کا استعمال کریں جیسے Pydantic، انسٹرکٹر، یا آؤٹ لائنز کو اندازہ کی سطح پر نافذ کرنے کے لیے۔ اگر کوئی ماڈل غلط اسکیموں کو آؤٹ پٹ کرتا ہے، تو اسے جلد مسترد کریں اور تجزیہ کی غلطی کے ساتھ ماڈل کو خود کو ٹھیک کرنے کا اشارہ کریں (Evaluator-Optimizer لوپ کا حصہ)۔
C. سینڈ باکس کوڈ کا نفاذ
اگر آپ کا ایجنٹ کوڈ لکھتا اور چلاتا ہے (جیسے ڈیٹا کا تجزیہ یا ڈیٹا بیس کی تبدیلیاں)، تو اسے براہ راست آپ کے ایپلیکیشن سرور پر چلانا سیکیورٹی کا ایک بڑا خطرہ ہے۔
- حل: صارف کے ذریعے تیار کردہ یا ایجنٹ سے تیار کردہ اسکرپٹس کو محفوظ طریقے سے چلانے کے لیے محفوظ، عارضی مائیکرو-VM ماحول (جیسے Docker کنٹینرز، gVisor، یا WASM رن ٹائمز) کا استعمال کریں۔
نتیجہ
LLMs کے ساتھ خود مختار AI ورک فلو بنانے کے لیے لچکدار AI استدلال اور ساختی انجینئرنگ ڈسپلن کے درمیان فرق کو ختم کرنے کی ضرورت ہے۔ کھلے عام ایجنٹوں کو اسٹیٹ مشین ڈائریکٹڈ ورک فلو سے بدل کر، آرکیسٹریٹر-ورکرز جیسے پیٹرن کے ذریعے کاموں کی ساخت، اور ہر چیز کو سختی سے عملدرآمد اور حفاظتی پہرے میں سمیٹ کر، ڈویلپرز ایسے سسٹم بنا سکتے ہیں جو انتہائی ذہین اور انٹرپرائز کے لیے تیار ہوں۔
سافٹ ویئر آرکیٹیکچر کا مستقبل کوڈ کو پرامپٹ سے تبدیل کرنے کے بارے میں نہیں ہے — یہ آرکیسٹریٹنگ ایجنٹس اور ڈیٹرمنسٹک سسٹمز کے بارے میں ہے تاکہ ورک فلو کو بنایا جا سکے جو خود مختار طور پر کام کرتے ہیں، متحرک طور پر سیکھتے ہیں، اور قابل اعتماد طریقے سے نتائج فراہم کرتے ہیں۔