नामित इकाई पहचान (NER): क्लासिक NLP से AI-आधारित निष्कर्षण तक
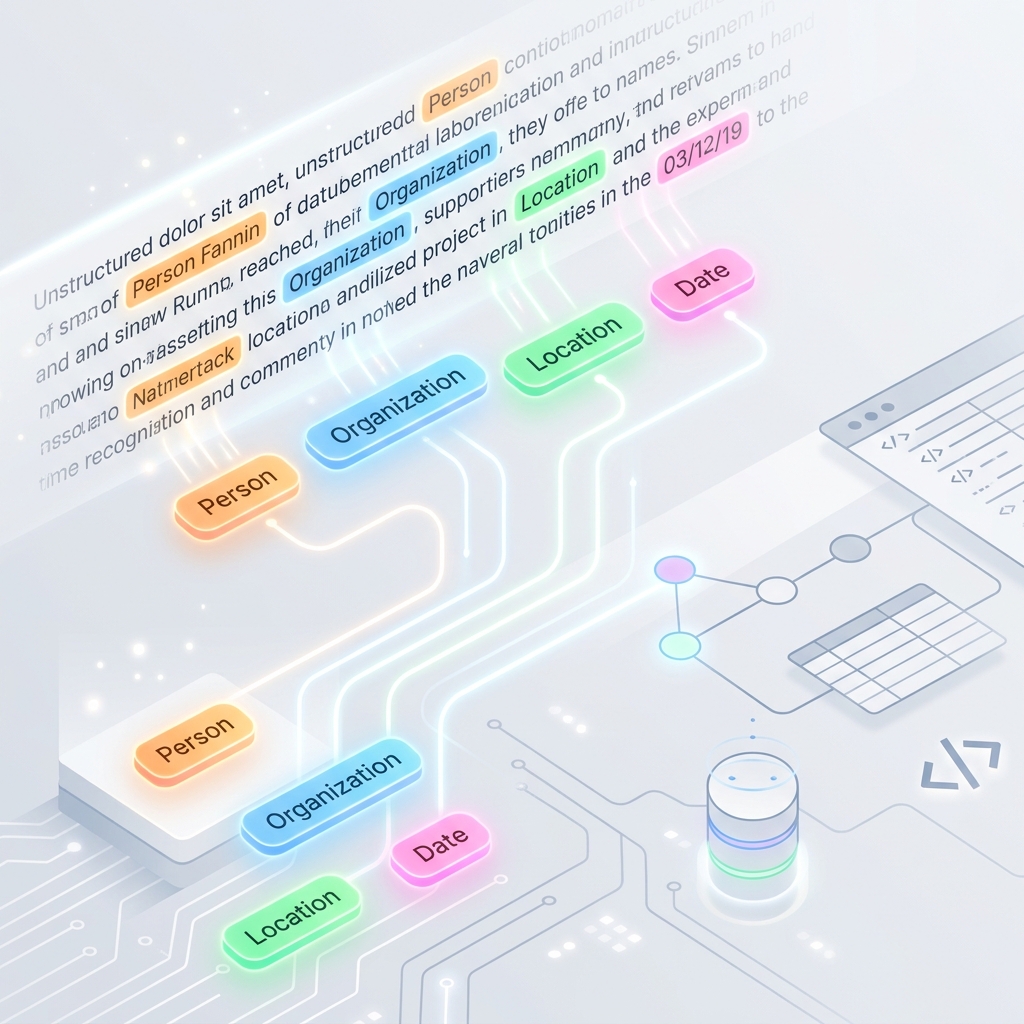
नामित इकाई पहचान (Named Entity Recognition - NER) नेचुरल लैंग्वेज प्रोसेसिंग (NLP) का एक मुख्य स्तंभ है। यह असंरचित (unstructured) टेक्स्ट में से पूर्व-निर्धारित श्रेणियों—जैसे लोगों के नाम, संगठनों, स्थानों, तारीखों, मौद्रिक मूल्यों और उत्पाद के नामों की स्वचालित रूप से पहचान और वर्गीकरण करने की प्रक्रिया है।
NER के बिना, सर्च इंजन, रिकमेंडेशन इंजन और स्वचालित दस्तावेज़ विश्लेषण प्रणालियों को टेक्स्ट के भीतर ‘कौन, क्या, कहाँ और कब’ को समझने में काफी कठिनाई होगी।
यहाँ NER को समझने, इस तकनीक के विकास और आधुनिक जनरेटिव AI ने इकाई निष्कर्षण (entity extraction) को कैसे पूरी तरह बदल दिया है, इस पर एक व्यापक गाइड दी गई है।
1. NER तकनीकों का विकास
AI-आधारित NER इतना क्रांतिकारी क्यों है, इसे समझने के लिए हमें पिछले कुछ दशकों में इकाई निष्कर्षण के विकास पर नज़र डालनी होगी।
चरण 1: नियम-आधारित और शब्दकोश-आधारित प्रणालियाँ
शुरुआती NER रेगुलर एक्सप्रेशन (regex) और क्यूरेटेड शब्दकोशों (gazetteers) पर निर्भर था।
- यह कैसे काम करता था: यदि कोई शब्द स्थानों के डेटाबेस में था, या
[3-अंक]-[3-अंक]-[4-अंक](फ़ोन नंबर) जैसे पैटर्न से मेल खाता था, तो उसे निकाल लिया जाता था। - सीमाएं: बहुत नाजुक। यह गलत वर्तनी वाले शब्दों, नई इकाइयों को पकड़ने या संदर्भ को समझने में असमर्थ था। उदाहरण के लिए, यह अंतर नहीं कर सकता था कि “Apple” फल को संदर्भित कर रहा है या तकनीकी कंपनी को।
चरण 2: क्लासिक मशीन लर्निंग (CRF और SVM)
2000 के दशक में, कंडीशनल रैंडम फील्ड्स (CRF) और सपोर्ट वेक्टर मशीन (SVM) जैसे सांख्यिकीय मशीन लर्निंग मॉडल मानक बन गए।
- यह कैसे काम करता था: इंजीनियरों ने मैन्युअल रूप से विशेषताओं (जैसे उपसर्ग, प्रत्यय, बड़े अक्षरों के पैटर्न) को तैयार किया और टोकन के किसी इकाई का हिस्सा होने की संभावना की भविष्यवाणी करने के लिए लेबल किए गए डेटा पर मॉडल को प्रशिक्षित किया।
- सीमाएं: बड़े लेबल वाले डेटासेट और थकाऊ मैन्युअल विशेषता इंजीनियरिंग की आवश्यकता थी।
चरण 3: डीप लर्निंग (BiLSTM-CRF और BERT)
डीप लर्निंग के उदय के साथ, CRF के साथ युग्मित द्विदिश दीर्घकालिक अल्पकालिक स्मृति (BiLSTM) नेटवर्क और बाद में BERT जैसे ट्रांसफॉर्मर मॉडल ने NLP में क्रांति ला दी।
- यह कैसे काम करता था: वर्ड एम्बेडिंग ने अर्थ संबंधी समझ को कैप्चर किया और गहरे तंत्रिका नेटवर्क (deep neural networks) ने संदर्भ को समझा। BERT-आधारित मॉडल आसपास के संदर्भ के आधार पर “Apple ने एक नया iPhone लॉन्च किया” में “Apple” को एक संगठन के रूप में पहचान सकते थे।
- सीमाएं: अभी भी डोमेन-विशिष्ट डेटासेट पर पर्यवेक्षित फाइन-ट्यूनिंग (fine-tuning) की आवश्यकता थी और पुन: प्रशिक्षण के बिना नई, अपरिभाषित श्रेणियों को निकालने के लचीलेपन की कमी थी।
चरण 4: जनरेटिव AI और LLM-आधारित NER
आज, लार्ज लैंग्वेज मॉडल्स (LLMs) जैसे कि Gemini, GPT-4 और Llama 3 अर्थ संबंधी समझ और निर्देशों का पालन करने की क्षमता का उपयोग करके NER को संभालते हैं।
- यह कैसे काम करता है: ज़ीरो-शॉट (Zero-shot) या फ्यू-शॉट (Few-shot) प्रॉम्प्टिंग का उपयोग करके, एक उपयोगकर्ता LLM को किसी भी मनमाने इकाई प्रकार को निकालने और उसे एक संरचित प्रारूप (जैसे JSON) में वापस करने का निर्देश दे सकता है।
- यह क्यों जीतता है: यह जटिल वाक्य रचना को समझता है, वर्तनी की त्रुटियों को संभालता है, अस्पष्ट संदर्भ के माध्यम से तर्क करता है, और शुरू करने के लिए किसी प्रशिक्षण डेटा की आवश्यकता नहीं होती है।
2. AI-आधारित NER बनाम क्लासिक NER की तुलना
| विशेषता | क्लासिक NER (BERT / CRF) | AI-आधारित NER (LLMs) |
|---|---|---|
| प्रशिक्षण डेटा की आवश्यकता | उच्च (हजारों लेबल वाले उदाहरण) | शून्य से बहुत कम (Zero-shot / Few-shot) |
| लचीलापन | कठोर (केवल पूर्व-प्रशिक्षित श्रेणियों को निकालता है) | अत्यधिक उच्च (प्रॉम्प्ट में किसी भी इकाई को परिभाषित करें) |
| संदर्भ की समझ | मध्यम (स्थानीय संदर्भ विंडो) | गहरी (वैश्विक दस्तावेज़ संदर्भ और इरादे को समझता है) |
| शब्दावली से बाहर (OOV) शब्दों को संभालना | खराब (अनदेखे शब्दों के साथ संघर्ष) | उत्कृष्ट (अर्थ संबंधी तर्क का उपयोग करता है) |
| निष्पादन विलंबता और लागत | तेज़ और सस्ता (छोटे CPU/GPU पर स्थानीय रूप से चलता है) | धीमा और अधिक लागत (बड़े मॉडल निष्कर्ष की आवश्यकता) |
3. AI-आधारित NER के प्रमुख अनुप्रयोग
AI-आधारित नामित इकाई पहचान केवल टेक्स्ट को हाइलाइट करने से कहीं आगे जाती है। असंरचित टेक्स्ट को संरचित, कार्रवाई योग्य JSON डेटा में परिवर्तित करके, यह शक्तिशाली स्वचालन (automation) को सक्षम बनाता है:
दस्तावेज़ विश्लेषण और सूचना निष्कर्षण
उद्यम दैनिक आधार पर हजारों चालान (invoices), बायोडाटा (resumes), अनुबंधों और प्रस्तावों के अनुरोधों (RFPs) को संसाधित करते हैं। AI-आधारित NER निकाल सकता है:
- चालान: टैक्स आईडी, लाइन आइटम, कुल राशि, बिलिंग पते।
- बायोडाटा: उम्मीदवार के नाम, अनुभव के वर्ष, विशिष्ट कौशल, विश्वविद्यालय।
- अनुबंध: समाप्ति की तारीखें, देयता सीमाएं, शासी कानून, हस्ताक्षरकर्ता के नाम।
ज्ञान ग्राफ (Knowledge Graph) निर्माण
इकाइयों और उनके बीच के संबंधों (जैसे, [Jennifer Lee] -> [काम करती है] -> [Acme Innovations]) को निकालकर, AI-आधारित NER ज्ञान ग्राफ के लिए मूलभूत अंतर्ग्रहण इंजन के रूप में कार्य करता है, जिसे उन्नत उद्यम खोज के लिए तेजी से GraphRAG के साथ जोड़ा जा रहा है।
उन्नत RAG और मेटाडेटा टैगिंग
रिट्रीवल-ऑगमेंटेड जनरेशन (RAG) प्रणालियों में, मेटाडेटा टैग (जैसे लेखक, उत्पाद संस्करण, देश और तकनीक) के साथ दस्तावेज़ों को अनुक्रमित (indexing) करने से पुनर्प्राप्ति सटीकता में काफी सुधार होता है। AI-आधारित NER दस्तावेज़ अंतर्ग्रहण के दौरान बड़े पैमाने पर इन टैगों को स्वचालित रूप से उत्पन्न करता है।
नैदानिक और चिकित्सा NLP
स्वास्थ्य सेवा प्रदाता गोपनीयता नियमों का अनुपालन करने के लिए व्यक्तिगत स्वास्थ्य जानकारी (PHI) को स्वचालित रूप से संशोधित करते हुए डॉक्टर के नोट्स से रोगी के लक्षणों, दवा की खुराक, चिकित्सा इतिहास और निदान को निकालने के लिए NER का उपयोग करते हैं।
4. AI-आधारित NER कैसे काम करता है (कार्यप्रवाह)
आधुनिक AI-आधारित NER संरचित आउटपुट को लागू करने के लिए एक सिस्टम निर्देश और एक लक्ष्य स्कीमा के साथ LLM को प्रॉम्प्ट करने पर निर्भर करता है।
[असंरचित टेक्स्ट] ──> [LLM + सिस्टम निर्देश + JSON स्कीमा] ──> [संरचित JSON आउटपुट]
- इनपुट टेक्स्ट: संसाधित किया जाने वाला कच्चा टेक्स्ट।
- सिस्टम प्रॉम्प्ट और स्कीमा: हम उन इकाइयों को परिभाषित करते हैं जिन्हें हम निकालना चाहते हैं (जैसे नाम, कंपनी, तारीख) और सटीक प्रारूप जिसकी हमें आवश्यकता है (जैसे JSON)।
- LLM निष्कर्षण: मॉडल अर्थ संबंधी विश्लेषण करता है, इकाइयों की पहचान करता है, अस्पष्टता को हल करता है और आउटपुट को प्रारूपित करता है।
- संरचित JSON: आउटपुट सीधे डेटाबेस में संग्रहीत होने या API को पास होने के लिए तैयार है।
5. कार्यान्वयन उदाहरण: पायथन में AI-आधारित NER
यहाँ संरचित JSON आउटपुट स्कीमा का उपयोग करके AI-आधारित NER करने का एक सरल पायथन उदाहरण दिया गया है:
import json
from google import genai
from google.genai import types
from pydantic import BaseModel
# जेमिनी क्लाइंट को इनिशियलाइज़ करें
client = genai.Client()
# Pydantic का उपयोग करके लक्ष्य संरचना को परिभाषित करें
class EntityExtraction(BaseModel):
people: list[str]
organizations: list[str]
locations: list[str]
dates: list[str]
text_content = """
14 मार्च, 2024 को, जेनिफर ली को क्योटो, जापान में स्थित
Acme Innovations Inc. में इंजीनियरिंग के नए वीपी के रूप में नियुक्त किया गया था। वह डेविड मिलर का स्थान लेंगी।
"""
# जेमिनी से संरचित आउटपुट का अनुरोध करें
response = client.models.generate_content(
model='gemini-2.5-flash',
contents=text_content,
config=types.GenerateContentConfig(
system_instruction="पाठ से सभी लोगों, संगठनों, स्थानों और तारीखों को निकालें।",
response_mime_type="application/json",
response_schema=EntityExtraction,
),
)
# स्वच्छ JSON परिणाम को पार्स करें और प्रिंट करें
entities = json.loads(response.text)
print(json.dumps(entities, indent=2))
आउटपुट:
{
"people": ["Jennifer Lee", "David Miller"],
"organizations": ["Acme Innovations Inc."],
"locations": ["Kyoto", "Japan"],
"dates": ["March 14, 2024"]
}
निष्कर्ष
नामित इकाई पहचान स्थिर शब्दकोश लुकअप से विकसित होकर AI द्वारा संचालित एक गतिशील, अर्थ संबंधी क्षमता बन गई है। आज, संगठन बिना किसी प्रशिक्षण डेटा के अस्त-व्यस्त दस्तावेज़ों से जटिल डोमेन-विशिष्ट इकाइयों को निकाल सकते हैं। अपने कार्यप्रवाहों में AI-आधारित NER को एकीकृत करके, आप असंरचित टेक्स्ट फ़ाइलों को संरचित डेटाबेस प्रविष्टियों में बदल सकते हैं, जिससे स्वचालन और व्यावसायिक बुद्धिमत्ता के नए स्तर अनलॉक हो सकते हैं।