Reconhecimento de Entidades Nomeadas (NER): Do NLP Clássico à Extração baseada em IA
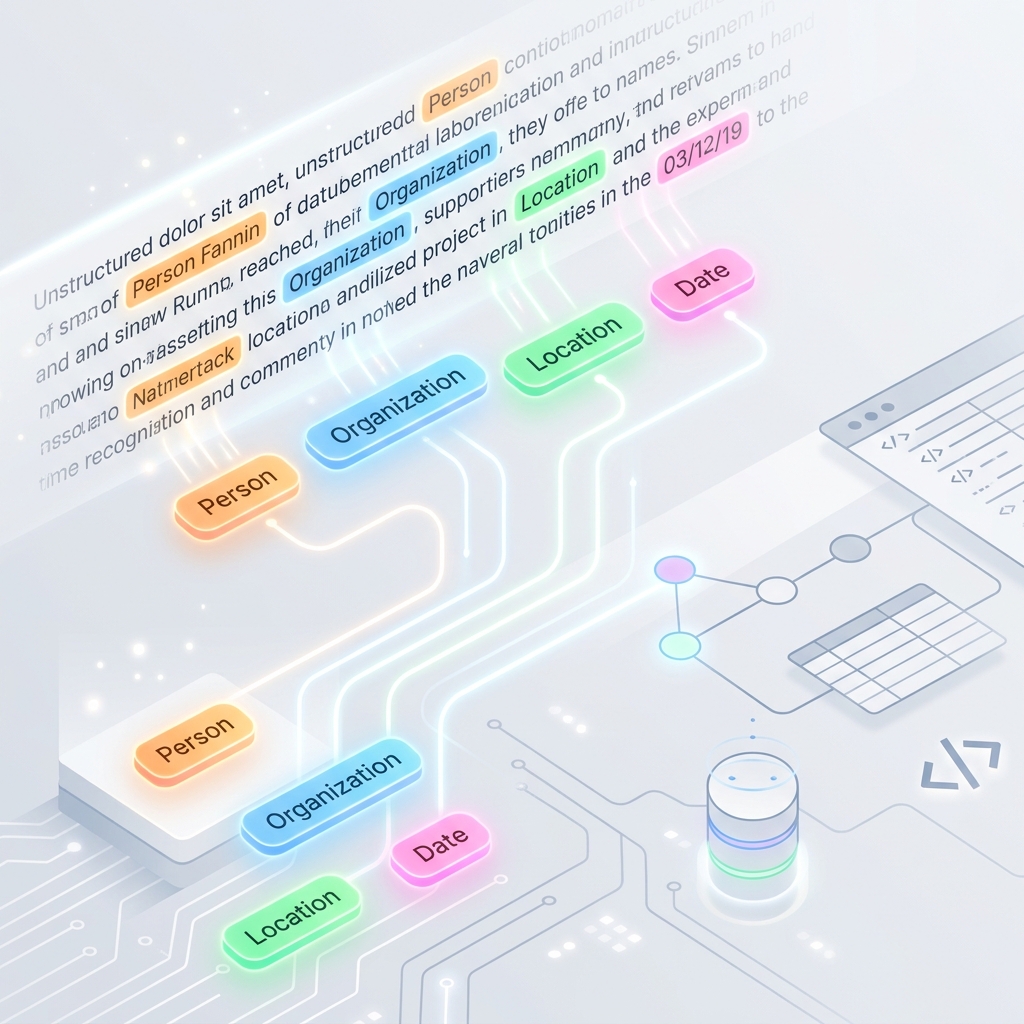
O Reconhecimento de Entidades Nomeadas (NER, na sigla em inglês) é um dos pilares do Processamento de Linguagem Natural (NLP). Trata-se do processo de identificar e classificar automaticamente elementos-chave em textos não estruturados em categorias predefinidas — tais como nomes de pessoas, organizações, localizações, datas, valores monetários e nomes de produtos.
Sem o NER, os motores de busca, os sistemas de recomendação e os softwares de análise automatizada de documentos teriam grande dificuldade para compreender quem, o quê, onde e quando dentro de um texto.
Aqui está um guia completo para entender o NER, como essa tecnologia evoluiu e por que a IA generativa moderna transformou completamente a extração de entidades.
1. A Evolução das Técnicas de NER
Para entender por que o NER baseado em IA é tão revolucionário, precisamos analisar como a extração de entidades evoluiu ao longo das últimas décadas.
Fase 1: Sistemas Baseados em Regras e Dicionários
O NER primitivo dependia de expressões regulares (regex) e dicionários com curadoria (gazetteers).
- Como funcionava: Se uma palavra constava em um banco de dados de localizações ou correspondia a um padrão como
[3 dígitos]-[3 dígitos]-[4 dígitos](número de telefone), ela era extraída. - Limitações: Extremamente frágil. Não conseguia capturar palavras com erros ortográficos, novas entidades ou interpretar contextos. Por exemplo, não conseguia distinguir se “Apple” se referia à fruta ou à empresa de tecnologia.
Fase 2: Aprendizado de Máquina Clássico (CRF e SVM)
Nos anos 2000, os modelos estatísticos de aprendizado de máquina, como Conditional Random Fields (CRFs) e Support Vector Machines (SVMs), tornaram-se o padrão.
- Como funcionava: Os engenheiros projetavam recursos manualmente (ex: prefixos, sufixos, padrões de letras maiúsculas) e treinavam modelos em dados rotulados para prever a probabilidade de um token fazer parte de uma entidade.
- Limitações: Exigia bases de dados rotuladas massivas e uma engenharia manual de recursos extremamente trabalhosa.
Fase 3: Aprendizado Profundo (BiLSTM-CRF e BERT)
Com a ascensão do aprendizado profundo, as redes bi-direcionais de memória de curto e longo prazo (BiLSTM) combinadas com CRFs e, posteriormente, os modelos baseados em Transformers como o BERT, revolucionaram o NLP.
- Como funcionava: Os embeddings de palavras capturavam o significado semântico e as redes neurais profundas compreendiam o contexto. Modelos baseados no BERT conseguiam identificar “Apple” como uma organização na frase “A Apple lançou um novo iPhone” a partir do contexto ao redor.
- Limitações: Ainda exigia ajuste fino (fine-tuning) supervisionado em conjuntos de dados específicos de cada domínio e carecia de flexibilidade para extrair categorias novas e não definidas sem um novo treinamento.
Fase 4: IA Generativa e NER Baseado em LLMs
Hoje, Grandes Modelos de Linguagem (LLMs) como Gemini, GPT-4 e Llama 3 lidam com o NER por meio da compreensão semântica e da capacidade de seguir instruções.
- Como funciona: Usando prompts do tipo Zero-shot ou Few-shot, o usuário pode instruir um LLM a extrair qualquer tipo de entidade arbitrário e retorná-lo em formato estruturado (como JSON).
- Por que vence: Entende sintaxes complexas, lida com erros ortográficos, resolve ambiguidades de contexto e exige zero dados de treinamento inicial.
2. Comparativo: NER baseado em IA vs. NER Clássico
| Característica | NER Clássico (BERT / CRF) | NER baseado em IA (LLMs) |
|---|---|---|
| Dados de Treinamento Exigidos | Alto (Milhares de exemplos rotulados) | Zero a muito baixo (Zero-shot / Few-shot) |
| Flexibilidade | Rígida (Apenas extrai categorias pré-treinadas) | Extremamente alta (Defina qualquer entidade no prompt) |
| Compreensão de Contexto | Moderada (Janela de contexto local) | Profunda (Compreende o contexto global e a intenção do documento) |
| Tratamento de Palavras Fora do Vocabulário (OOV) | Ruim (Dificuldade com palavras novas) | Excelente (Usa raciocínio semântico) |
| Latência de Execução & Custo | Rápido e Barato (Roda localmente em pequenas CPUs/GPUs) | Mais lento e Custo elevado (Requer inferência em modelos grandes) |
3. Principais Aplicações de NER Baseado em IA
O Reconhecimento de Entidades Nomeadas baseado em IA vai além do simples destaque de palavras. Ao converter textos não estruturados em dados estruturados em JSON, ele possibilita automações poderosas:
Processamento de Documentos e Extração de Informações
As empresas processam milhares de faturas, currículos, contratos e propostas (RFPs) diariamente. O NER baseado em IA pode extrair:
- Faturas: CNPJ/CPF, itens de linha, valores totais, endereços de cobrança.
- Currículos: Nomes de candidatos, anos de experiência, competências específicas, universidades.
- Contratos: Datas de rescisão, limites de responsabilidade, leis aplicáveis, nomes dos signatários.
Construção de Grafos de Conhecimento
Ao extrair entidades e as relações entre elas (por exemplo, [Jennifer Lee] -> [trabalha na] -> [Acme Innovations]), o NER baseado em IA funciona como o motor de ingestão básico para Grafos de Conhecimento (Knowledge Graphs), muito utilizados com GraphRAG para buscas corporativas avançadas.
RAG Aprimorado e Marcação de Metadados
Em sistemas de Geração Aumentada de Recuperação (RAG), indexar documentos com metadados (como autor, versão de produto, país e tecnologia) melhora drasticamente a precisão da busca. O NER baseado em IA gera essas tags automaticamente em escala durante a importação de documentos.
NLP Clínico e Médico
Provedores de saúde usam o NER para extrair sintomas de pacientes, dosagens de medicamentos, históricos médicos e diagnósticos de prontuários, enquanto ocultam automaticamente Informações Pessoais de Saúde (PHI) para cumprir as leis de privacidade (como a LGPD).
4. Como o NER Baseado em IA Funciona (O Fluxo de Trabalho)
O NER moderno baseado em IA depende do envio de instruções do sistema e de um esquema estruturado para o LLM.
[Texto Não Estruturado] ──> [LLM + Instruções do Sistema + Esquema JSON] ──> [Saída JSON Estruturada]
- Texto de Entrada: O texto bruto a ser processado.
- Prompt do Sistema e Esquema: Definimos as entidades que desejamos extrair (ex: Nome, Empresa, Data) e o formato de saída (ex: JSON).
- Extração pelo LLM: O modelo realiza a análise semântica, identifica as entidades, resolve ambiguidades e formata o resultado.
- JSON Estruturado: A saída está pronta para ser salva no banco de dados ou enviada a uma API.
5. Exemplo de Implementação: NER baseado em IA em Python
Aqui está um exemplo simples em Python de como realizar o NER baseado em IA usando esquemas de saída JSON estruturados:
import json
from google import genai
from google.genai import types
from pydantic import BaseModel
# Inicializa o cliente Gemini
client = genai.Client()
# Define a estrutura de destino usando Pydantic
class EntityExtraction(BaseModel):
people: list[str]
organizations: list[str]
locations: list[str]
dates: list[str]
text_content = """
Em 14 de março de 2024, Jennifer Lee foi nomeada como a nova VP de Engenharia da
Acme Innovations Inc., localizada em Kyoto, Japão. Ela sucederá David Miller.
"""
# Solicita saída estruturada do Gemini
response = client.models.generate_content(
model='gemini-2.5-flash',
contents=text_content,
config=types.GenerateContentConfig(
system_instruction="Extraia todas as pessoas, organizações, localizações e datas do texto.",
response_mime_type="application/json",
response_schema=EntityExtraction,
),
)
# Analisa e exibe o resultado em JSON limpo
entities = json.loads(response.text)
print(json.dumps(entities, indent=2))
Saída:
{
"people": ["Jennifer Lee", "David Miller"],
"organizations": ["Acme Innovations Inc."],
"locations": ["Kyoto", "Japão"],
"dates": ["14 de março de 2024"]
}
Conclusão
O Reconhecimento de Entidades Nomeadas evoluiu de buscas em dicionários estáticos para uma capacidade semântica dinâmica viabilizada por IA. Hoje, as organizações podem extrair entidades complexas e específicas de seus domínios a partir de documentos desordenados sem qualquer dado de treinamento inicial. Ao integrar o NER baseado em IA nos seus fluxos de trabalho, você pode converter arquivos de texto não estruturados em registros estruturados de bancos de dados, abrindo novos níveis de automação e inteligência de negócios.